Command Palette
Search for a command to run...
拡散ベースの音声インペインティング
拡散ベースの音声インペインティング
Eloi Moliner Vesa Välimäki
ワンクリックデプロイのオーディオ LDM オーディオ編集チュートリアル
概要
タイトル:音声インペインティングにおける拡散モデルの適用
抄録:音声インペインティングは、劣化録音における欠損セグメントの再構築を目的とする。既存のほとんどの手法は、ギャップ長が短い場合に妥当な再構築結果を生み出すものの、約100 msを超えるギャップの再構築には苦戦する。本論文では、音声インペインティングのタスクに対して、最近の深層学習モデルの一種である拡散モデルの適用を探る。提案手法は、条件付けなしで訓練された生成モデルを使用し、音声インペインティングに対してゼロショット方式で条件付け可能であり、任意のサイズのギャップを再生成できる。また、音声におけるピッチ等変対称性を活用できるようにする、定数Q変換に基づく改良された深層ニューラルネットワークアーキテクチャも提示する。提案アルゴリズムの性能は、最大300 msまでの短~中程度のギャップ再構築タスクに対する客観的および主観的指標を用いて評価される。公式な聴取テストの結果、50 ms程度の短いギャップにおいて、提案手法はベースラインと同等の性能を発揮することを示した。一方、最大300 msまでの広いギャップでは、提案手法はベースラインを上回り、良好または妥当な音声品質を維持する。本論文で提示された手法は、深刻な局所的な擾乱やドロップアウトに悩まされる音声録音の復元に適用可能である。
One-sentence Summary
Leveraging a constant-Q transform architecture that exploits pitch-equivariant symmetries, this unconditionally trained diffusion model is zero-shot conditioned to reconstruct audio gaps up to 300 milliseconds, outperforming established baselines for wider intervals while maintaining good or fair audio quality as validated by objective and subjective listening tests, thereby enabling robust restoration of recordings with severe local disturbances or dropouts.
Key Contributions
- The paper introduces a zero-shot conditioning strategy for an unconditionally trained diffusion model to reconstruct missing audio segments of arbitrary length, addressing the limitations of prior methods that fail on gaps exceeding 100 ms.
- An improved deep neural network architecture based on the constant-Q transform is proposed to explicitly exploit pitch-equivariant symmetries in audio for enhanced spectral representation and reconstruction fidelity.
- Evaluations using objective and subjective metrics alongside formal listening tests demonstrate that the method matches baseline performance for 50 ms gaps and outperforms existing approaches for gaps up to 300 ms while retaining good or fair audio quality.
Introduction
Audio inpainting reconstructs missing or corrupted segments in recordings, a foundational task for restoring legacy media, compensating for network packet loss, and enabling creative audio production. Traditional techniques relying on autoregressive modeling or sparse signal representations excel only for gaps under one hundred milliseconds because they depend on signal stationarity assumptions that fail over longer durations. While deep generative models like GANs offer more flexibility, they typically require supervised training on specific degradation types, which limits their adaptability to unseen audio contexts. The authors leverage diffusion models to bypass these constraints by training an unconditional generative network that can be conditioned zero-shot during inference. Their approach introduces a novel architecture operating in the invertible Constant-Q Transform domain to exploit pitch-equivariant symmetries in audio. This design enables the model to reconstruct gaps up to three hundred milliseconds long without auxiliary side information, consistently outperforming established baselines while preserving natural perceptual quality.
Dataset
- Dataset composition and sources: The authors do not provide dataset information in this excerpt. The text solely outlines the academic background and professional affiliations of Vesa Välimäki.
- Key details for each subset: No subset breakdowns, sizes, or filtering criteria are mentioned.
- How the paper uses the data: The excerpt does not describe training splits, mixture ratios, or model integration.
- Processing details: No cropping strategies, metadata construction, or preprocessing steps are included.
Method
The proposed method, referred to as CQT-Diff+, leverages a diffusion model framework for audio inpainting, where the core generative process is guided by a denoising neural network. The overall architecture is designed to operate efficiently in a time-frequency domain, utilizing the constant-Q transform (CQT) to exploit the pitch-equivariant structure of harmonic audio signals. The diffusion process begins with a noisy input waveform xT and iteratively denoises it through a series of steps. At each timestep τ, the model predicts a denoised estimate x^0 using a deep neural network Dθ(xτ,τ), which is parameterized following the preconditioning strategy from Karras et al. [48]. This network is composed of a denoiser block Fθ that operates in the CQT domain, defined as Fθ=ICQT∘Fθ′∘CQT. This structure allows the model to process the input waveform through a CQT, apply the neural network in the transform domain, and then invert the transform to produce a time-domain output, maintaining differentiability throughout the process.
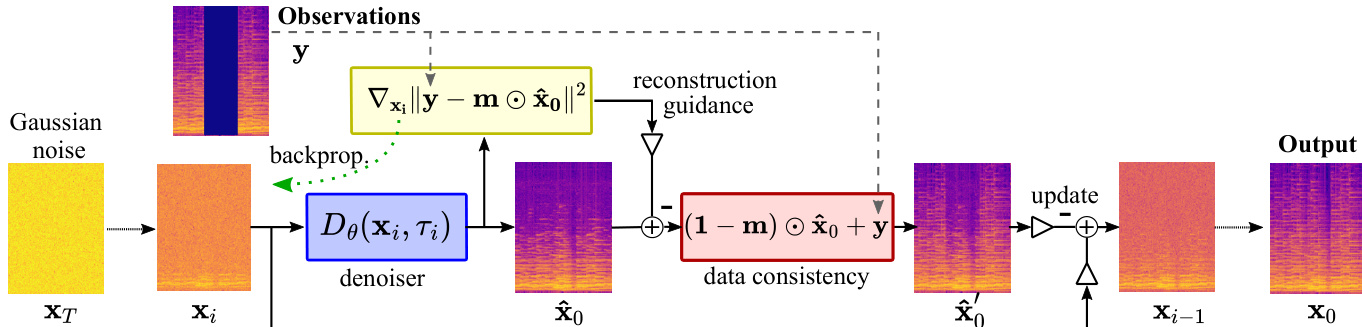
The inference process for audio inpainting is adapted from the standard diffusion framework to solve a linear inverse problem. Given an observed audio signal y with missing samples defined by a binary mask m, the goal is to recover the original signal x0. The model achieves this by conditioning the diffusion process on the observed data. This is done by modifying the score function in the reverse diffusion ODE with a noise-perturbed likelihood score, which incorporates the observed measurements. The posterior score is approximated as the sum of the prior score and the gradient of the log-likelihood, where the likelihood is modeled as a normal distribution. This results in a reconstruction guidance term that pulls the denoised estimate towards the observed data. To ensure the integrity of the observed samples, a data consistency step is applied at each iteration, where the output is updated by replacing the values in the mask with the observed values y. To mitigate artifacts at the mask boundaries, a smoothed version of the mask is used in this step.
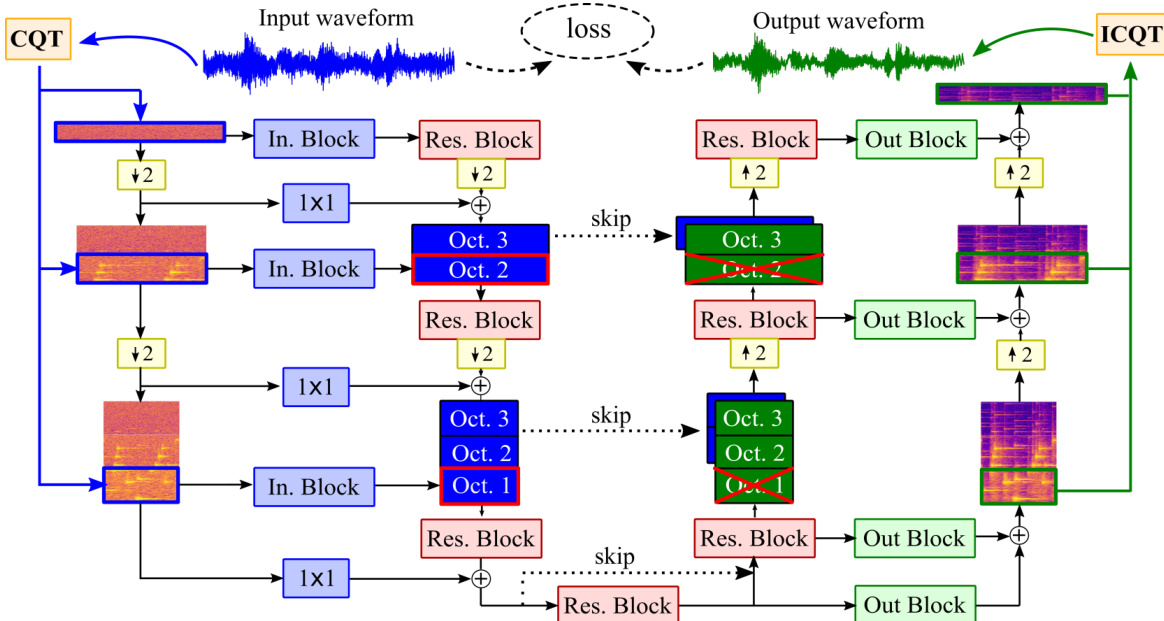
The core denoiser Fθ′ is a U-Net architecture, which is well-suited for the hierarchical representation provided by the CQT. The architecture is designed to process the CQT spectrograms at multiple octave bands, with each octave being processed by a separate branch in the encoder and decoder. The U-Net structure features a symmetric encoder and decoder with skip connections that bridge the intermediate resolutions. The encoder downsamples the input spectrogram by a factor of two at each layer, while the decoder upsamples it. At each resolution, features from the encoder are concatenated with the corresponding features in the decoder. The architecture uses a double real representation, where the real and imaginary parts of the complex CQT features are stacked as two separate channels. This approach avoids the computational overhead of complex-valued layers while preserving the phase relationships between the real and imaginary components. To maintain this symmetry, shift-based operations such as bias terms in convolutional layers are set to zero, and only residual connections are used for additive operations.
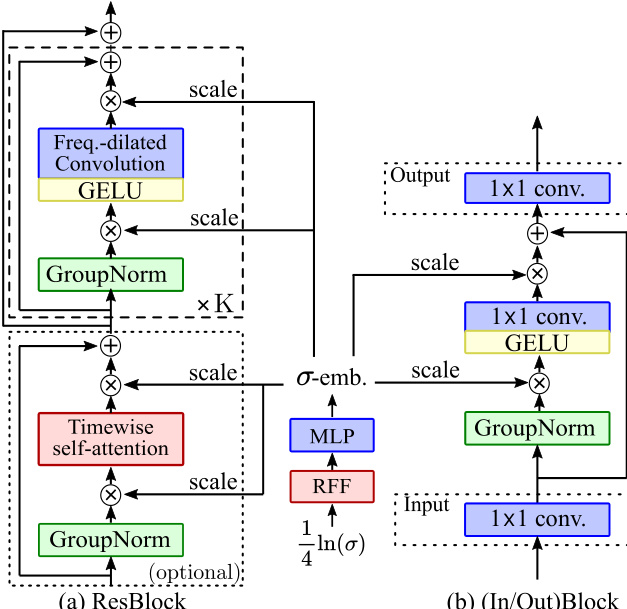
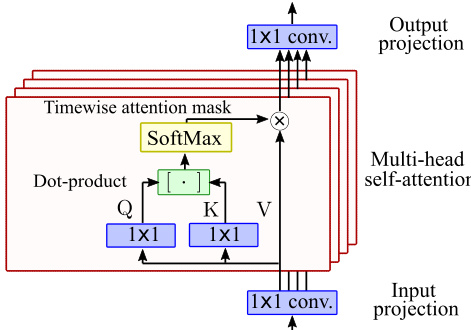
The building blocks of the U-Net are further detailed in the architecture diagrams. The primary building block is the "Res. Block", which is shown in Fig. 3(a). Each Res. Block contains a stack of shift-free Group Normalization layers, followed by a GELU non-linearity and convolutions in both time and frequency. The frequency convolutions use exponentially-increasing dilations to provide a wide receptive field while exploiting pitch-equivariance. In the deeper layers, a timewise self-attention layer is incorporated to capture global temporal dependencies, which is crucial for the inpainting task. The self-attention mechanism, illustrated in Fig. 4, operates only in the time dimension to reduce computational complexity. It uses a 1×1 convolution to project the features into a lower-dimensional space for query and key computation, applies a dot-product attention mechanism with a timewise mask, and then projects back to the original dimension. The entire architecture is conditioned on the noise level σ using a noise-level embedding σ-emb, which is generated from the noise level via random Fourier features (RFF) and a multi-layer perceptron (MLP). This embedding is used to modulate the features through feature-wise linear modulation, without adding shifts.
Experiment
The proposed CQT-Diff+ method was evaluated against LPC and A-SPAIN-L baselines through objective measurements and subjective listening tests to assess musical audio inpainting across gap lengths from 25 to 300 milliseconds. These experiments validate how reconstruction accuracy and perceptual similarity scale with duration, revealing that while all approaches perform comparably for very short gaps, the diffusion-based model consistently delivers superior auditory fidelity as gap size increases. Qualitatively, traditional methods tend to produce artificial or attenuated outputs, whereas CQT-Diff+ generates coherent and musically plausible reconstructions up to 200 milliseconds, demonstrating robust capability to synthesize realistic audio content regardless of gap length.
The authors evaluate the proposed CQT-Diff+ method against two baselines, LPC and A-SPAIN-L, for inpainting short to middle-sized gaps in music recordings. Results from a subjective listening test show that CQT-Diff+ performs comparably to the baselines for the shortest gap length but consistently outperforms them for longer gaps, with significant statistical differences observed at 100 ms, 200 ms, and 300 ms. The performance of all methods degrades as gap length increases, but CQT-Diff+ maintains higher perceptual quality across all tested durations. CQT-Diff+ achieves perceptually similar quality to baselines for the shortest gap length but outperforms them for longer gaps. The performance of all methods declines as gap length increases, with CQT-Diff+ maintaining higher quality across all durations. Statistical analysis confirms significant superiority of CQT-Diff+ over LPC for gap lengths of 100 ms, 200 ms, and 300 ms.
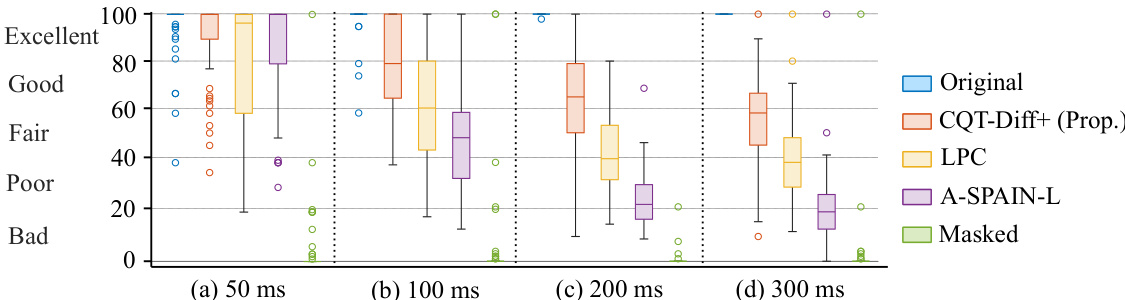
The authors evaluated the proposed CQT-Diff+ method against LPC and A-SPAIN-L baselines through subjective listening tests to validate its perceptual quality for inpainting musical gaps of varying lengths. While all methods experienced performance degradation as gap duration increased, CQT-Diff+ consistently maintained superior audio fidelity across the entire range. These findings confirm that the approach matches baseline performance for minimal gaps while delivering substantially better results for longer intervals, demonstrating its enhanced robustness for extended inpainting tasks.