Command Palette
Search for a command to run...
臨床および生医学的タスクに適用されたインストラクション微調整済み大規模言語モデルのゼロショットおよびフューショット研究
臨床および生医学的タスクに適用されたインストラクション微調整済み大規模言語モデルのゼロショットおよびフューショット研究
Yanis Labrak Mickael Rouvier Richard Dufour
大規模言語モデル、プロンプトプログラミング、および Few-shot タスク
概要
タイトル:なし
抄録:大規模言語モデル(LLM)の最近の台頭は、自然言語処理(NLP)分野において顕著な進展を可能にした。これらの新しいモデルは様々なタスクで優れたパフォーマンスを示しているものの、対応可能なタスクの多様性および適用領域の観点から、その応用と潜在能力はまだ十分に探求されていない。この文脈において、本稿では、名前付きエンティティ認識(NER)、質問応答(QA)、関係抽出(RE)などを含む13の英語による実世界の臨床・生医学的NLPタスクにおいて、4つの最先端のインストラクションチューニング済みLLM(ChatGPT、Flan-T5 UL2、Tk-Instruct、Alpaca)を評価する。我々の総合的な結果は、これらの評価対象となったLLMが、特にQAタスクにおいて顕著なパフォーマンスを発揮しつつ、これらのタスクの例を一度も経験していないにもかかわらず、ゼロショットおよびフューショットシナリオにおいて、大半のタスクで最先端モデルのパフォーマンスに迫ることを示している。しかし、我々はまた、分類タスクおよびREタスクが、PubMedBERTのような医療分野用に特別に設計されたモデルで達成可能なパフォーマンスに達していないことも観察する。最後に、我々は、すべての研究対象タスクにおいて単一のLLMが他を凌駕しておらず、あるモデルは他のモデルよりも特定のタスクにより適していることが示されていることに留意する。
One-sentence Summary
Evaluating four instruction-tuned large language models (ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca) across thirteen English clinical and biomedical NLP tasks reveals that while these models approach state-of-the-art zero- and few-shot performance, particularly in question answering, they underperform domain-specific architectures like PubMedBERT in classification and relation extraction and demonstrate that no single model outperforms all others across the evaluated tasks.
Key Contributions
- This study evaluates four instruction-tuned large language models (ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca) across thirteen clinical and biomedical natural language processing tasks under zero- and few-shot conditions.
- A novel Recursive Chain-of-Thought (RCoT) prompting strategy is introduced to sequentially enrich input instructions, enabling named-entity recognition across diverse model architectures.
- Empirical analysis demonstrates that general-purpose models achieve competitive performance on most biomedical tasks, though they underperform domain-specialized architectures like PubMedBERT in classification and relation extraction while exhibiting distinct task-specific capabilities.
Introduction
The medical domain increasingly relies on natural language processing to analyze complex clinical records, yet deploying advanced models in healthcare remains difficult due to scarce, sensitive datasets and the high cost of expert annotation. Traditional masked language models require extensive labeled data and struggle with cross-task generalization, while prior evaluations of large language models in medicine have been limited to narrow task sets and non-standard automatic metrics. The authors address these gaps by benchmarking four instruction-tuned models across thirteen real-world clinical and biomedical tasks. They evaluate zero- and few-shot capabilities against a fine-tuned PubMedBERT baseline using standard accuracy and F1 scores. Furthermore, the authors introduce Recursive Chain-of-Thought prompting, a novel technique that sequentially enriches prompts to mimic human reasoning and enable named entity recognition across diverse large language model architectures.
Dataset
Dataset Composition and Sources
- The authors use five scientific and medical NLP datasets: MedMCQA, GAD, SciTail, HoC, and DEFT-2020. These sources span multiple-choice question answering, relation extraction, natural language inference, cancer hallmark classification, and semantic textual similarity.
Key Details for Each Subset
- MedMCQA provides science questions with four lettered options requiring single-character answers.
- GAD contains statements for gene-disease relation extraction, classified as positive or negative.
- SciTail offers premise-hypothesis pairs for natural language inference, labeled as entails or neutral.
- HoC documents are annotated with one or more of ten predefined cancer hallmarks or marked as none.
- DEFT-2020 Task 1 functions as the semantic textual similarity benchmark.
- The provided excerpts do not specify exact dataset sizes or training mixture ratios.
Data Usage and Processing
- The authors convert all subsets into structured instruction prompts for ChatGPT and Flan-T5 UL2.
- Each task is evaluated using both zero-shot and five-shot configurations.
- Raw class labels are manually optimized through trial and error to align with model expectations, such as changing entailment to entails for measurable performance gains.
- Strict output constraints are enforced across all prompts to prohibit justifications and guarantee format compliance.
Metadata and Additional Processing
- The authors inject standardized entity placeholders like @GENEand@DISEASE into the GAD inputs to streamline relation extraction.
- No cropping strategies or complex metadata construction pipelines are detailed in the provided text.
Method
The authors leverage a few-shot learning framework during inference, where a small number of task examples are provided as conditioning without updating the model's weights. These examples typically consist of an instruction, context, and desired completion, such as a premise, hypothesis, and corresponding label for natural language inference (NLI) tasks. The few-shot technique involves presenting the model with k examples of context and completion, followed by a final example of context for which the model must generate the completion. The value of k generally ranges from 3 to 100, constrained by the model’s context window size—Flan-UL2, for instance, supports up to 2,048 tokens.
To enhance few-shot performance beyond randomly selected examples, a retrieval-based module is introduced using Sentence-Transformers (Reimers and Gurevych, 2019). This module retrieves the k most semantically similar examples from the training set. The process begins by embedding each instruction prompt in the training set into a vector space using a fixed PubMedBERT (Gu et al., 2021) model. For a given test instance, the query is compared to all training examples via cosine distance, and the top k closest examples are selected. In the implementation, k is set to 5.
The input instruction prompt is constructed by concatenating three components: an instruction that specifies the task, describes the data, and outlines the expected model behavior; the input argument containing relevant information; and constraints on the output space to guide generation. This structured format improves model performance across diverse tasks.
For named entity recognition (NER), two inference methods are evaluated. The first, adapted from Ye et al. (2023), is applicable only to ChatGPT and uses a format where words are separated by double vertical bars and labels by single vertical bars. The second method, introduced as Recursive Chain-of-Thought (RCoT), is more general and works across all tested generative models. RCoT extends the Chain-of-Thought (CoT) framework (Wei et al., 2022b) and builds upon Wang et al. (2022b). It operates by iteratively processing each token in the sequence, using the current prediction state as input to generate the label for the next token. This ensures that every token receives a label and prevents omissions during generation. However, the method incurs a high computational cost due to its ON complexity, where N is the number of tokens in the sequence, in contrast to the O1 complexity of the ChatGPT-specific method.
An example of the RCoT prompt format includes a detailed instruction, constraints, and a set of five few-shot examples, followed by the current sentence and a query about the label of a specific token. This approach ensures precise entity labeling while maintaining consistency with the model’s reasoning process.
Experiment
The experimental setup evaluates four instruction-tuned large language models against a biomedical baseline across thirteen clinical and natural language processing tasks using zero- and few-shot prompting protocols. This evaluation validates the generalization capacity of generic models in specialized medical domains, revealing that while few-shot learning effectively mitigates hallucinations and boosts overall accuracy, the models still lag behind task-specific architectures in classification and relation extraction. Consequently, the findings conclude that question answering is the most reliable application for current LLMs, and since no single model excels across all tasks, practitioners must carefully match model capabilities to specific clinical requirements.
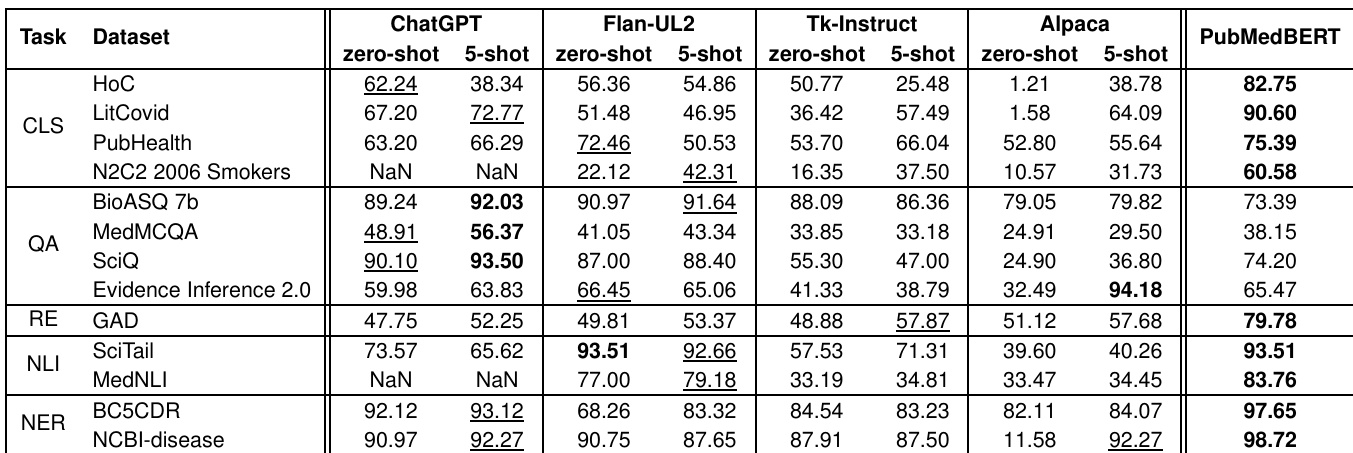
The authors evaluate multiple large language models on a range of clinical and biomedical tasks, including classification, question answering, relation extraction, and named entity recognition. Results indicate that while generative models perform well on question-answering tasks, they fall short on classification and relation extraction compared to domain-specific models, with performance varying significantly across tasks and models. Generative models perform better than domain-specific models on question-answering tasks in zero-shot settings. Classification and relation extraction tasks show inferior performance for generative models compared to specialized models. Performance varies across models, with some excelling in certain tasks while underperforming in others.
The authors evaluate multiple large language models on a range of clinical and biomedical tasks, comparing their performance in zero-shot and few-shot settings against a biomedical-specific model. Results show that generative models perform well on question-answering tasks, particularly in few-shot scenarios, while their performance on classification and relation extraction tasks remains limited compared to specialized models. Generative models achieve strong performance on question-answering tasks, especially in few-shot settings, outperforming specialized models in some cases. Classification and relation extraction tasks show consistently lower performance for generative models compared to the biomedical-specific baseline. Alpaca demonstrates significant improvement in few-shot scenarios across all tasks, indicating high adaptability to new instructions.
The study evaluates multiple large language models across clinical and biomedical tasks, including classification, question answering, and relation extraction, using both zero-shot and few-shot settings against a domain-specific baseline. These experiments validate the comparative effectiveness of generative versus specialized architectures across diverse task types and prompting conditions. Qualitatively, generative models demonstrate strong capabilities in question answering, particularly when leveraging few-shot examples, but consistently lag behind specialized models on classification and relation extraction tasks. Overall, performance proves highly task-dependent, with certain architectures like Alpaca exhibiting notable adaptability and improvement in few-shot scenarios.