Command Palette
Search for a command to run...
ディープ任意多項式カオスニューラルネットワーク:ディープ人工ニューラルネットワークがデータ駆動型均一カオス理論からどのように恩恵を受けるか
ディープ任意多項式カオスニューラルネットワーク:ディープ人工ニューラルネットワークがデータ駆動型均一カオス理論からどのように恩恵を受けるか
Sergey Oladyshkin Timothy Praditia Ilja Kröker Farid Mohammadi Wolfgang Nowak Sebastian Otte
探索的データ分析からディープニューラルネットワークまで [完全チュートリアル]
概要
タイトル:
要旨:人工知能および機械学習は、数学的計算、物理モデリング、計算科学、通信科学、確率解析の様々な分野で広く用いられている。現在、深層人工ニューラルネットワーク(DANN)に基づくアプローチは非常に人気がある。学習タスクに応じて、DANNの正確な形態は、その多層アーキテクチャ、活性化関数、およびいわゆる損失関数によって決定される。しかし、DANNに基づく深層学習アプローチの大多数において、ニューラル信号処理のカーネル構造は同一であり、ノード応答はニューラル活動の線形重ね合わせとして符号化され、非線形性は活性化関数によって引き起こされる。本論文では、多項式カオス展開(PCE)として知られる均一カオス理論の観点から、DANNにおけるニューラル信号処理を分析することを提案する。PCEの観点からは、DANNの各ノードにおける(線形)応答は、前層の単一ニューロンからの1次多変数多項式、すなわち単項式の線形加重和として見なすことができる。この観点から、従来のDANN構造は、ニューラル信号のガウス分布に暗黙的(しかし誤って)依存している。
One-sentence Summary
The Deep Arbitrary Polynomial Chaos Neural Network replaces standard linear activations with data-driven polynomial expansions of previous-layer neurons to model neural signal processing through homogeneous chaos theory, directly addressing the implicit Gaussian assumptions that constrain conventional deep artificial neural networks.
Key Contributions
- The paper introduces deep arbitrary polynomial chaos neural networks (DaPC NN), an architecture that replaces the implicit Gaussian assumptions of conventional deep networks with adaptive, data-driven multivariate orthonormal polynomial bases at each node.
- By reformulating the neural signal processing kernel through homogeneous chaos theory, the framework captures high-order simultaneous neuron interactions and embeds non-linearity directly into the polynomial basis, thereby eliminating the necessity for traditional activation functions.
- Evaluations across three distinct test cases demonstrate stable convergence against reference validation datasets, while systematic comparisons quantify the impact of training data volume on predictive accuracy relative to standard deep neural networks and arbitrary polynomial chaos methods.
Introduction
Deep artificial neural networks have become a cornerstone of modern machine learning for mapping complex multi-dimensional inputs to outputs across scientific and engineering domains. However, standard architectures rely on linear weighted superpositions of neuron outputs followed by manually selected activation functions, which often introduce redundant signal representations and subjective design choices. Traditional polynomial chaos expansions offer a mathematically rigorous alternative by projecting signals onto orthonormal polynomial bases to eliminate redundancy, but their classical form requires known input probability distributions that are unavailable in purely data-driven neural training. To bridge this gap, the authors introduce deep arbitrary polynomial chaos neural networks that adaptively construct data-driven orthonormal polynomial bases at each network layer. This approach replaces rigid linear combinations and fixed activation functions with high-order weighted superpositions, reducing representational redundancy and providing a more robust, theoretically grounded framework for complex modeling tasks.
Dataset
-
Composition and Sources: The authors assemble two distinct datasets to benchmark their surrogate modeling approaches. The first is a synthetic dataset generated from a non-linear analytical function with ten independent uniform inputs ranging from -5 to 5. The second is adapted from a reduced carbon dioxide injection benchmark model in prior literature, simulating multi-phase flow in porous media with strong nonlinear shock propagation.
-
Subset Details and Sizing: Training subsets are fixed in size to ensure experimental transparency and avoid active learning or data mining procedures. For the analytical function, training sets contain 100, 500, and 1,000 samples. For the CO₂ benchmark, training sets are sized at 100, 500, and 1,000 for one sampling strategy, and 27, 216, and 1,331 for another. Validation subsets hold 1,000 samples for the analytical function and 10,000 samples for the CO₂ benchmark.
-
Data Usage and Processing: The authors use these datasets to train adaptive polynomial chaos, deep adaptive neural networks, and deep adaptive polynomial chaos neural networks. Training data is strictly partitioned into fixed sets to isolate model performance from dynamic sampling effects. Validation data is consistently generated through Monte Carlo sampling based on the underlying input distributions to assess prediction quality across key uncertainty sources like injection rate, relative permeability, and formation porosity.
-
Additional Processing Strategies: To prevent numerical instabilities such as the Runge phenomenon and Gibbs effect near discontinuities, the authors employ dedicated point selection strategies rather than random sampling. Training points are constructed using either Sobol sequences or Gaussian integration points. The Gaussian strategy specifically aligns sample placement with polynomial degrees to form full tensor grids, optimizing the numerical integration process for the surrogate models.
Method
The proposed Deep Arbitrary Polynomial Chaos Neural Network (DaPC NN) reimagines the core architecture of conventional Deep Artificial Neural Networks (DANNs) by integrating the principles of polynomial chaos expansion (PCE) theory. The fundamental shift lies in the representation of neural signals within each layer. While conventional DANNs propagate signals through a linear superposition of monomials—specifically zeroth and first-order terms—resulting in a linear weighted sum, the DaPC NN employs a non-linear, high-order multivariate polynomial expansion. This expansion is constructed using a data-driven, orthonormal basis, which is adaptively formed for each layer based on the statistical properties of the incoming neural responses from the preceding layer. This approach ensures an optimal, non-redundant decomposition of the signal, addressing the implicit Gaussian assumption and potential orthogonality violations inherent in standard DANNs.
The network architecture is structured in a series of deep layers, L=1,…,L, where each layer L contains a set of hidden nodes, N=1,…,N(L). The response R(L,N) of a node N in layer L is defined as a weighted sum of multivariate orthonormal polynomials, Ψi(L), which are functions of the activation-transformed responses from all nodes of the previous layer, A(L)(R(L−1)). The total number of terms, M(L), for each node is determined by the number of inputs from the previous layer, N(L−1), and the desired degree of non-linearity, d(L), following a total-degree truncation scheme. This formulation allows the network to capture high-order interactions between neurons, moving beyond the linear superposition of single neurons.
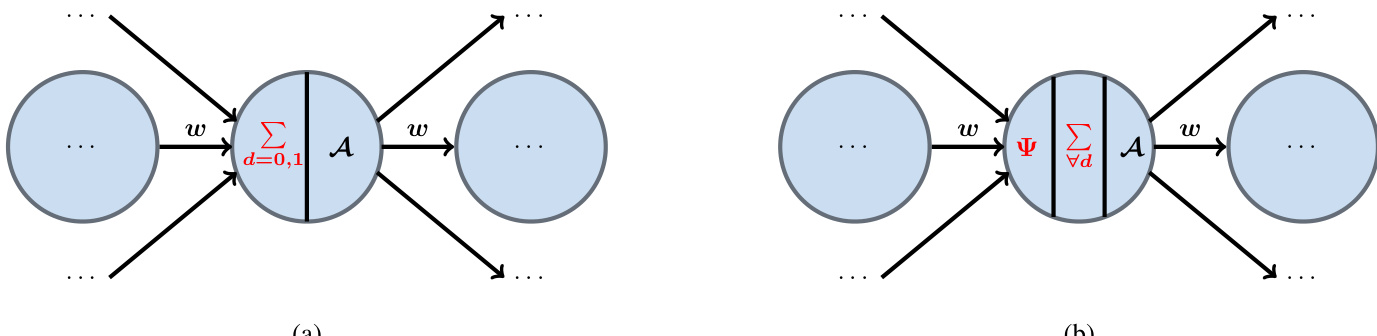
Refer to the framework diagram, which illustrates the key difference between the two architectures. Figure (a) depicts a conventional DANN node, where the incoming signals are summed and passed through an activation function A. Figure (b) shows the DaPC NN node, where the incoming signals are first processed by a data-driven filter that constructs the orthonormal basis Ψ for the layer. The response is then computed as a weighted sum of these basis functions, with the weights w and the degree d determining the non-linearity. This filter mechanism is the central innovation, ensuring the orthonormal representation.
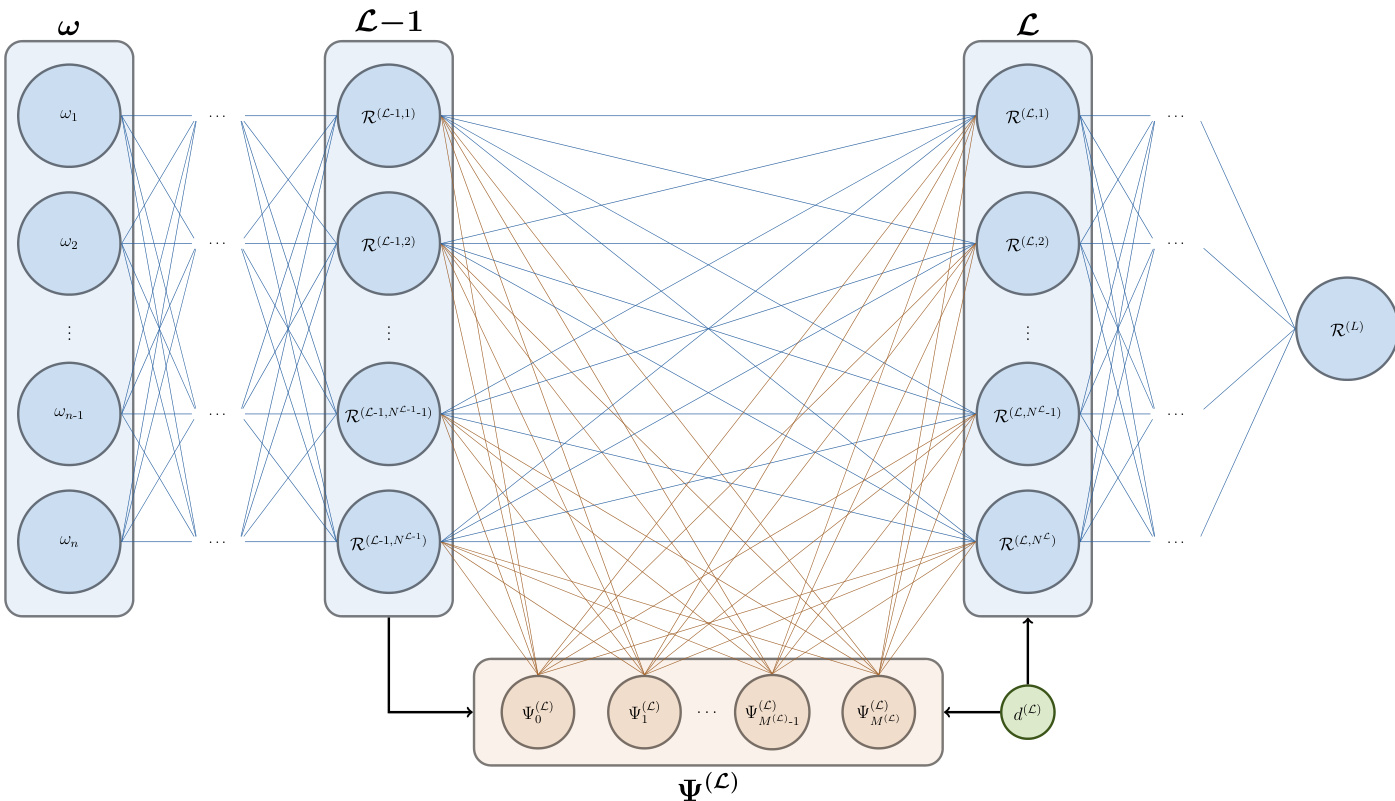
As shown in the figure below, the overall DaPC NN framework consists of an input layer L−1 that receives the raw inputs ω. The response from this layer, R(L−1), is fed into the next layer L. For each layer, the orthonormal basis Ψ(L) is constructed from the responses of the previous layer. This process is sequential and data-driven, meaning the basis is not fixed but adapts to the network's internal state. The degree of non-linearity d(L) is a configurable hyper-parameter that allows the user to control the complexity of the representation on a per-layer basis. The activation function A(L), which is applied to the response of the previous layer before it is fed into the polynomial basis, is a separate component that can be chosen by the user. The framework is flexible, as the orthonormal basis and the activation function are distinct, allowing for a combination of non-linearities from both sources.
The training procedure for the DaPC NN is designed to be consistent with conventional DANNs. The unknown weights, wi(L,N), are optimized by minimizing a loss function, typically the mean squared error (MSE), with a regularization term to prevent overfitting. Crucially, the orthonormal basis Ψ(L) is not a fixed parameter but is implicitly constructed during training. The weights determine the basis through a data-driven process based on the input distribution and the responses of the hidden nodes. This means the orthonormal bases are adaptively recomputed during the iterative training process. The basis construction relies on the Arbitrary Polynomial Chaos (aPC) theory, which uses the statistical moments of the input data to form a set of orthonormal polynomials. As a result, the trained weights not only define the network's predictive function but also uniquely determine the corresponding data-driven orthonormal bases for all layers, making the DaPC NN a self-contained, black-box model that maintains the simplicity of training for the user.
Experiment
The evaluation compares the proposed DaPC NN against conventional DANN and aPC expansions across three benchmark problems with varying training data sizes to validate their predictive accuracy, generalization capabilities, and convergence behavior under different nonlinearity regimes. Qualitatively, the DaPC NN consistently demonstrates superior validation performance and robustness to overfitting by effectively balancing model flexibility with the structural constraints inherited from polynomial chaos theory. In contrast, the conventional DANN suffers from significant overfitting and poor generalization, while the standard aPC expansion lacks sufficient flexibility for highly nonlinear scenarios but benefits from optimized training point distributions. Although all models struggle to accurately capture strong shock propagation due to their reliance on smooth basis functions, the DaPC NN emerges as the most reliable and scalable approach for complex uncertainty quantification tasks.
The authors compare the performance of aPC, DANN, and DaPC NN models in predicting CO2 saturation in a benchmark problem involving shock propagation. The DaPC NN demonstrates superior prediction accuracy and stability compared to aPC and DANN, particularly in capturing the mean and standard deviation of saturation across different distances. The DaPC NN shows reduced oscillations and better convergence, indicating improved robustness in handling the non-linear and discontinuous nature of the problem. The aPC and DANN models exhibit significant deviations and instability, especially when trained with Sobol sequences, highlighting their limitations in this context. DaPC NN outperforms aPC and DANN in predicting mean and standard deviation of CO2 saturation with reduced oscillations. The DaPC NN shows better convergence and stability, especially with Gaussian integration points, mitigating Gibbs effects. aPC and DANN models struggle with the non-linear shock propagation, leading to high prediction errors and instability.
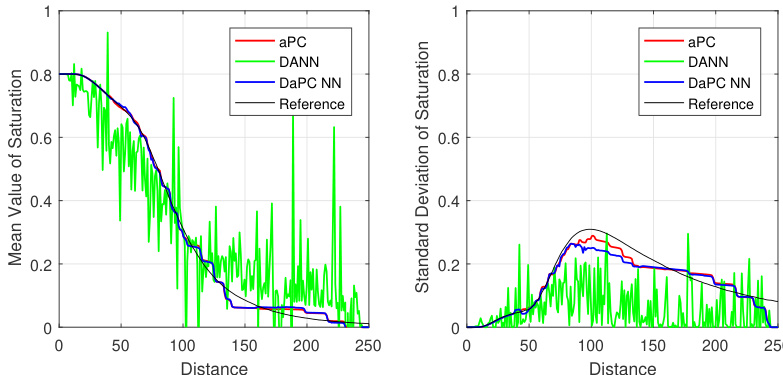
The authors compare the performance of aPC, DANN, and DaPC NN models across different test cases, including the Ishigami function, ON-10 problem, and a CO2 benchmark. Results show that DaPC NN consistently outperforms aPC and DANN in validation accuracy, particularly with limited training data, due to its ability to balance flexibility and regularization. The DaPC NN also demonstrates better convergence and reduced overfitting, especially in high-dimensional and non-linear scenarios. In the CO2 benchmark, all models struggle with shock propagation, but DaPC NN shows improved stability when using Gaussian integration points for training. DaPC NN achieves superior validation performance compared to aPC and DANN, especially with small training datasets. DaPC NN demonstrates faster convergence and reduced overfitting due to its orthonormal basis and regularization properties. In the CO2 benchmark, DaPC NN performs better with Gaussian integration points, mitigating oscillations caused by non-linearity.
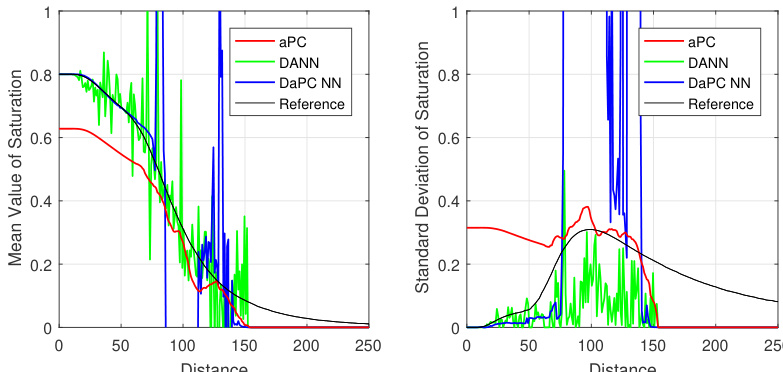
The authors compare the performance of aPC, DANN, and DaPC NN models across different test cases, focusing on prediction accuracy and convergence with varying training data sizes. The DaPC NN consistently demonstrates superior validation performance and faster convergence compared to aPC and DANN, particularly in handling non-linear and high-dimensional problems. The DaPC NN also shows less overfitting and better generalization, especially when trained with limited data, while aPC and DANN struggle with flexibility and regularization issues. DaPC NN shows superior validation performance and faster convergence compared to aPC and DANN across multiple test cases. DaPC NN exhibits less overfitting and better generalization, even with small training data sets. aPC and DANN struggle with flexibility and regularization, leading to poorer performance in high-dimensional and non-linear scenarios.
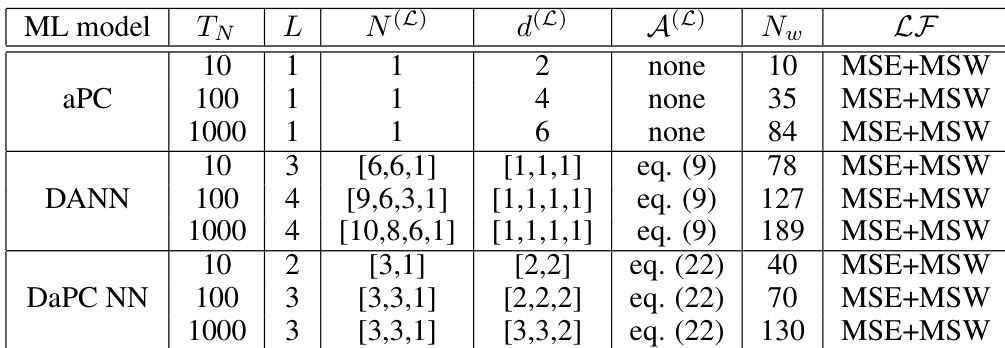
The authors compare the performance of aPC, DANN, and DaPC NN models across multiple test cases, focusing on their prediction accuracy and convergence behavior with varying training data sizes. The DaPC NN consistently demonstrates superior validation performance and faster convergence compared to aPC and DANN, particularly in capturing complex non-linear behaviors and reducing overfitting. The choice of training data distribution and model architecture significantly influences the predictive reliability, with DaPC NN showing robustness even under challenging conditions. DaPC NN achieves better validation performance and faster convergence than aPC and DANN across different test cases. The DaPC NN shows reduced overfitting and improved prediction accuracy, especially with limited training data. Model performance is highly dependent on training data distribution, with DaPC NN benefiting significantly from optimized input sampling strategies.
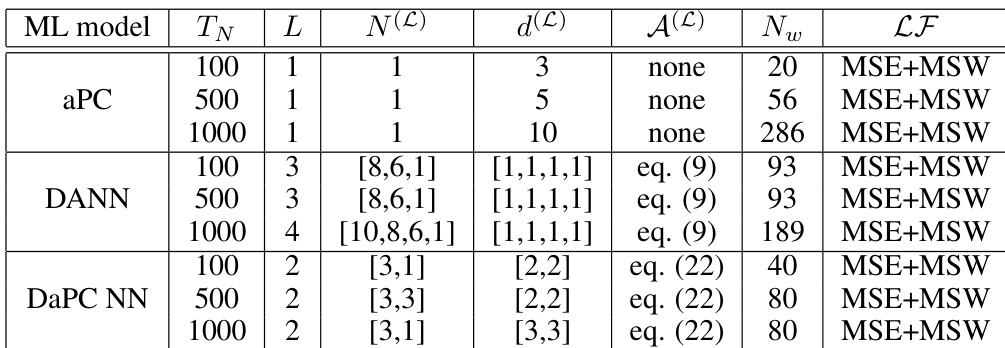
The authors compare the performance of aPC, DANN, and DaPC NN models across different test cases, focusing on their ability to predict validation data with varying training set sizes. The DaPC NN consistently shows superior performance, particularly in validation, with faster convergence and reduced overfitting compared to the other models. The DaPC NN achieves this with fewer degrees of freedom and benefits from the orthonormal structure of aPC, while DANN exhibits overfitting issues and aPC lacks flexibility in capturing complex nonlinearities. DaPC NN demonstrates better validation performance and faster convergence compared to aPC and DANN across all test cases. DaPC NN achieves superior results with fewer degrees of freedom and reduced overfitting, leveraging the orthonormality of aPC. DANN shows significant overfitting and poor generalization, especially with small training data, while aPC lacks flexibility in capturing complex nonlinear behaviors.
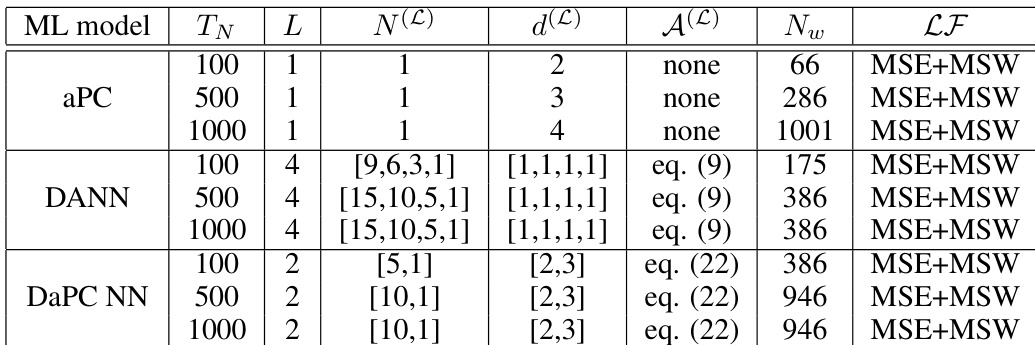
The evaluation compares aPC, DANN, and DaPC neural network models across multiple benchmark problems, including nonlinear shock propagation and high-dimensional test cases, while varying training data sizes and integration strategies. These experiments validate how effectively each architecture balances flexibility and regularization to capture complex, discontinuous behaviors. Qualitative findings indicate that the DaPC model consistently delivers superior stability, faster convergence, and reduced overfitting, particularly under data-scarce or optimized sampling conditions. In contrast, the aPC and DANN approaches struggle with generalization and exhibit instability when handling sharp gradients and high-dimensional nonlinearities.