Command Palette
Search for a command to run...
NLP におけるプロンプトベース学習のパラダイム - 第 1 部
概要
One-sentence Summary
This paper reviews the recent phenomenon of paradigm shifts in natural language processing, wherein pre-trained language models reformulate one task as another to improve performance and unify diverse tasks into a single model.
Key Contributions
- This work systematically reviews paradigm shifts in NLP, categorizing prompt-based, matching-based, MRC, and Seq2Seq frameworks as unified strategies that reformulate diverse tasks into single modeling pipelines.
- A comparative analysis establishes that under-explored paradigms offer distinct advantages in engineering simplicity, interpretability, and structural flexibility, while achieving competitive performance through self-supervised pre-training or language model initialization.
- Evaluations utilizing T5 and BART across structured prediction and information extraction tasks identify data hunger and autoregressive inference latency as critical bottlenecks, directing future research toward non-autoregressive and efficient decoding techniques.
Introduction
In modern natural language processing, the rapid adoption of pre-trained language models has enabled researchers to reformulate traditional tasks into alternative modeling frameworks. This paradigm shift matters because it breaks the reliance on rigid, task-specific architectures, paving the way for unified models that improve data efficiency, enhance cross-task generalization, and simplify commercial deployment. Historically, the field depended on isolated paradigms like sequence labeling or classification, which demand extensive labeled data, struggle with domain transfer, and require maintaining multiple specialized systems. The authors systematically catalog recent paradigm transfers across core NLP tasks, evaluate the unifying potential of frameworks like masked language modeling, matching, machine reading comprehension, and sequence-to-sequence models, and provide a structured analysis of their architectural trade-offs to guide future research directions.
Dataset

- Dataset Composition and Sources: The authors compile a bibliometric corpus of published NLP papers spanning 2012 to 2021. The collection covers multiple standard benchmarks and incorporates additional common tasks such as event extraction.
- Subset Details and Filtering Rules: Each NLP task is anchored to a baseline paradigm established by its original 2012 formulation. The authors filter the corpus to isolate only those papers that adopt a methodological approach different from this baseline, then group the entries by their initial and current paradigms.
- Usage and Processing: The dataset serves an analytical purpose rather than model training or mixture blending. The authors process the filtered entries by assigning an initial value of 100 to each paradigm and calculating branch weights using the formula 100 divided by N plus 1, where N represents the total number of tasks shifting away from that paradigm. These computed values drive the downstream visualization pipeline.
- Metadata Construction and Visualization: Structured metadata records task origins, target paradigms, and publication years. Complete source references are cataloged in Table 2, while the aggregated metrics feed a Sankey diagram that maps the decade long evolution of NLP methodologies. This processing highlights the growing migration from traditional frameworks like Class, SeqLab, and Seq2ASeq toward flexible approaches such as (M)LM, Matching, MRC, and Seq2Seq following the rise of pre-trained language models.
Method
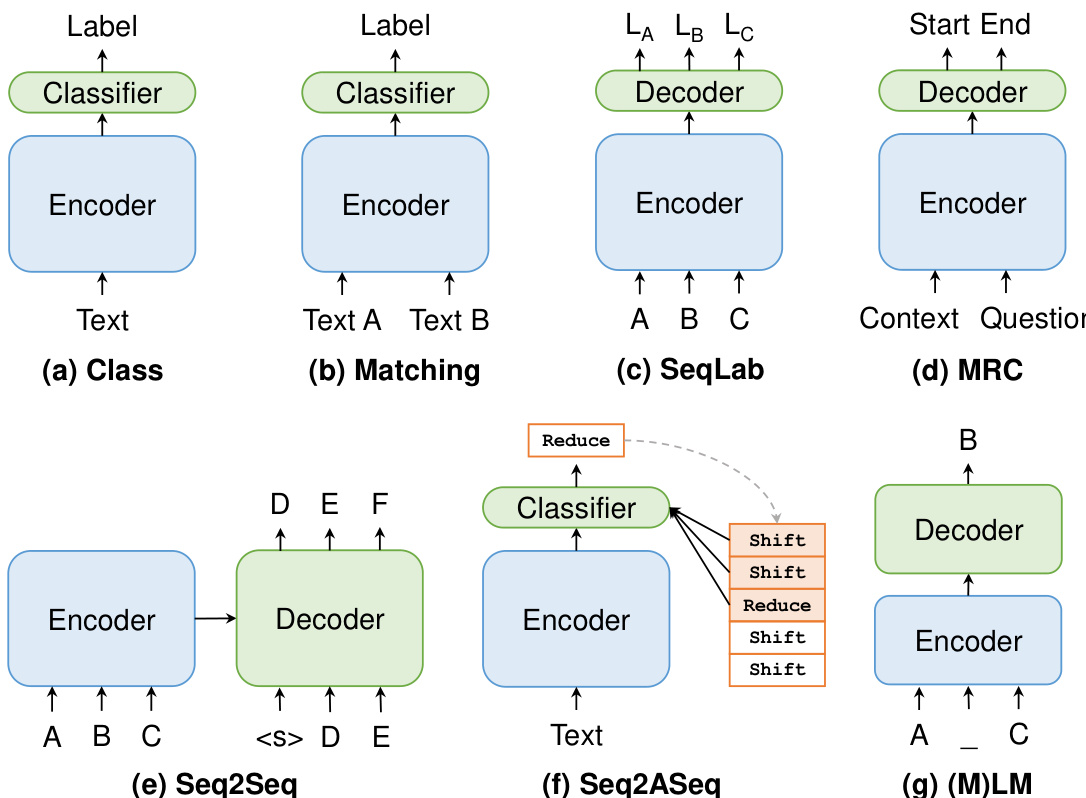
The authors leverage a modular framework to analyze and unify various natural language processing (NLP) paradigms, each defined by its distinct input structure, modeling approach, and output format. The core architecture of these paradigms consists of an encoder that processes input text into contextualized representations, followed by a decoder or classifier that generates the final output. The encoder is typically a recurrent neural network or a Transformer-based model, while the decoder or classifier adapts to the specific task requirements.
For the Class paradigm, the model processes a single text input through an encoder and passes the resulting representation to a classifier to predict a discrete label. This paradigm is commonly used for tasks such as sentiment analysis and text classification. In the Matching paradigm, two text inputs are encoded separately and then interacted with through mechanisms such as element-wise multiplication or concatenation, followed by a classifier that predicts a relationship between the inputs. This framework is applied to tasks like natural language inference and semantic similarity.
The Sequence Labeling (SeqLab) paradigm involves encoding a sequence of tokens and using a decoder to predict a label for each token in the sequence. This approach is widely used for tasks such as part-of-speech tagging and named entity recognition. The decoder often employs conditional random fields (CRF) to model dependencies between adjacent labels. The Machine Reading Comprehension (MRC) paradigm takes a passage and a question as inputs, encodes them jointly, and predicts a span from the passage that answers the question. This is typically implemented with two classifiers that predict the start and end positions of the answer span.
The Sequence-to-Action-Sequence (Seq2ASeq) paradigm is designed for structured prediction tasks, where the goal is to generate a sequence of actions that transform an initial configuration into a desired final state. This is achieved by iteratively predicting actions based on the current configuration, which may include elements such as a stack and buffer. The model encodes the input text and uses a decoder to output the action sequence, which can be used to construct structures like dependency trees.
The (M)LM paradigm reformulates downstream tasks into a masked language modeling task by modifying the input with a prompt that contains unfilled slots. The pre-trained language model fills these slots, and the output tokens are mapped to task labels through a verbalizer. This approach, known as prompt-based learning, enables few-shot and zero-shot learning by leveraging the pre-trained model's knowledge without requiring extensive task-specific training. The choice of prompt and verbalizer is crucial, and they can be designed manually, mined from corpora, or generated using other models.