Command Palette
Search for a command to run...
TorchVision インスタンスセグメンテーションのファインチューニングチュートリアル
概要
One-sentence Summary
This work introduces task-specific data augmentation and inference processing strategies to address data scarcity in the 2022 VIPriors Instance Segmentation Challenge by leveraging visual inductive priors, achieving 0.531 [email protected]:0.95 with a Hybrid Task Cascade detector on a Swin-Base-based CBNetV2 backbone.
Key Contributions
- This work addresses data-deficient instance segmentation by systematically integrating visual inductive priors into the training workflow to compensate for limited sample availability.
- A Task-Specific Data Augmentation pipeline is introduced, combining view-specific and man-ball interaction copy-paste operations with geometric and photometric transformations, alongside a task-specific inference processing strategy to maximize prior utilization.
- Experimental evaluation on the 2022 VIPriors Instance Segmentation Challenge demonstrates that the method achieves a 0.531 [email protected]:0.95 score on the test set using a Hybrid Task Cascade detector with a Swin-Base CBNetV2 backbone, trained entirely from scratch.
Introduction
The technical context and application domain cannot be outlined without the source material. Prior work limitations and the authors' primary contribution cannot be identified until the research body or abstract is provided. Please share the text so I can draft the background summary in the requested format.
Dataset

Dataset Composition and Sources
- The authors use the official VIPriors Instance Segmentation Challenge dataset, which contains court-level photographs featuring basketball players, coaches, referees, and basketballs.
- The collection is divided into a training set and a validation set, with test images reserved for challenge evaluation.
Subset Details and Metadata
- The original dataset contains 1,840 training images and 620 validation images.
- View metadata is automatically derived from image filenames, where a trailing "0" indicates a right-court perspective and any other suffix denotes a left-court perspective.
- Basketball variants are categorized as colorful (multi-color) or pure (single-color), with the original training data heavily skewed toward colorful examples.
Data Processing and Augmentation Pipeline
- All persons and basketballs are first cropped from the training and validation sets alongside their mask annotations to prepare for instance-level operations.
- A view-specific copy-paste strategy places objects into mathematically constrained regions to ensure even court distribution while strictly excluding auditorium areas.
- A ball-specific copy-paste phase simulates player-ball interactions by pasting balls within person bounding boxes, and probabilistically generates pure-ball variants by adjusting RGB values to balance color distribution.
- Base transformations apply random geometric operations (shear, rotate, or translate) and full photometric distortions (brightness, contrast, saturation, hue) to each image.
Training Configuration and Final Processing
- The original 2,460 images are duplicated ten times without modification to expand the training pool before augmentation.
- Augmented images undergo random scaling (820 to 3,080 pixels on the short edge, up to 3,680 on the long edge) followed by random cropping and padding to a fixed 1,920 by 1,440 resolution.
- Models are trained from scratch using the AdamW optimizer with an initial learning rate of 0.0001, followed by stochastic weight averaging (SWA) finetuning once convergence is reached.
Method
The authors leverage a Hybrid Task Cascade (HTC) based detector as the core instance segmentation framework, built upon a CBSwin-Base backbone with CBFPN. The overall architecture is structured as a cascade of detection stages, where the backbone processes the input image to generate feature maps that are subsequently refined through a neck module. The backbone is specifically implemented using the CBSwin-Base architecture, which is a variant of the Swin Transformer designed for efficient feature extraction. The features are then passed through the CBFPN (Cross-Stage Feature Pyramid Network), which enhances multi-scale feature representation by integrating information across different levels of the network.
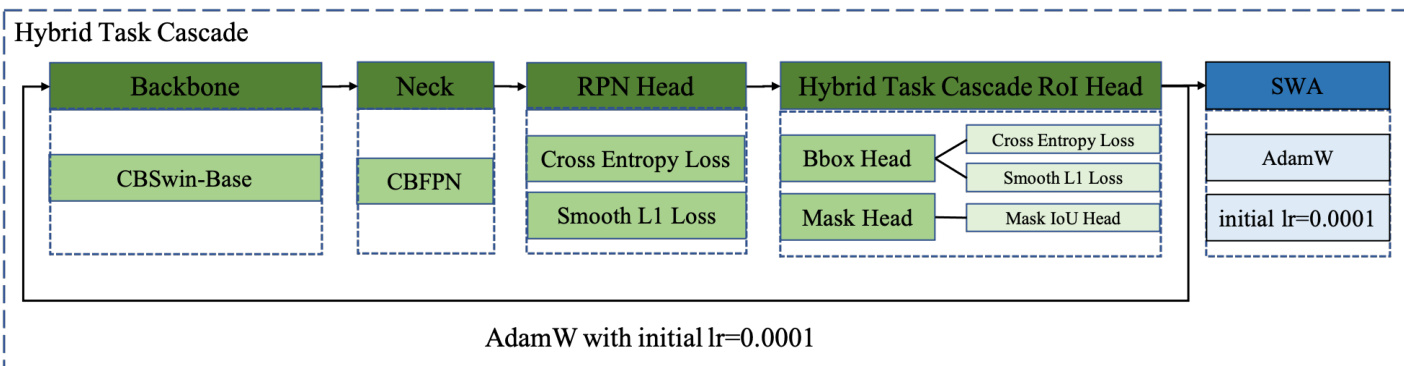
As shown in the figure below: the refined features are fed into the RPN (Region Proposal Network) head, which generates region proposals based on cross-entropy loss and smooth L1 loss for bounding box regression. These proposals are then processed by the Hybrid Task Cascade RoI Head, which consists of multiple stages for refined detection. The RoI Head includes a Bbox Head that predicts bounding box coordinates using cross-entropy and smooth L1 loss, and a Mask Head that generates segmentation masks. To improve mask quality estimation, a Mask IoU Head is added to the HTCMaskHead, enabling the model to learn mask quality independently of classification confidence, thereby enhancing alignment between mask quality and mask score.
The training process begins with standard optimization using AdamW with an initial learning rate of 0.0001. Once the model converges, a SWA (Stochastic Weight Averaging) training strategy is applied for fine-tuning, which enhances model robustness and generalization. This training pipeline is designed to effectively handle the data-deficient scenario of the VIPriors challenge, where no pre-trained weights are allowed and training data are limited.
Experiment
The proposed method was evaluated on the VIPriors Instance Segmentation Challenge test set, establishing HTC-CBSwinBase with soft NMS as the baseline. A systematic ablation study validated the incremental effectiveness of each proposed component and optimization strategy, including the MaskIoU head, TS-DA domain adaptation, test-time augmentation, threshold adjustments, SWA finetuning, inference cropping, and score filtering. Qualitatively, these modifications consistently enhanced segmentation accuracy, with domain adaptation and weight averaging delivering the most substantial performance gains. The cumulative refinement of these techniques, combined with final model ensembling, enabled the system to achieve a highly competitive result on the challenge benchmark.
The authors present an ablation study to analyze the contributions of various components to the final model performance. Results show that each introduced component, including additional training strategies and inference modifications, progressively improves the model's performance on the test set. Adding the MaskIoU head and TS-DA strategy leads to significant improvements over the baseline. Inference cropping and max score filtering further enhance the model's performance. Ensembling models with adjusted mask loss weight achieves the highest performance.
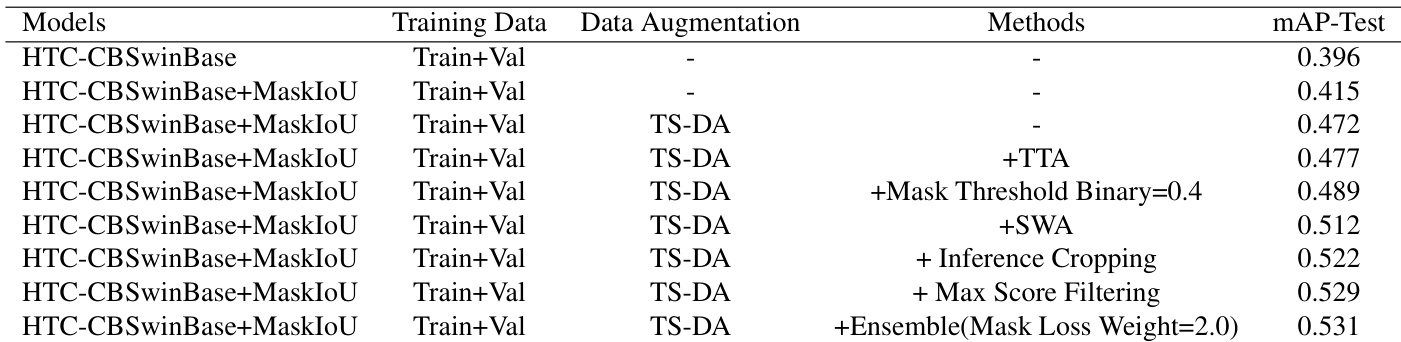
An ablation study was conducted to assess how individual training strategies and inference modifications contribute to the model's overall effectiveness. The experiments validate that incorporating components such as the MaskIoU head, TS-DA strategy, inference cropping, and score filtering consistently drives progressive performance gains on the test set. Ultimately, ensembling these models with an adjusted mask loss weight proves to be the most effective approach, confirming that each added element meaningfully strengthens the final system.