Command Palette
Search for a command to run...
JaisおよびJais-chat: アラビア語中心のファウンデーションモデルおよび指示微調整済みオープン生成大規模言語モデル
JaisおよびJais-chat: アラビア語中心のファウンデーションモデルおよび指示微調整済みオープン生成大規模言語モデル
ワンクリックで Qwen 72B Chat Int4 Gradio デモをデプロイ
概要
タイトル:なし
抄録:我々は、アラビア語中核の最先端ファウンデーションモデルおよび指示微調整済みオープン生成大規模言語モデル(LLM)であるJaisおよびJais-chatを新たに導入する。これらのモデルはGPT-3のデコーダ専用アーキテクチャに基づいており、様々なプログラミング言語のソースコードを含む、アラビア語と英語のテキストの混合データセットで事前学習されている。130億パラメータを有するこれらのモデルは、広範な評価に基づき、既存のオープンなアラビア語および多言語モデルと比較して、アラビア語における知識と推論能力において大幅に優れている。さらに、英語データ量がはるかに少ないにもかかわらず、同規模の英語中核型オープンモデルと比較して英語においても競争力のある性能を示す。我々は、これらのモデルの学習、微調整、安全性アライメント、および評価の詳細な記述を提供する。アラビア語LLMに関する研究の促進を目的として、ファウンデーションモデルであるJaisと、指示微調整済みバリアントであるJais-chatの2つのオープン版モデルを公開する。
One-sentence Summary
the paper introduce Jais and Jais-chat, 13-billion-parameter open Arabic-centric foundation and instruction-tuned large language models built on a GPT-3 decoder-only architecture and pretrained on a mixture of Arabic and English texts that includes source code, which outperform existing open models in Arabic knowledge and reasoning while remaining competitive in English despite less training data, and are released to promote research on Arabic LLMs.
Key Contributions
- The paper introduces Jais and Jais-chat, two 13-billion-parameter generative language models based on a GPT-3 decoder-only architecture and pretrained on a mixture of Arabic, English, and source code in various programming languages.
- The work details a comprehensive instruction-tuning and safety alignment process alongside a custom evaluation pipeline that adapts English-centric benchmarks using human translations and an in-house machine translation system for rigorous Arabic assessment.
- Extensive evaluations demonstrate that the models achieve state-of-the-art knowledge and reasoning capabilities in Arabic while remaining competitive with English-centric open models of similar size, despite being trained on a substantially smaller proportion of English data.
Introduction
Large language models have transformed natural language processing, yet the field remains heavily skewed toward English despite Arabic being spoken by over 400 million people worldwide. Prior open-source models either focus exclusively on English or dilute Arabic performance by cramming it into massively multilingual architectures with limited training data. The authors leverage a strategic bilingual pretraining approach to overcome these data scarcity and linguistic imbalance challenges. They introduce Jais and Jais-chat, 13B-parameter generative models built on a curated mix of Arabic and English text alongside programming code. By implementing a specialized Arabic text processing pipeline, optimizing the bilingual data ratio, and applying rigorous instruction tuning with safety guardrails, they deliver the first openly available Arabic-centric LLMs that outperform existing multilingual alternatives while maintaining strong English reasoning capabilities.
Dataset
Dataset Composition and Sources
- The authors construct a multilingual pretraining corpus totaling approximately 395 billion tokens, combining Arabic, English, and programming code.
- Arabic data originates from over ten public and in-house sources, including news archives, web crawls, Wikipedia, books, UN transcripts, and specialized regional corpora.
- English and code data primarily derive from The Pile, an aggregation of 22 high-quality datasets covering web pages, academic papers, legal documents, code repositories, and domain-specific texts.
Subset Details and Sizing
- Arabic: Begins with 55 billion native tokens, augmented by 18 billion machine-translated tokens from English Wikipedia and Books3. The combined set is upsampled by 1.6 times to yield 116 billion tokens.
- English: Comprises 232 billion tokens sampled from The Pile, including 46 billion from the GitHub subset. Key components include Pile-CC, Books3, ArXiv, PubMed, Wikipedia, FreeLaw, Project Gutenberg, and YouTube subtitles.
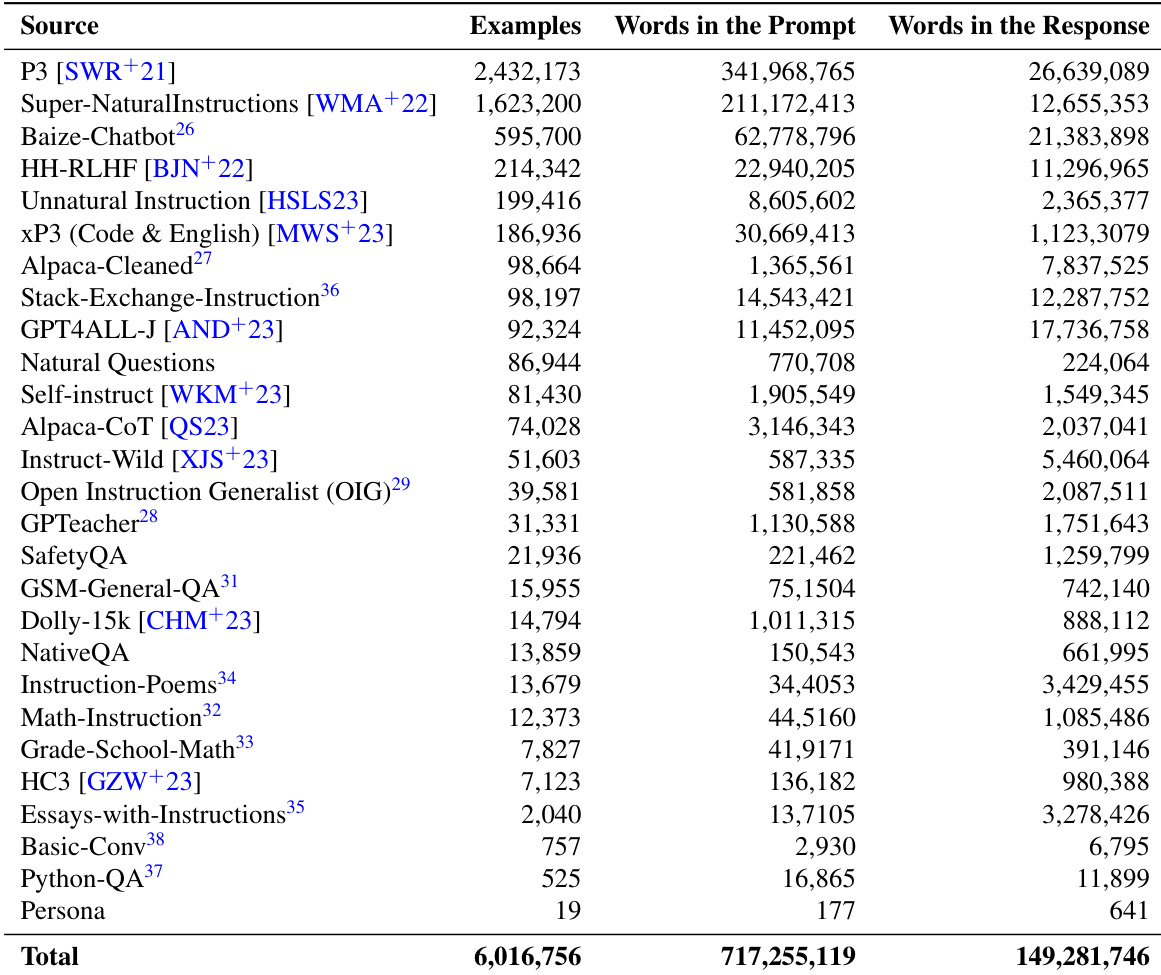
- Instruction-Tuning: Contains 10 million prompt-response pairs split by language, with 6 million in English and 4 million in Arabic. English subsets feature curated samples from Super-NaturalInstructions, P3, xP3, Natural Questions, and various chatbot and code datasets. Arabic subsets include translated English instructions, native named entity recognition tasks, and region-specific QA pairs.
Usage in Training and Mixture Ratios
- The pretraining mix follows a fixed 1:2:0.4 ratio for Arabic, English, and code respectively, a configuration determined through extensive ablation studies on smaller models.
- The authors train the base model on the full pretraining corpus before applying instruction-tuning on the 10 million pair dataset to align the model for conversational and assistant tasks.
- Downstream evaluation relies on zero-shot benchmarks across knowledge, reasoning, bias, and safety metrics, utilizing the LM-Evaluation-Harness framework and manually translated datasets such as MMLU and LiteratureQA.
Processing, Filtering, and Other Details
- All raw inputs undergo initial detokenization to standardize document boundaries, treating each article or web page as a single unit.
- The authors apply strict filtering rules that remove extremely short or long documents, texts with insufficient Arabic character density, and entries containing words longer than 100 characters to eliminate URLs and noise.
- Normalization steps strip non-printable Unicode, rare diacritics, embedded HTML and JavaScript, and high-frequency boilerplate phrases. A lightweight n-gram language model further filters noisy sequences.
- Fuzzy deduplication via locality-sensitive hashing reduces the English corpus by roughly 20 percent. Arabic filtering is intentionally less aggressive to preserve scarce linguistic data.
- Safety alignment incorporates translated refusal datasets, native region-specific QA, and external classifiers fine-tuned on OSACT4 to detect and block hate speech or offensive content before generation.
Method
The authors leverage a transformer-based architecture for Jais, adopting a causal decoder-only design similar to GPT-2 and LLaMA. This architecture forms the foundation for the model's generative capabilities, with enhancements derived from recent advancements and empirical findings. The model's framework is built upon a series of key components designed to optimize performance, particularly in multilingual and instruction-based tasks.
The Jais tokenizer, a critical component, is a custom subword tokenizer trained using byte-pair encoding (BPE) on a balanced corpus of English and Arabic text. This design choice addresses the over-segmentation issues commonly observed with the GPT-2 tokenizer, especially for Arabic words, thereby improving cross-lingual alignment and reducing computational overhead. The tokenizer's effectiveness is demonstrated by its high fertility score, indicating strong performance across multiple language types despite a smaller vocabulary size. 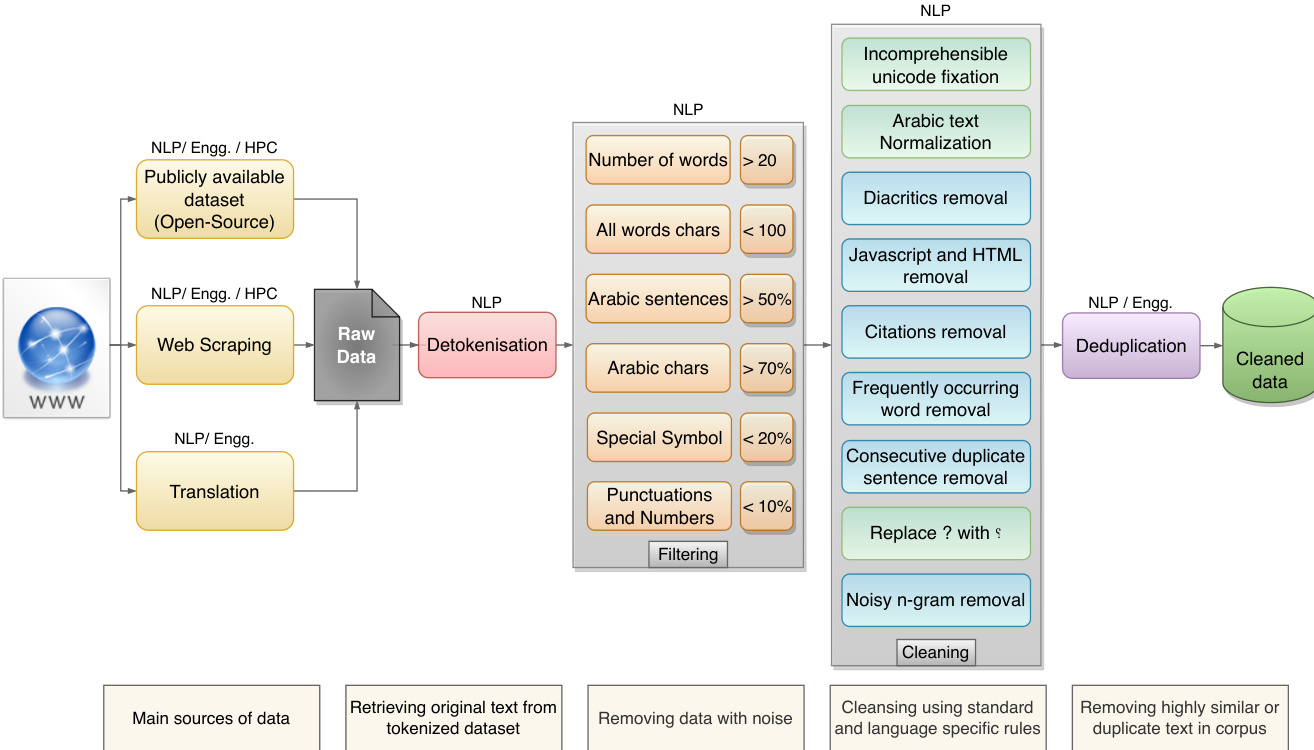
Positional information is incorporated via Attention with Linear Biases (ALiBi), which applies a linear penalty to attention scores based on the distance between query and key positions. This method enables efficient extrapolation to longer contexts, overcoming limitations of conventional learnable or sinusoidal positional embeddings that degrade with extended sequence lengths. 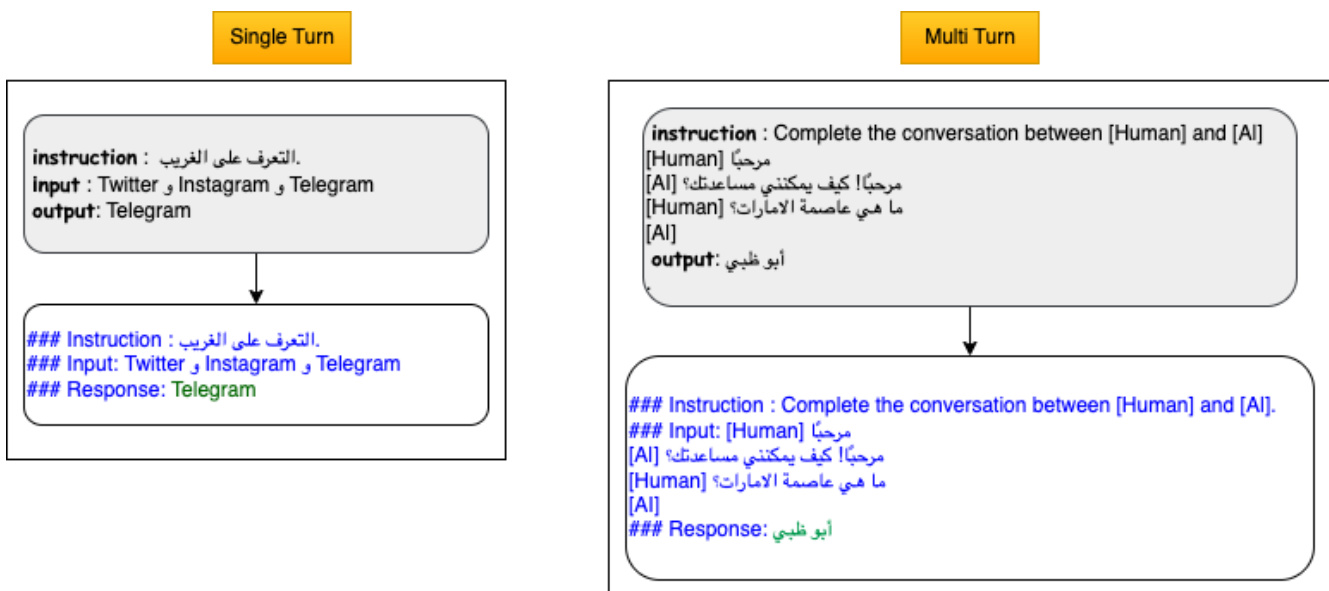
Within each transformer block, the SwiGLU activation function is employed, combining the benefits of Swish and Gated Linear Units. This activation enhances model performance while managing computational cost; to maintain a consistent FLOP budget relative to GeLU, the feed-forward network's filter size is adjusted to 38×dmodel instead of the standard 4×dmodel. The model's hyperparameters are optimized using maximal update parametrization (μP), allowing the transfer of optimal batch size and learning rate values from a smaller 40M-parameter model to the 13B-parameter model, thereby streamlining the hyperparameter search process.
For instruction-tuning, the model is adapted to support dialogue-style interactions by training on a dataset of instruction-response pairs. Each instance is structured within a template that includes special markers to delineate the human input and the expected model response, with the loss masked over the prompt tokens to ensure the model focuses on generating the response. This setup supports both single-turn and multi-turn conversational formats, as illustrated in the template design. The instruction-tuned variant, referred to as Jais-chat, is further refined with safety measures, including the use of a system prompt that instructs the model to behave responsibly and a keyword-based filtering mechanism that detects and blocks potentially offensive content using regular expressions.
Experiment
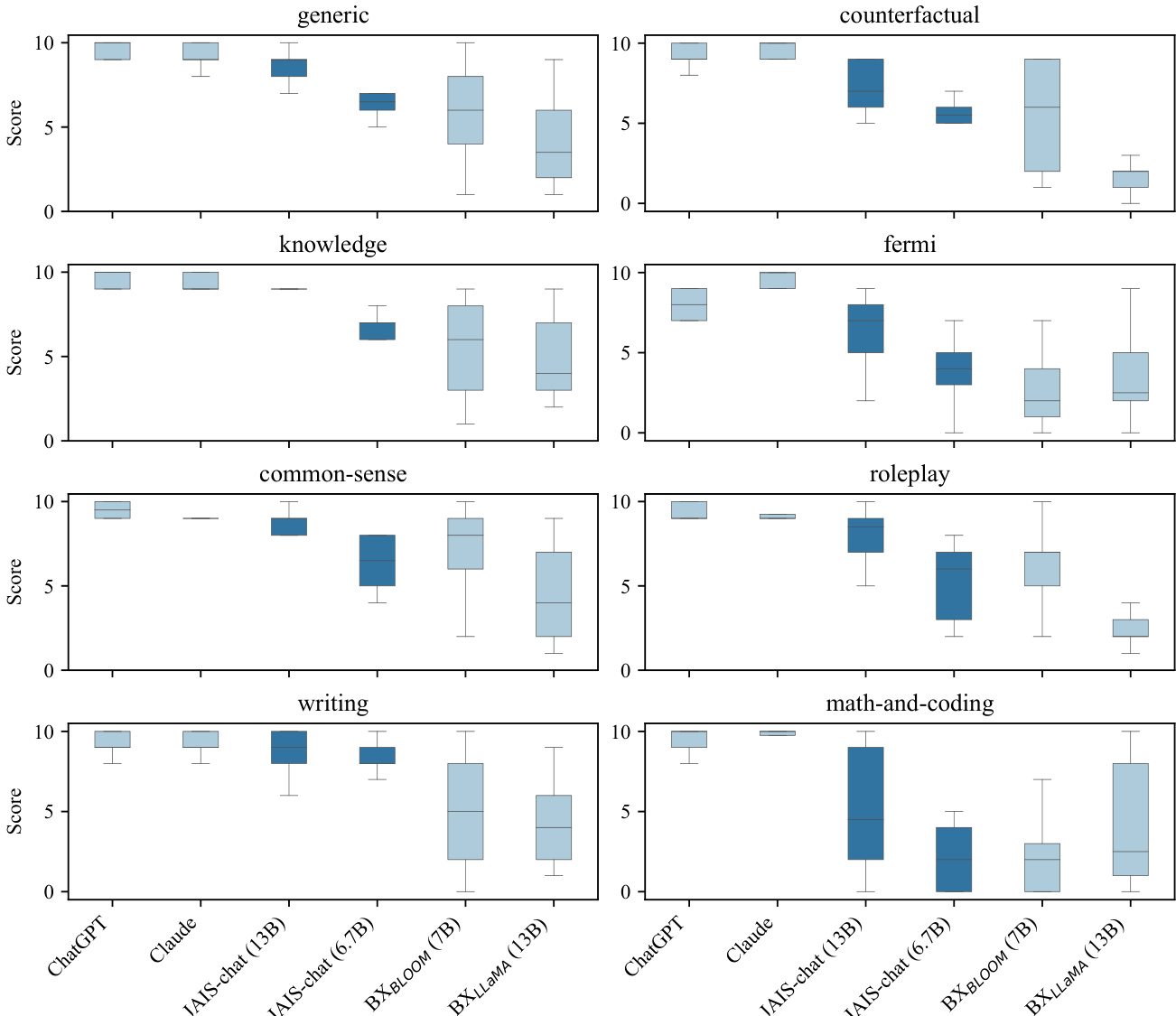
Preliminary training experiments across varying model capacities and Arabic-English data ratios validated that cross-lingual transfer significantly benefits larger architectures, with a mid-sized model using a mixed dataset outperforming a substantially larger Arabic-only counterpart. Subsequent generation evaluations compared instruction-tuned variants against leading proprietary and open-source baselines using automated pairwise assessments on Arabic prompts. The results demonstrate that the optimized model achieves highly competitive text generation, particularly excelling in common-sense, knowledge, and writing tasks while showing expected limitations in complex reasoning and coding. Ultimately, these findings confirm that strategic data mixing and targeted fine-tuning enable a regionally focused system to deliver robust performance comparable to far larger proprietary models.
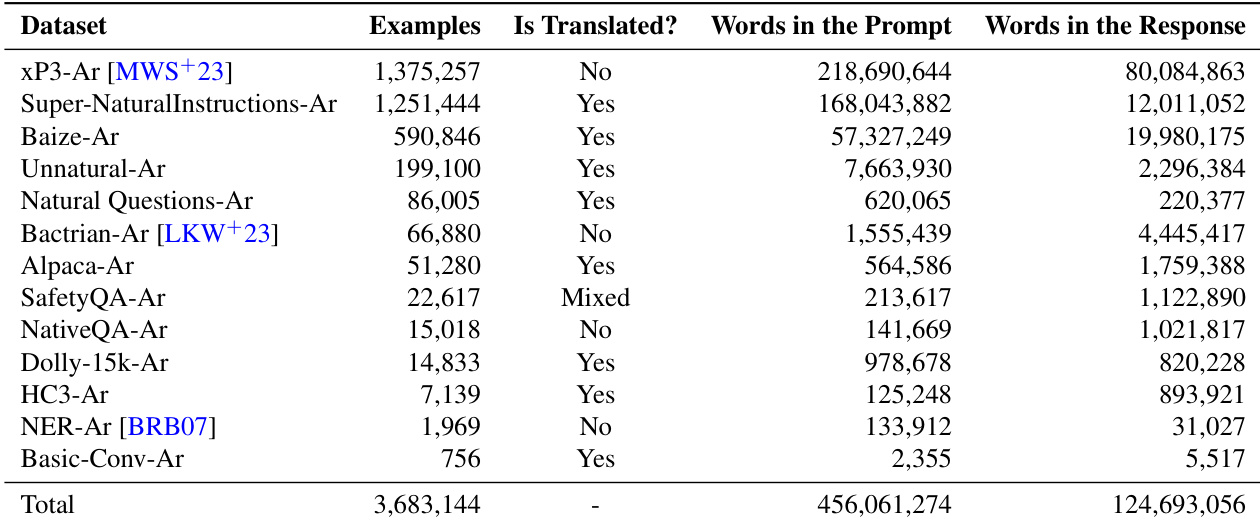
The authors present a the the table summarizing datasets used for evaluation, detailing the number of examples, whether the content was translated, and the word counts in prompts and responses. The datasets vary in size and origin, with some being Arabic-specific and others multilingual, and the the the table highlights differences in data characteristics such as translation status and word usage. The dataset the the table includes a mix of Arabic-specific and multilingual datasets with varying sizes and translation statuses. Some datasets are large-scale with over 1 million examples, while others are smaller, with a few thousand or fewer examples. The number of words in prompts and responses varies significantly across datasets, with some having very high word counts in both categories.
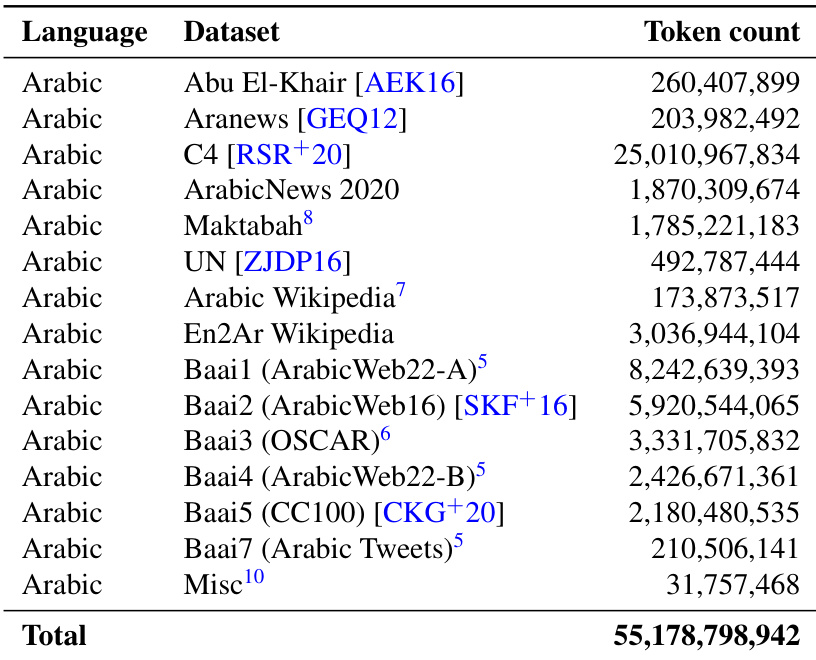
The authors present a the the table detailing the composition of the Arabic training data used for the Jais model, listing multiple datasets by language and token count. The data is drawn from a variety of sources including news, web text, and social media, with the total token count significantly dominated by a single large dataset. Results show that for larger model sizes, incorporating English data improves performance on Arabic tasks, while for smaller models, it has an adverse effect. The training data for the Arabic model is composed of multiple sources including news, web, and social media, with one dataset contributing the majority of the total tokens. The performance of the model on Arabic tasks improves with the inclusion of English data for larger models, but this trend is reversed for smaller models. The model's performance on Arabic tasks is significantly influenced by the size of the model and the mix of training data, with larger models showing better cross-lingual transfer.
The authors evaluate the performance of Jais-chat models against several open- and closed-source models on Arabic text generation tasks across various categories. Results show that Jais-chat performs competitively in some areas, particularly in writing and common-sense tasks, but is outperformed by larger models in reasoning-intensive categories such as math and coding. The evaluation highlights that model size and instruction-tuning significantly affect performance, with Jais-chat showing strong results in specific domains despite being smaller than top-performing models. Jais-chat performs competitively with larger models in writing and common-sense tasks, achieving scores close to those of leading models. Jais-chat is outperformed by larger models in reasoning-intensive categories such as math and coding, where scores are notably lower. Instruction-tuned models like Jais-chat achieve higher performance compared to non-instruction-tuned models across most task categories.
{"summary": "The authors present a the the table summarizing the sources used for training and evaluation, detailing the number of examples and word counts in both prompts and responses across various datasets. The the the table highlights the scale and diversity of the data, with some sources contributing significantly more examples and words than others, particularly in the context of instruction-following and general language tasks.", "highlights": ["The the the table lists multiple datasets used for training and evaluation, with varying numbers of examples and word counts in prompts and responses.", "Some datasets, such as Super-NaturalInstructions and HH-RLHF, contribute a large number of examples and words, indicating their significant role in the training process.", "The total counts across all datasets show substantial contributions in terms of both examples and words, reflecting a comprehensive and diverse data collection effort."]
The authors compare the vocabulary size and performance metrics of Jais with other language models, including GPT-2 and BLOOM, across English, Arabic, and code tasks. Results show that Jais achieves competitive performance in English and Arabic while maintaining a relatively small vocabulary size. The model demonstrates strong performance in Arabic tasks, with scores close to or surpassing those of larger models in specific domains. Jais achieves competitive performance in English and Arabic despite having a smaller vocabulary size compared to models like BLOOM. Jais outperforms GPT-2 and BERT Arabic in Arabic tasks, indicating strong language modeling capabilities for Arabic. The model shows balanced performance across English, Arabic, and code tasks, highlighting its versatility in multilingual and code-related applications.
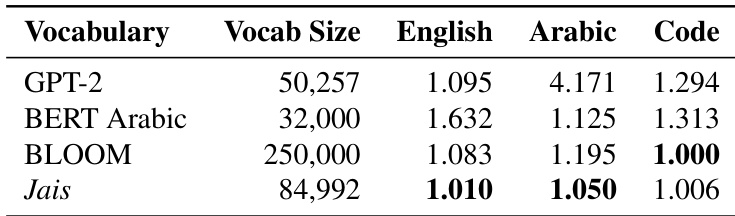
The experiments benchmark Jais and Jais-chat models against diverse Arabic and multilingual datasets to validate the effects of training data composition, model scale, and instruction tuning. The analysis demonstrates that larger architectures gain substantial Arabic performance benefits from English data inclusion, while smaller models suffer from the same mix, emphasizing the necessity of scale-aware data curation. Comparative evaluations further reveal that instruction-tuned models excel in writing and common-sense generation but remain outperformed by larger systems in complex reasoning and coding domains. Additionally, the study confirms that Jais delivers competitive multilingual and code capabilities with a notably compact vocabulary, proving that high efficiency does not require expansive parameter counts.