Command Palette
Search for a command to run...
Faster R-CNN を用いた物体検出のためのクラス活性化マップ
概要
One-sentence Summary
POLY-CAM is a high-resolution Class Activation Map for convolutional neural networks that combines early and late layer features to produce saliency maps competitive in insertion-deletion faithfulness while outperforming prior methods in localizing class-specific features.
Key Contributions
- The paper introduces a gradient-free method that combines activations from early and late network layers to generate high-resolution Class Activation Maps without requiring specialized training.
- A novel weight computation mechanism merges dual scoring strategies to refine activation map weights, improving upon perturbation-based approaches such as Score-CAM.
- Experimental evaluations demonstrate competitive insertion-deletion faithfulness metrics while outperforming prior methods in the precise localization of class-specific features.
Introduction
The rapid deployment of convolutional neural networks in safety-critical fields like medical imaging has driven demand for explainable AI, since saliency maps allow practitioners to verify that models rely on meaningful anatomical features rather than spurious dataset biases. Existing visualization techniques force a tradeoff between resolution and reliability, as perturbation methods are computationally expensive, gradient-based approaches suffer from noise and fragmented peaky outputs, and standard Class Activation Maps remain too coarse due to their reliance on final network layers. To overcome these limitations, the authors propose POLY-CAM, a framework that multiplexes high-resolution activations from early convolutional layers with upsampled late-layer class-specific maps. By bypassing gradient backpropagation entirely, this method produces sharp, high-resolution saliency maps that match state-of-the-art faithfulness metrics while delivering significantly more precise localization of class-discriminative features.
Dataset
- Dataset Composition & Sources: The authors construct their evaluation set using images from the 2012 ILSVRC validation set, augmented with precomputed saliency maps and faithfulness metrics tailored for the VGG16 and ResNet50 architectures.
- Subset Details & Organization: Saliency outputs are packaged as
.npzfiles, with one file allocated per model and saliency method. Each archive uses image filenames (including the.JPEGextension) as keys to index the corresponding numpy arrays. Faithfulness measurements are distributed as.csvfiles that explicitly categorize data by deletion or insertion protocols, area under the curve summaries versus step-by-step class certitude, target model, and saliency technique. - Data Usage & Processing: The authors leverage this curated data to quantify model faithfulness through deletion and insertion scoring pipelines. Rather than relying on static outputs, they provide Python scripts to regenerate the
.npzand.csvartifacts, alongside Jupyter notebooks that automate data loading and metric computation. - Metadata & Additional Processing: File organization relies on strict naming conventions and key-based indexing to ensure traceability. All components, including the exact image list, generation scripts, interactive notebooks, and a comprehensive README, are shared via supplementary materials and a dedicated anonymous server to support full reproducibility and blind review workflows.
Method
The authors leverage a recursive multiplexing strategy to generate high-resolution class activation maps, introducing the Poly-CAM approach. This method builds upon conventional Class Activation Maps (CAMs) but enhances resolution by combining activation maps from early layers with upsampled saliency maps from deeper layers. The process begins with the standard CAM computed at the final convolutional layer, PLc=CAMLc, and proceeds backward through the network. At each layer l, the saliency map Plc is derived by modulating the upsampled saliency map from the next layer, Pl+1c, using a locally normalized activation map from the current layer. This modulation ensures that saliency values are confined to spatial regions where activations are present, preserving structural coherence across layers.
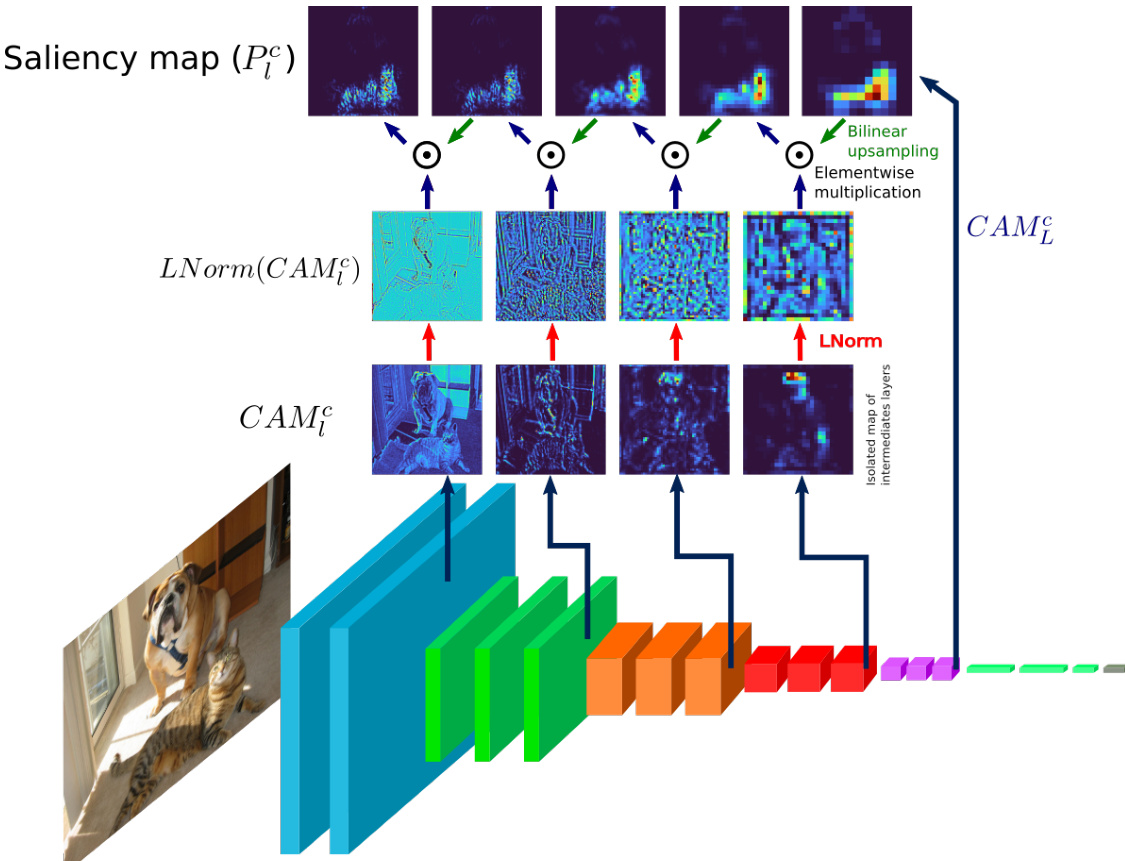
As shown in the figure below, the framework operates in a backward recursive manner, starting from the final layer and progressively refining the saliency map at each preceding layer. The upsampled Pl+1c is element-wise multiplied with LNorm(CAMlc), where LNorm applies local normalization by dividing each element by the mean of its corresponding s×s block. This operation ensures that the saliency distribution remains consistent while allowing the resolution to increase. The local normalization prevents over-amplification of saliency in regions with low activation, maintaining focus on semantically relevant areas. The recursive nature of the process enables the integration of fine-grained details from early layers with high-level semantic information from deeper layers, resulting in a high-resolution saliency map that is both spatially precise and semantically meaningful.
The weighting of individual activation channels is determined using three distinct methods: Channel-wise Increase of Confidence (CIC), Channel-wise Decrease of Confidence (CDC), and Channel-wise Variation of Confidence (CVC). CIC measures the increase in the softmax output when the input region corresponding to an activation map is unveiled. CDC evaluates the decrease in output when that region is masked, capturing the importance of a feature not only when present but also when absent. CVC combines both effects, providing a comprehensive measure of a channel’s contribution to the prediction. These weights are then used in the linear combination of activation maps within the recursive framework. The final saliency map is computed through a backward recursion, where each layer’s contribution is modulated by the upsampled saliency from the next layer and the local activation pattern of the current layer, producing a refined, high-resolution output.
Experiment
The evaluation utilizes two thousand validation images processed through VGG16 and ResNet50 networks to compare three Poly-CAM variants against a comprehensive suite of existing explanation methods. Visual assessments validate the method's ability to progressively refine saliency maps across layers, yielding superior resolution and precise class-specific highlighting while appropriately balancing target and contextual features. Supplementary experiments confirm the framework's reliability through cascading randomization sanity checks, demonstrate low sensitivity to input perturbations, and verify through ablation studies that multi-layer integration and normalization are essential for optimal performance. Overall, the combined PCAM± variant proves to be a highly accurate and versatile approach that consistently outperforms baselines in visual clarity and faithfulness.
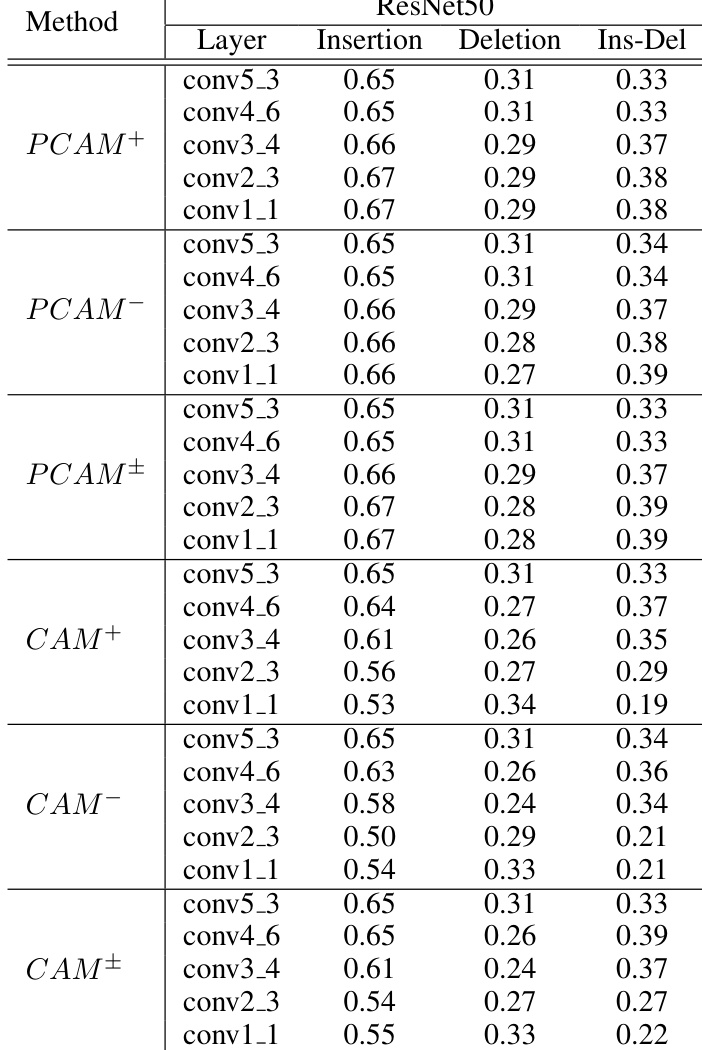
The authors compare the performance of Poly-CAM variants with traditional CAM methods across different network layers using faithfulness metrics. Results show that Poly-CAM methods maintain higher insertion scores and lower deletion scores compared to CAM methods, with PCAM+ and PCAM- performing consistently across layers. The combined variant PCAM± achieves competitive results, particularly in deletion metrics, indicating better precision in highlighting relevant features. Poly-CAM methods outperform traditional CAM methods in insertion and deletion metrics across different network layers. PCAM+ and PCAM- variants show consistent performance across layers, with PCAM+ achieving higher insertion scores. PCAM± achieves competitive deletion scores, indicating improved precision in highlighting relevant features compared to CAM methods.
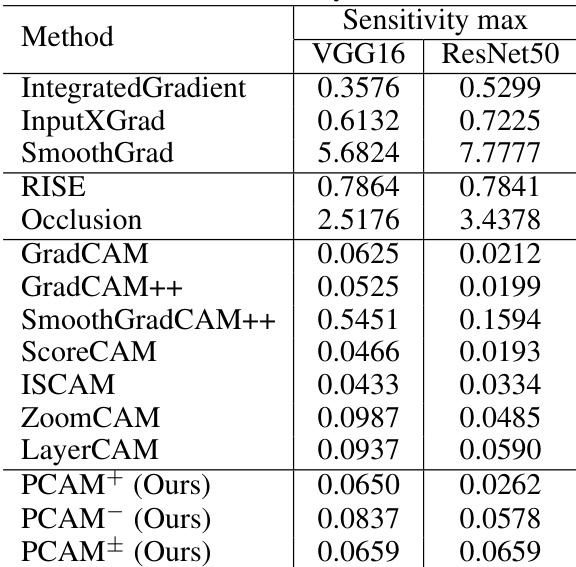
The authors evaluate the robustness of their Poly-CAM methods by comparing their sensitivity to input perturbations against several baseline methods. The results show that the proposed methods exhibit low sensitivity, comparable to other CAM-based approaches and significantly lower than gradient-based and perturbation methods. Among the Poly-CAM variants, PCAM+ and PCAM± demonstrate similar sensitivity, while PCAM- shows slightly higher sensitivity, particularly on ResNet50. The proposed Poly-CAM methods have low sensitivity to input perturbations, similar to other CAM-based methods and much lower than gradient and perturbation methods. PCAM+ and PCAM± show comparable sensitivity, while PCAM- exhibits slightly higher sensitivity, especially on ResNet50. The sensitivity of Poly-CAM methods remains low across both VGG16 and ResNet50 models, indicating consistent robustness.
The authors compare the performance of Poly-CAM variants with existing saliency methods using faithfulness metrics on VGG16 and ResNet50 models. Results show that Poly-CAM methods achieve competitive performance, particularly in insertion and deletion metrics, with the combined variant performing well across both models. The the the table indicates that Poly-CAM variants are among the top performers, with some methods showing higher insertion and lower deletion values compared to others. Poly-CAM variants achieve competitive performance in insertion and deletion metrics compared to other methods. PCAM+ and PCAM^\pm show high insertion values and low deletion values, indicating strong faithfulness. The combined variant PCAM^\pm performs well on both VGG16 and ResNet50, with high insertion and low deletion scores.
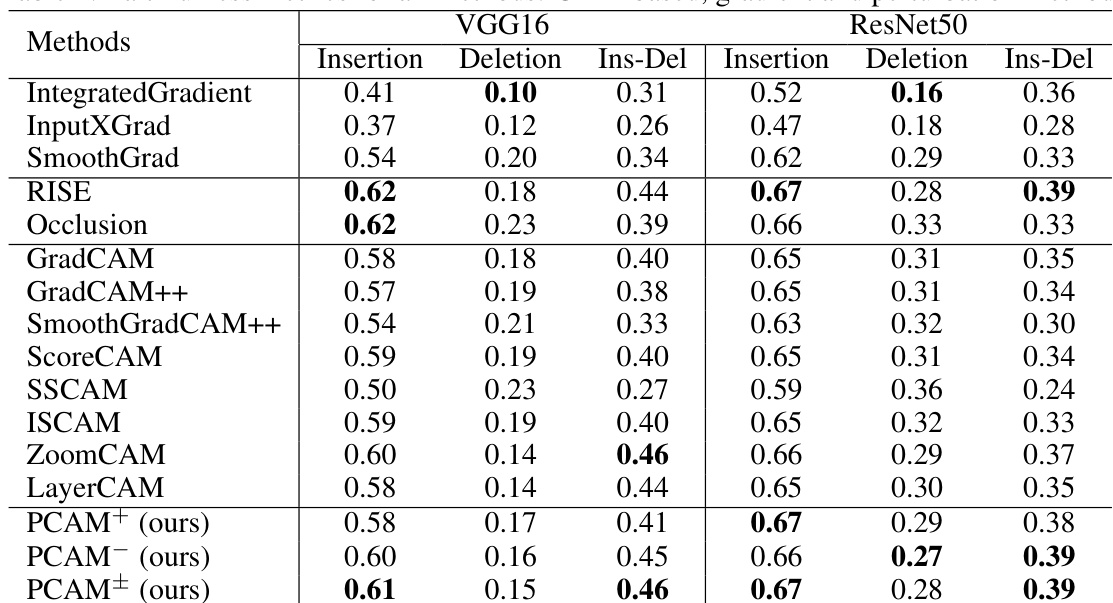
The authors compare different variants of the Poly-CAM method with traditional CAM-based approaches on VGG16, evaluating their performance across multiple layers using insertion, deletion, and insertion-deletion metrics. Results show that Poly-CAM variants generally outperform standard CAM methods, particularly in terms of insertion and insertion-deletion, with PCAM± achieving the highest scores. The performance varies depending on the layer used, with later layers generally yielding better results. Poly-CAM variants outperform standard CAM methods in insertion and insertion-deletion metrics on VGG16. PCAM± achieves the highest performance across all metrics compared to other variants. Performance improves with later layers, with the best results observed at block5_conv3.
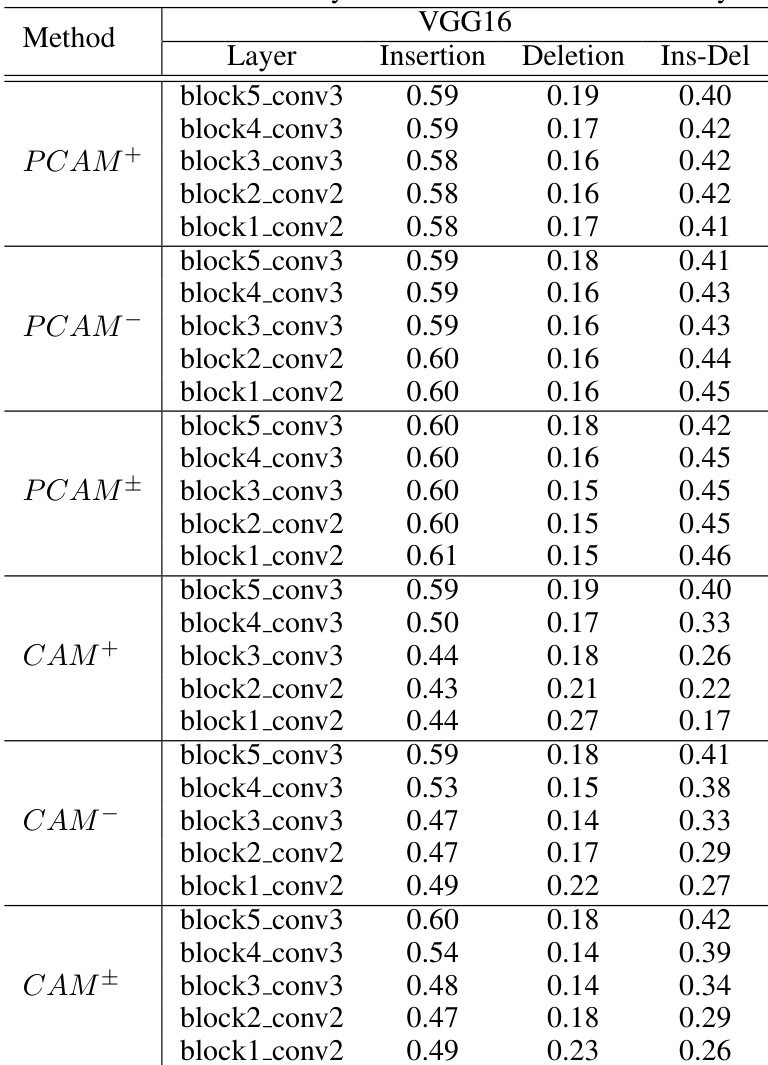
The authors compare the performance of Poly-CAM variants with several baseline methods using faithfulness metrics on VGG16 and ResNet50 models. Results show that the proposed methods achieve competitive or superior performance, particularly in insertion and deletion metrics, with PCAM+ and PCAM± performing well across both models. PCAM+ and PCAM± achieve competitive insertion and deletion performance compared to state-of-the-art methods on both VGG16 and ResNet50. The PCAM± variant shows strong performance in insertion and deletion metrics, outperforming several baseline methods on ResNet50. PCAM+ and PCAM± demonstrate consistent improvements over other CAM-based methods, especially in deletion metrics, indicating better precision in highlighting relevant features.
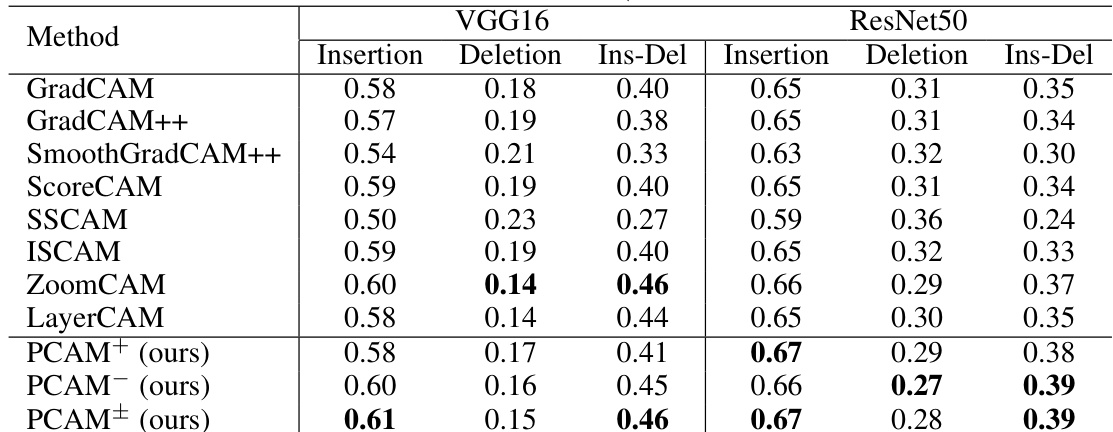
The experiments evaluate Poly-CAM variants against traditional CAM, gradient-based, and perturbation methods across VGG16 and ResNet50 architectures to validate their accuracy in feature localization and their robustness to input noise. Results indicate that the proposed methods consistently outperform baselines in identifying relevant features, with the PCAM+ and PCAM± variants demonstrating superior reliability across different network depths. The perturbation sensitivity tests further confirm that these variants maintain stable performance with minimal degradation under input variations. Overall, the study establishes Poly-CAM methods as a more precise and robust alternative for model interpretability.