Command Palette
Search for a command to run...
質問応答システム
概要
One-sentence Summary
the paper present a feature-rich system for SemEval-2016 Task 3 on Community Question Answering that achieves best results on subtask C and strong results on subtasks A and B by integrating semantic, lexical, metadata, and user-related features, with performance primarily driven by question and comment metadata, semantic vectors trained on QatarLiving data, and similarity measures between questions and comments or related questions.
Key Contributions
- This work presents a system developed for the SemEval-2016 Task 3 on Community Question Answering that integrates semantic, lexical, metadata, and user-related features.
- The approach constructs a feature set combining question and comment metadata, semantic vectors trained on QatarLiving data, and similarity scores between questions and comments or related questions.
- Evaluations achieve the top score on subtask C and strong performance on subtasks A and B, with metadata and QatarLiving-trained semantic vectors identified as the most influential components.
Introduction
Community question answering platforms rely on automatically matching questions to relevant answers or comments to improve information retrieval and reduce manual moderation overhead. Existing approaches often struggle to effectively integrate diverse signal types or fully exploit the structural context within discussion threads, which constrains their ranking and classification accuracy. The authors leverage a comprehensive feature set that combines semantic vectors, lexical cues, metadata, and user-related attributes to build a robust matching system. This feature-rich architecture achieved top performance on the SemEval-2016 Task 3 benchmark, proving that carefully engineered multimodal signals remain highly effective for community question answering while establishing a strong foundation for future thread-aware and neural extensions.
Dataset
- Dataset Composition and Sources: The authors use the SemEval-2016 Task 3 Community Question Answering dataset, provided by the task organizers and drawn from the Qatar Living Forum.
- Subset Details: Subtask A contains 6,398 questions and 40,288 comments annotated as Good, PotentiallyUseful, or Bad. Subtask B includes 317 original and 3,169 related questions labeled PerfectMatch, Relevant, or Irrelevant. Subtask C combines the 317 original and 3,169 related questions with 31,690 comments.
- Data Usage and Processing: The authors partition the dataset for training and testing across all three subtasks. They initialize semantic representations with 300-dimensional vectors pretrained on Google News and further fine-tune embeddings on 200,000 questions and two million comments from the forum. The processed data feeds directly into their ranking and classification models.
- Metadata Construction and Feature Engineering: The authors extract thread metadata by tracking comment position, author identity, length ratios relative to the question, and intra-thread user posting frequency and order. Lexical features are processed through the GATE pipeline and hand-crafted rules to capture named entities, part-of-speech statistics, readability indices, spelling and offensive word flags, and Pointwise Mutual Information scores. They also scrape supplementary user profiles to track registration dates, activity timestamps, post volumes, and troll behavior indicators, though they note these attributes yield negligible performance improvements. Auxiliary link tracking is included for both inbound and outbound references, but the authors observe that fewer than 10% of comments contain links and that these features contribute minimally to final results.
Method
The authors leverage a framework developed by Zamanov et al. (2015), which was originally designed for the SemEval-2015 Task 3 on Answer Selection in Community Question Answering. The system approaches the current task as a classification problem, adapted to a ranking scenario, where the goal is to rank answers or comments based on their relevance to a given question. This shift from classification to ranking requires a feature-rich representation that captures both lexical and semantic relationships between the question and the candidate response.
The overall architecture integrates multiple types of features, including metadata, lexical, distance-based, readability, and semantic features. Metadata features include information such as the number of posts by the same user in the thread, the ID of the question’s author, and user credibility indicators. Lexical features capture word-level statistics and patterns, while distance measures evaluate the structural proximity between the question and the comment or answer. Readability metrics are applied to both the question and the comment to assess linguistic complexity and clarity.

As shown in the figure below, a key component of the framework is the semantic feature extraction module, which aims to quantify the semantic similarity between the question and the comment or answer. This is achieved through two primary methods: topic modeling and word embedding-based representations. For topic modeling, a 100-topic model is constructed using Mallet, and the cosine distance between the topic distributions of the question and the comment is computed. This captures high-level thematic alignment between the two texts.
Additionally, the system employs word2vec-based semantic vectors to represent the meaning of words and phrases. The authors experiment with various vector training configurations, ultimately selecting vectors trained on unannotated data from the QatarLiving forum. These vectors are optimized for the forum’s language characteristics, including common misspellings and informal expressions. To enhance robustness, tokenization includes special identifiers for numbers, emoticons, URLs, and images. For each question-comment pair, the centroid vectors of the question and comment are computed, and their components serve as input features for the classifier.
The credibility of a comment or answer is further assessed using a separate module trained on a dataset of tweets. This module employs a linear Support Vector Machine (SVM) with stochastic gradient descent and L2 regularization, implemented via Apache Spark. Features used for credibility prediction include text length, presence of special punctuation, emoticons, personal pronouns (first and third person), user mentions, and URLs. The predicted credibility label and its associated probability are incorporated as additional features in the final classification pipeline.
Experiment
The evaluation employed an SVM classifier to assess a multi-feature system across three community question answering subtasks, with targeted experiments designed to validate feature importance and optimize semantic representations. Exclusion-based trials demonstrated that metadata characteristics, cross-text similarity measures, and domain-adapted semantic vectors were the most critical components, while user statistics and basic textual properties contributed minimally. Additional vector optimization experiments confirmed that training embeddings directly on forum data with domain-specific symbols and uniform word inclusion significantly enhanced predictive alignment. Overall, the findings indicate that integrating focused semantic and metadata features effectively captures community interaction dynamics, though limited testing on the related-question subtask yielded comparatively weaker performance.
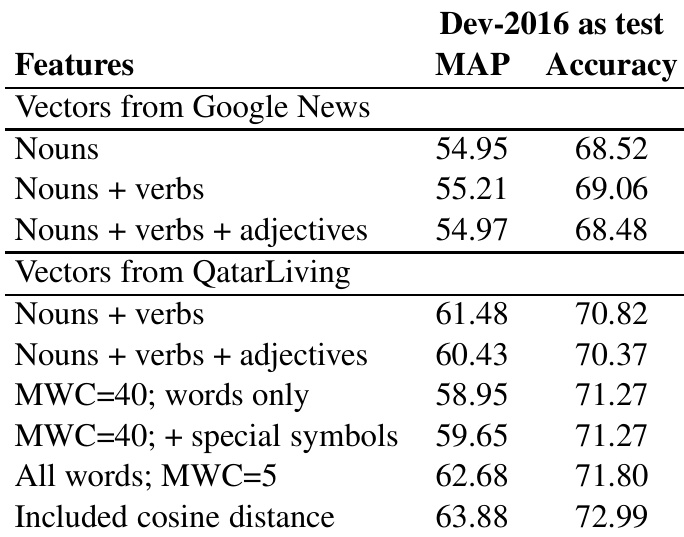
The authors compare different semantic vector approaches for feature extraction, evaluating their impact on performance using MAP and accuracy metrics. Results show that vectors trained on QatarLiving data outperform those from Google News, with specific configurations like including special symbols and using all words yielding better performance. Vectors trained on QatarLiving data achieve higher performance than those from Google News. Including special symbols as words improves the performance of semantic vectors. Using all words from all parts of speech in vector centroids yields better results than using specific parts of speech only.
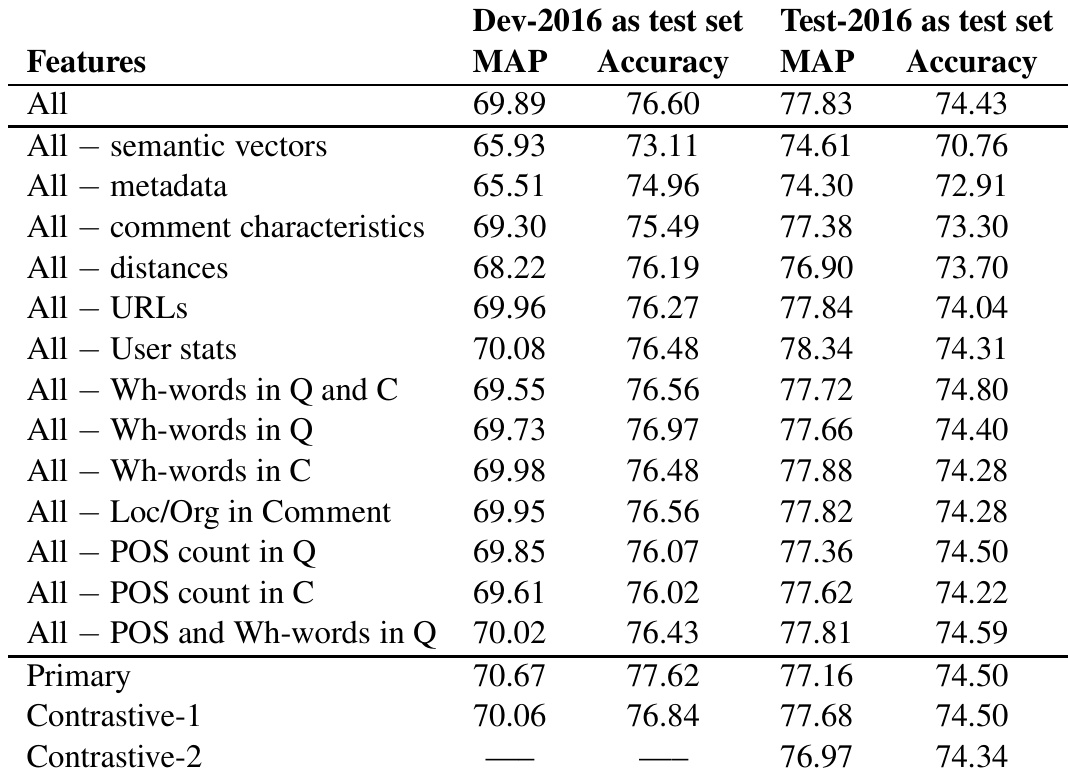
The authors conducted experiments to evaluate the impact of different feature groups on performance for a community question answering task. Results show that removing semantic vectors or metadata significantly reduces performance, while excluding other feature types has a smaller effect. The best-performing model combines all features, with the primary submission achieving strong results across both test sets. Removing semantic vectors or metadata leads to a significant drop in performance compared to using all features. Excluding other feature groups such as comment characteristics, URLs, or POS counts has a smaller impact on results. The primary model, which includes all features, achieves the highest performance on both test sets.
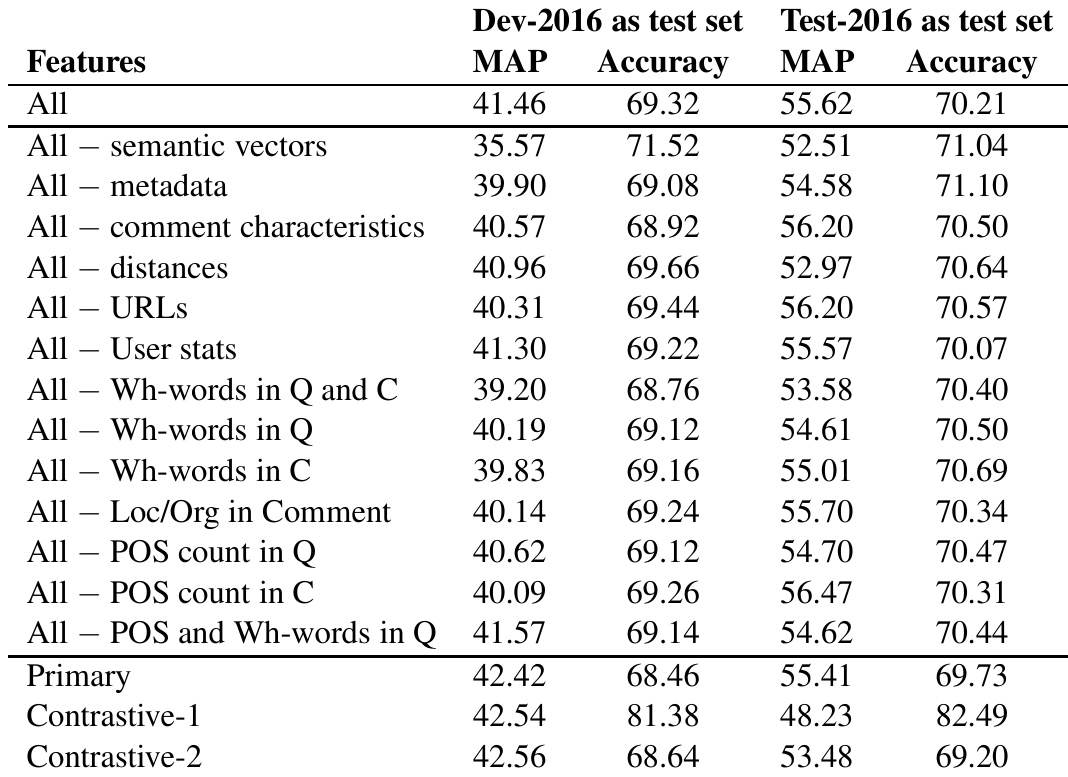
The authors evaluate the impact of different feature groups on model performance for community question answering tasks, using a series of experiments that exclude specific feature sets. Results show that semantic vectors and metadata features contribute significantly to performance, while user-related features and certain linguistic counts have minimal impact. The best-performing model combines a comprehensive set of features, with notable improvements in accuracy and MAP scores on both development and test sets. Semantic vectors and metadata features are the most impactful for model performance. Excluding user-related features and certain linguistic counts has minimal effect on results. The model combining all features achieves the highest accuracy and MAP scores on both development and test sets.
The authors evaluate the impact of different feature groups on model performance for a community question answering task. Results show that combining semantic vectors with metadata and distance measures improves performance, while removing semantic vectors leads to a drop in metrics. The best overall performance is achieved when all features are included. Combining semantic vectors with metadata and distance measures improves performance compared to using semantic vectors alone. Removing semantic vectors from the feature set leads to a decrease in both MAP and accuracy metrics. The best performance is achieved when all feature groups are included, indicating their combined importance.
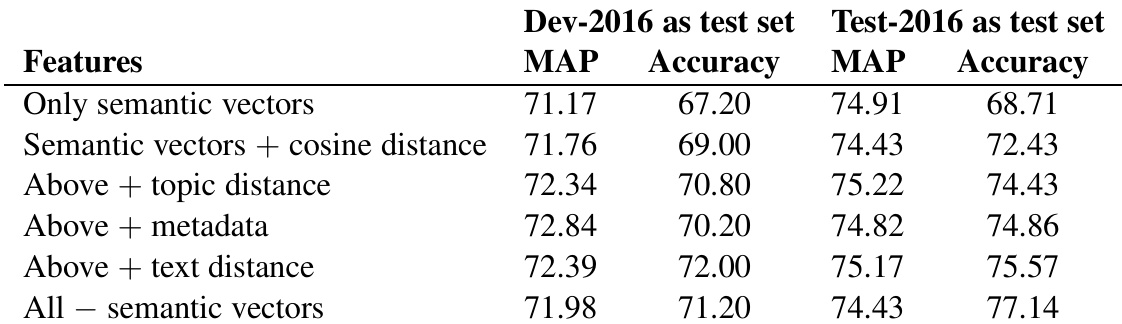
The authors evaluate the contribution of various feature groups to a community question answering task through a series of ablation and comparative experiments. These tests validate that domain-adapted semantic vectors and metadata are the most critical components, as their removal causes a substantial decline in performance, whereas user-related attributes and linguistic counts have minimal impact. Ultimately, the comprehensive integration of semantic vectors, metadata, and distance measures consistently yields the strongest results, demonstrating that combining diverse feature types is essential for optimal model performance.