Command Palette
Search for a command to run...
マルチモーダルネットワーク、CLIP、VQGAN
概要
One-sentence Summary
Vita-CLIP introduces a unified multimodal prompt learning scheme that balances supervised and zero-shot video action recognition by combining global, local, and summary vision prompts with textual prompts, achieving state-of-the-art zero-shot performance on Kinetics-600, HMDB51, and UCF101 while maintaining competitive supervised accuracy.
Key Contributions
- To resolve the trade-off between supervised accuracy and zero-shot generalization in video recognition, a unified multimodal prompt learning framework adapts the pretrained CLIP model without full backbone fine-tuning.
- The approach implements a structured vision-side prompting mechanism comprising global video-level prompts for data distribution modeling, local frame-level prompts for per-frame discrimination, and a summary prompt for condensed representation extraction, complemented by learnable text-side prompts to augment textual context.
- This methodology achieves state-of-the-art zero-shot performance on Kinetics-600, HMDB51, and UCF101 while maintaining competitive supervised performance on Kinetics-400 and Something-Something V2 with a substantially lower number of trainable parameters.
Introduction
Multimodal models like CLIP have established strong zero-shot transfer capabilities for image understanding, but adapting them to video recognition remains challenging due to the high computational cost of processing sequential frames and the scarcity of large-scale video-text datasets. Prior adaptation methods typically force a compromise by either applying prompt learning to a single modality or fully fine-tuning the vision backbone, which inevitably sacrifices zero-shot generalization for supervised accuracy. To resolve this trade-off, the authors leverage a unified multimodal prompting framework called Vita-CLIP that keeps the original CLIP backbone frozen while injecting lightweight, learnable prompts into both the vision and text encoders. By structuring vision prompts across global, frame-level, and summary representations to capture spatiotemporal dynamics, and by augmenting sparse video class labels with adaptable text vectors, the approach effectively balances supervised performance with robust zero-shot generalization without requiring extensive fine-tuning.
Method
The authors leverage the pretrained CLIP model to adapt vision-language representations for video understanding, preserving the generalization capability of the original model while enabling strong supervised performance. The framework operates by freezing the pretrained vision and text encoders and introducing learnable parameters through a multimodal prompting scheme. The overall architecture consists of a video encoder and a text encoder, both derived from the CLIP model, with a cosine similarity objective used to align video and text representations.
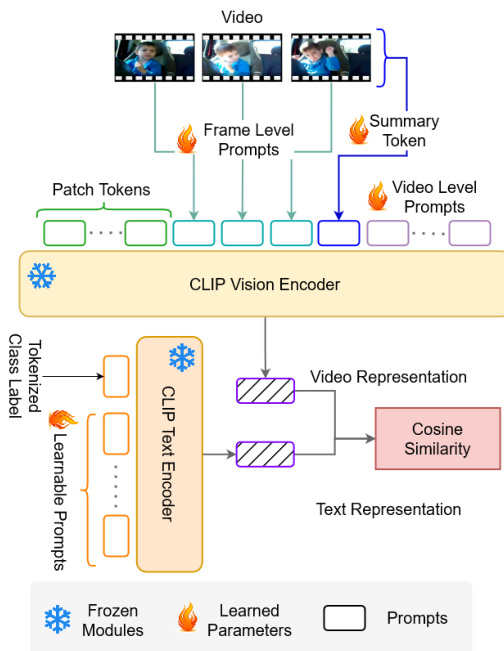
Refer to the framework diagram. The video encoder processes a sequence of frames V∈RT×H×W×3, where T is the number of frames. Each frame is divided into N non-overlapping square patches of size P×P, which are flattened and projected into token embeddings using a linear layer. A classification token xcls is prepended to the sequence of patch tokens for each frame. The resulting per-frame token sequence is augmented with spatial and temporal positional encodings before being processed by the Lv-layered vision encoder. The frame-level representation is obtained by extracting the classification token from the output of the final layer and projecting it to a lower dimension D′. The final video representation v is derived by averaging the per-frame representations.
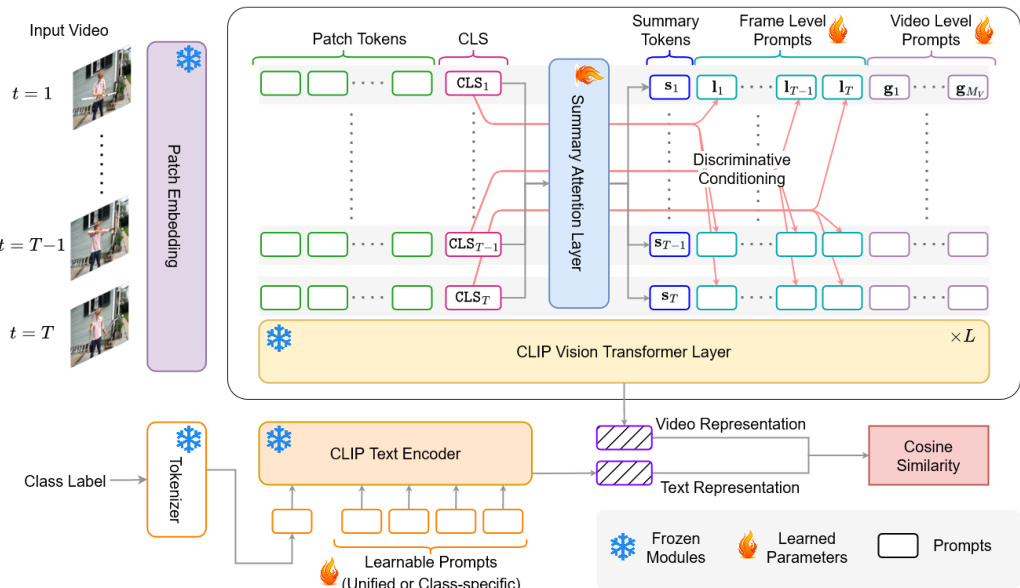
As shown in the figure below, the vision encoder prompt learning scheme introduces three types of learnable tokens to the token sequence at each layer l of the vision transformer. A single summary token is used to aggregate discriminative information across all frames in the clip, which is then communicated back to each frame. This is achieved by projecting the classification tokens from the previous layer, applying a multi-head self-attention (MHSA) operation, and appending the resulting summary token to each frame's token sequence before the frozen self-attention layer. Additionally, Mv video-level global prompt tokens are introduced as randomly initialized learnable vectors to provide capacity for adapting to the video dataset distribution. Frame-level local prompt tokens, equal in number to the frames T, are conditioned on the respective frame's classification token to reinforce discriminative information flow. These local tokens are defined as the sum of a learnable vector and the classification token. The summary, global, and local tokens are appended to each frame's sequence before the frozen self-attention operation, and the extra tokens are removed after the attention layer, with the feed-forward network applied only to the updated frame-level tokens.
On the text side, a prompt learning scheme is employed to adapt the text encoder. The input to the text encoder is a sequence of tokens that includes trainable context vectors and the class label. The authors use a class-specific context (CSC) scheme, where a unique set of trainable vectors is defined for each class. These class-specific prompt vectors are used in all experiments except for zero-shot evaluation, where manual prompts are used. The text encoder processes this token sequence to produce a text representation c.
The learning objective is to maximize the cosine similarity between the video representation v and the text representation c for the correct video-text pair. This is achieved by optimizing the cosine similarity loss function, which measures the alignment between the two representations in the shared embedding space. The framework allows for efficient adaptation to video tasks without finetuning the pretrained encoders, thereby preserving their strong generalization properties.
Experiment
The model is trained on Kinetics-400 using a frozen backbone and a lightweight prompting scheme, then evaluated across multiple benchmarks to assess supervised recognition and zero-shot generalization. Supervised experiments validate that this approach achieves competitive accuracy while substantially lowering computational overhead compared to fully fine-tuned alternatives. Zero-shot evaluations further demonstrate that a single unified training protocol can effectively adapt to unseen categories without requiring separate model configurations. Complementary ablation studies confirm that the integrated local, global, and summary prompts successfully guide the network to focus on discriminative spatiotemporal features, ultimately establishing a robust balance between task-specific performance and cross-domain adaptability.
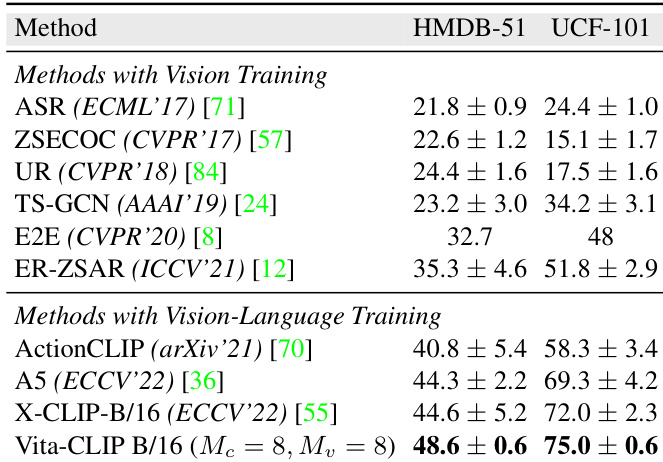
The authors present a comparison of zero-shot performance on HMDB51 and UCF101 datasets, evaluating methods that use vision training versus vision-language training. Results show that the proposed Vita-CLIP method achieves the highest accuracy on both datasets among vision-language training approaches, outperforming prior methods. Vita-CLIP achieves state-of-the-art performance on HMDB51 and UCF101 among vision-language training methods. Vision-language training methods outperform vision training methods on both HMDB51 and UCF101. Among vision-language methods, Vita-CLIP shows significant improvements over previous approaches on both HMDB51 and UCF101.
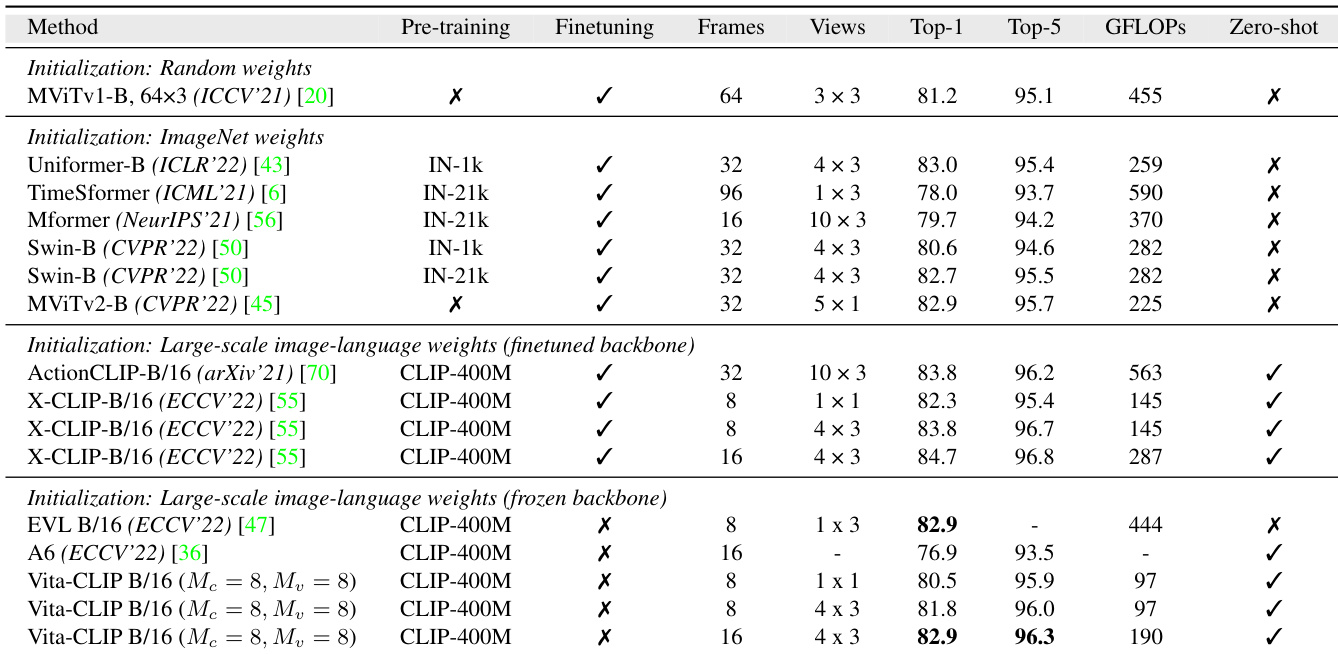
The authors compare their method against various state-of-the-art approaches on Kinetics-400 under supervised training, highlighting performance, computational efficiency, and zero-shot capability. Results show that their approach achieves competitive or superior accuracy with significantly lower computational cost and maintains zero-shot evaluation capability, outperforming methods that require fine-tuning or have higher FLOP counts. The proposed method achieves competitive or better accuracy than existing approaches while using substantially fewer FLOPs and keeping the backbone frozen. The method outperforms baseline models in zero-shot evaluation, maintaining capability where other methods cannot. The approach demonstrates strong performance across different initialization strategies, particularly with large-scale image-language pretraining and frozen backbones.
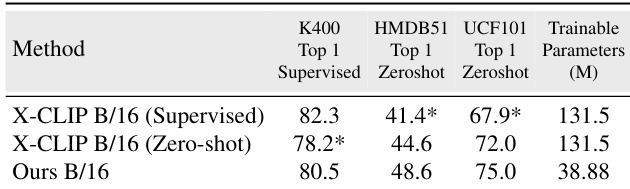
The authors compare their method with X-CLIP across supervised and zero-shot settings on K400, HMDB51, and UCF101, demonstrating superior performance in both scenarios while using significantly fewer trainable parameters. Their approach achieves higher accuracy than X-CLIP in both settings with a single model trained under consistent conditions, avoiding the need for separate training configurations. The method maintains strong zero-shot capability without sacrificing supervised performance, highlighting a balanced trade-off between the two regimes. The proposed method outperforms X-CLIP in both supervised and zero-shot settings on K400, HMDB51, and UCF101. It achieves higher accuracy than X-CLIP in both settings while using substantially fewer trainable parameters. The method uses a single model and training setup for both supervised and zero-shot evaluation, unlike X-CLIP which requires different configurations.
The authors conduct ablation studies on the impact of different video prompting components in their method. Results show that adding global video-level prompts improves performance, and further incorporating local frame-level prompts and a summary token leads to additional gains, indicating that these components are complementary and contribute to the model's accuracy. The best performance is achieved when all three prompting types are used together. Adding global video-level prompts improves performance over the baseline. Incorporating local frame-level prompts further increases accuracy. Using a summary token in addition to global and local prompts yields the highest performance.
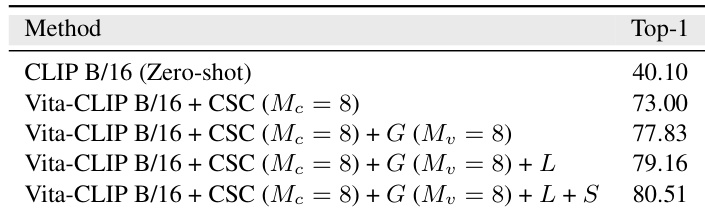
The authors compare their method, Vita-CLIP, with existing approaches on Kinetics-400 under supervised training, highlighting that it achieves competitive performance with lower computational costs and maintains zero-shot capability. The results show that Vita-CLIP outperforms other methods with frozen backbones while using fewer parameters and maintaining the ability to generalize to unseen categories. Vita-CLIP achieves competitive top-1 accuracy with a frozen backbone and lower computational cost compared to methods that fine-tune the backbone. Vita-CLIP supports zero-shot evaluation, unlike several other methods that require fine-tuned backbones and cannot be used for zero-shot recognition. Among methods with frozen backbones, Vita-CLIP achieves higher performance than B2 and other approaches on the same benchmark.

The evaluation setup spans supervised and zero-shot settings across multiple video recognition benchmarks, validating the method's accuracy, computational efficiency, and parameter economy against established baselines. Comparative experiments confirm that the framework consistently outperforms prior approaches while maintaining a frozen backbone and requiring only a single unified training configuration, while ablation studies validate that combining global video, local frame, and summary prompts yields complementary performance improvements. Overall, the findings demonstrate that the proposed method achieves state-of-the-art recognition capabilities with significantly lower computational overhead and robust zero-shot generalization without sacrificing supervised accuracy.