Command Palette
Search for a command to run...
パンオプティックワンクリックセグメンテーション:農業データへの適用
パンオプティックワンクリックセグメンテーション:農業データへの適用
Patrick Zimmer Michael Halstead Chris McCool
ワンクリックでLlama-3.3-70B-Instructをデプロイ
概要
タイトル:なし
抄録:雑草防除において、精密農業は除草剤の使用量を大幅に削減し、経済的かつ生態学的な利益をもたらすことができる。ここで重要な要素は、画像データからすべての植物(作物および雑草)を検出し、セグメント化する能力である。現代のインスタンスセグメンテーション手法はこれを実現できるが、そのようなシステムを訓練するには、入手に高額な費用と労力を要する大量の手動ラベル付けデータが必要である。弱教師あり学習は、ラベル付けの努力とコストを大幅に削減するのに役立つ。本論文では、クリック入力から疑似ラベルを生成し、新規データセット作成時のラベル付け負担を軽減するための、効率的かつ正確なオフラインツールである「パンプティックワンクリックセグメンテーション」を提案する。我々のアプローチは、従来の手法がN個のすべてのオブジェクトを独立して反復処理するのに対し、シーン内のすべてのN個のオブジェクトのピクセル単位の位置を同時に推定する。これにより、訓練時間を大幅に短縮した非常に効率的な手法が実現する。パンプティックワンクリックセグメンテーション手法の訓練にデータのごく一部(10%)のみを使用するだけで、困難なビート(サトウダイコン)およびトウモロコシの画像データそれぞれにおいて、平均オブジェクトIntersection over Union(IoU)が68.1%および68.8%となり、従来のワンクリックアプローチと同等の性能を提供しつつ、訓練速度は約12倍(桁違いに)高速である。我々は、残りの90%のデータに対してクリック注釈から疑似ラベルを生成することで、本システムの実際の適用可能性を実証する。これらの疑似ラベルは、半教師あり的方式でMask R-CNNの訓練に使用され、ビートおよびトウモロコシのデータそれぞれにおいて、平均前景IoUの絶対性能をそれぞれ9.4ポイントおよび7.9ポイント向上させ、本アプローチが困難なデータを迅速に注釈付けする可能性を示している。最後に、我々のパンプティックワンクリックセグメンテーション手法は、注釈付けの輪郭描画中に逃したクリックを回復できることを示し、従来のアプローチに対するさらなる利点を明らかにする。
One-sentence Summary
The authors propose Panoptic One-Click Segmentation, a weakly supervised method that jointly estimates all scene objects to generate click-based pseudo-labels, reducing training time by an order of magnitude while achieving 68.1% and 68.8% mean object IoU on sugar beet and corn datasets with only 10% of the labeled data and subsequently improving Mask R-CNN foreground IoU by 9.4 and 7.9 points in semi-supervised training.
Key Contributions
- This paper introduces a panoptic one-click segmentation framework that generates pseudo-labels from sparse click inputs to reduce manual annotation costs in agricultural plant segmentation.
- The proposed method jointly estimates the pixel-wise locations of all objects in a scene simultaneously, replacing traditional independent iterative processing to substantially reduce training times.
- Evaluations on sugar beet and corn datasets demonstrate that training with only 10% of labeled data achieves 68.1% and 68.8% mean object IoU while operating approximately 12 times faster than baseline methods, and the generated pseudo-labels improve downstream Mask R-CNN foreground IoU by 9.4 and 7.9 points respectively.
Introduction
Precision agriculture depends on accurate plant segmentation to enable targeted weed control and reduce herbicide usage, yet training these vision systems traditionally requires expensive pixel-level annotations. Existing weakly supervised methods that generate pseudo-labels from sparse inputs like single clicks remain computationally inefficient because they process each object independently across multiple forward passes. The authors leverage panoptic segmentation to jointly resolve all objects in a scene from a single click per instance during a single forward pass, creating a highly efficient offline annotation tool. This approach accelerates model training by an order of magnitude and successfully generates high-quality pseudo-labels for the vast majority of agricultural datasets, substantially improving downstream instance segmentation performance while requiring minimal manual effort.
Dataset
- Composition and Sources: The authors evaluate their approach on two agricultural weeding datasets, designated as SB20 and CN20, which contain images featuring multiple, frequently overlapping plant instances across various species and sizes.
- Subset Details: Annotations for both datasets include keypoint or stem locations to serve as interactive click targets. Due to occlusion or border placement, 63 instances in SB20 and 30 instances in CN20 lack explicit keypoints.
- Training Strategy and Splits: The authors implement a semi-supervised workflow that trains on a small fraction of manually labeled data. They allocate 10 percent of each dataset for manual supervision and generate pseudo-labels for the remaining 90 percent using models trained on that initial 10 percent split.
- Processing and Input Generation: For plants without predefined keypoints, the authors calculate the center of mass of the binary mask to determine click coordinates. If that point falls outside the mask, they apply iterative binary erosion until the object disappears and randomly select a coordinate from the penultimate iteration to guarantee an in-bounds location. During training, they add plus or minus 10 pixels of random noise to the click positions to simulate human annotation uncertainty while ensuring the points remain within the target region.
Method
The authors leverage a panoptic segmentation framework to develop a novel one-click segmentation system that jointly estimates the locations of all objects in an image within a single forward pass, significantly reducing computational overhead compared to traditional methods. The proposed approach is built upon Panoptic-Deeplab, a model that combines semantic and instance segmentation by producing three outputs: a semantic segmentation map, a center offset map, and an object center map. The semantic map classifies each pixel into a category, distinguishing between "things" (countable objects such as plants) and "stuff" (non-countable regions like background or textures). The center map identifies the location of each object’s center, while the offset map provides per-pixel displacement vectors toward the nearest object center, enabling pixel assignment to the correct instance during post-processing.
The baseline one-click segmentation method processes each object independently, requiring N forward passes for N objects in an image. This approach uses a Gaussian-encoded click transform map as an additional input channel to the encoder-decoder network, where each click is represented as a 2-D Gaussian with a standard deviation of 8. When multiple objects are present, this procedure is repeated for each positive click, and optionally, negative clicks from other objects are encoded into a secondary click map to improve scene understanding. However, this iterative process is computationally expensive due to repeated processing of the same image.
In contrast, the proposed panoptic one-click segmentation system operates in a single pass by adapting the Panoptic-Deeplab architecture. The input consists of the RGB image and a click transform map, which serves as both the network input and the ground truth for object centers. The network is modified to predict only two outputs: the semantic segmentation map and the center offset map. The object center estimation head is disabled, and the user-provided click locations are directly used as center locations during post-processing, as shown in the framework diagram 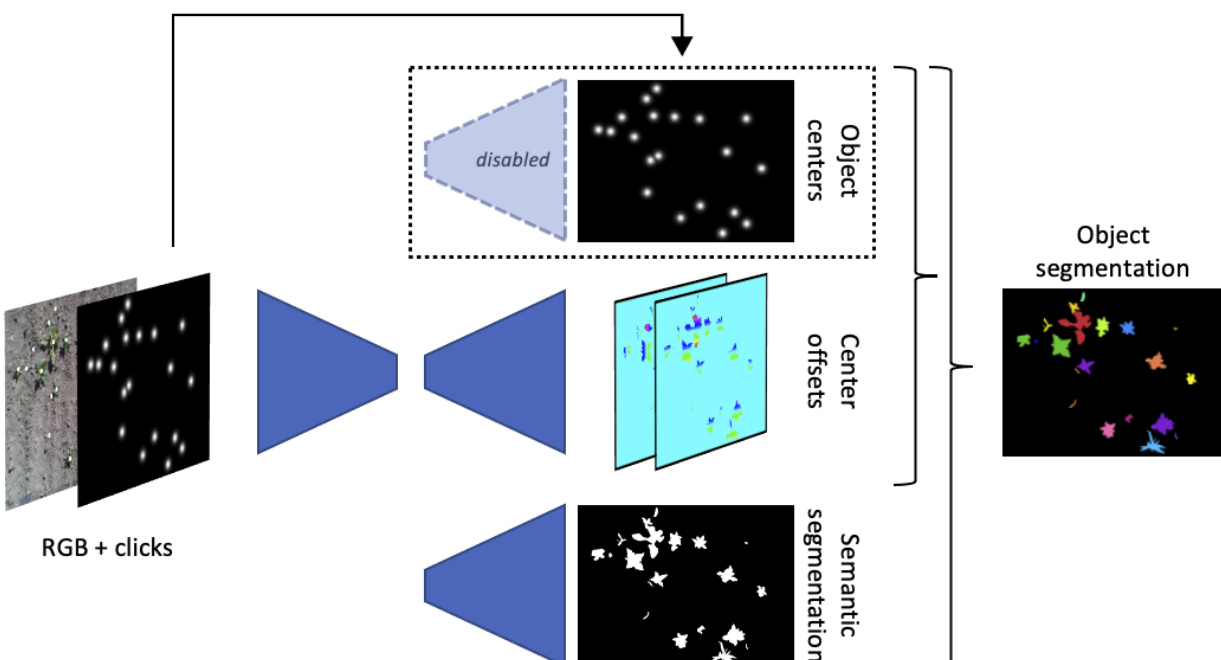 . This design eliminates the need for the network to predict object centers, streamlining inference and enabling joint processing of all objects simultaneously.
. This design eliminates the need for the network to predict object centers, streamlining inference and enabling joint processing of all objects simultaneously.
Furthermore, the system can be extended to recover from annotation errors such as missing clicks by reintroducing the object center estimation head as a third output. In this variant, the network predicts object centers directly, allowing it to estimate missing click locations even when user input is incomplete. The click map remains as an input channel but is no longer used in post-processing, as the network’s predicted centers replace the annotated ones. This adaptation enhances robustness to annotation noise while maintaining the efficiency of a single-pass inference. The overall architecture integrates these components into a unified framework that efficiently processes multiple objects in a single pass, as illustrated in the diagram 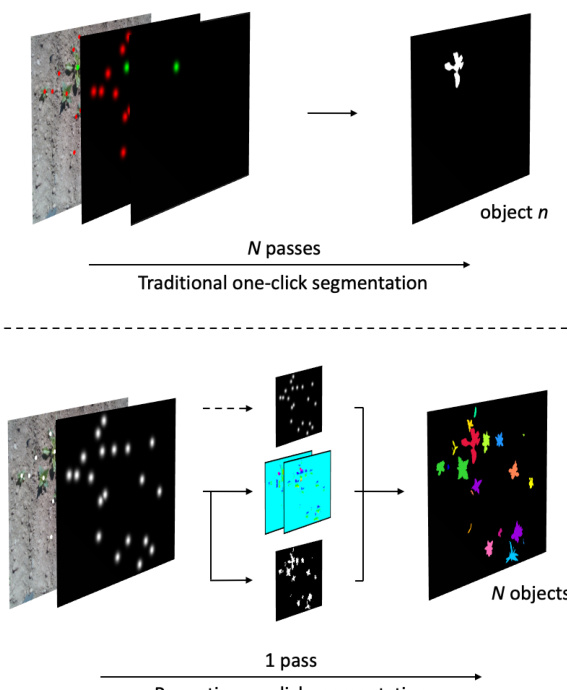 .
.
Experiment
The evaluation comprises three experiments assessing a novel panoptic one-click segmentation framework against traditional methods across agricultural datasets. The first experiment validates general segmentation performance and training efficiency, demonstrating that the panoptic approach inherently prevents object overlaps and trains significantly faster while maintaining comparable accuracy. Subsequent experiments validate the framework's utility in semi-supervised learning and its robustness to missing inputs, showing that it effectively generates high-quality pseudo-labels from minimal annotations and successfully recovers object locations even when the majority of user clicks are absent. Collectively, these findings establish the panoptic method as a highly efficient and resilient tool for rapid dataset creation and annotation recovery.
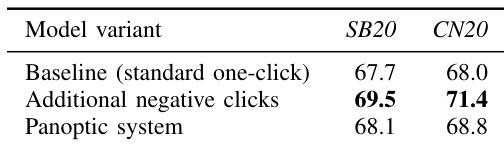
The authors compare semi-supervised instance segmentation performance using different one-click segmentation methods as pseudo-label sources. Results show that using pseudo-labels generated from one-click models improves performance over using only a small fraction of manually annotated data, with the panoptic approach achieving competitive results. The panoptic system demonstrates robustness to missing input clicks, maintaining recognition quality even when a significant portion of clicks are absent. Using pseudo-labels from one-click models improves instance segmentation performance compared to using only a small manually annotated subset. The panoptic one-click system achieves performance close to fully supervised baselines and outperforms standard one-click methods in some cases. The panoptic system maintains recognition quality even when a large portion of input clicks are missing, indicating robustness to missing annotations.

The authors compare traditional one-click segmentation methods with a proposed panoptic one-click approach, evaluating performance on two datasets. Results show that the panoptic system achieves competitive segmentation accuracy while being significantly faster to train, and it demonstrates robustness to missing input clicks. The panoptic method also performs well in semi-supervised learning tasks, generating pseudo-labels that improve instance segmentation performance. The panoptic one-click system achieves competitive segmentation performance compared to traditional methods while being substantially faster to train. The panoptic approach reduces overlapping errors common in traditional one-click systems and shows robustness when input clicks are missing. In semi-supervised learning, the panoptic system generates pseudo-labels that significantly improve instance segmentation performance over using only a small fraction of manually annotated data.
The authors evaluate a panoptic one-click segmentation system's ability to recover from missing input clicks by comparing performance metrics under varying levels of missing clicks. Results show that the system maintains high recognition quality even when a significant portion of clicks are missing, with only a gradual decline in performance as the percentage of missing clicks increases. The system demonstrates robustness in estimating object centers, as predicted centers yield results close to those with user-provided clicks. The panoptic system maintains high recognition quality even when a large percentage of input clicks are missing. Performance degrades gradually as the percentage of missing clicks increases, with recognition quality remaining substantial at 75% missing clicks. The system achieves recognition quality comparable to user-provided clicks when using network-predicted centers, indicating strong object localization capability.

The experiments compare the proposed panoptic one-click segmentation system against traditional and fully supervised baselines across two datasets to evaluate training efficiency, segmentation accuracy, and resilience to incomplete input. The first set of tests validates the system's effectiveness in semi-supervised instance segmentation, demonstrating that its generated pseudo-labels substantially improve performance over minimal manual annotations and approach fully supervised levels. Additional evaluations assess the model's ability to handle missing user interactions, confirming that it maintains high recognition quality, minimizes overlapping errors, and accurately estimates object centers even when most clicks are absent. Overall, the findings establish the panoptic approach as a faster, more accurate, and highly robust alternative for interactive segmentation tasks.