Command Palette
Search for a command to run...
マルチプルチョイスタスクにおけるモデルのファインチューニング
概要
One-sentence Summary
The authors propose a few-shot learning strategy that mitigates knowledge transfer bias by selectively fine-tuning or freezing specific network layers with distinct learning rates identified via an efficient evolutionary search, achieving state-of-the-art performance on the CUB and mini-ImageNet datasets across meta-learning, non-meta frameworks, and the conventional pre-training paradigm.
Key Contributions
- The paper introduces a partial transfer framework that selectively freezes or fine-tunes specific layers of a pre-trained backbone, assigning distinct learning rates to each layer to precisely control knowledge preservation and mitigate bias from base classes.
- An efficient evolutionary search algorithm automates this adaptation by simultaneously identifying optimal layer configurations and their corresponding learning rates directly from validation accuracy without relying on proxy models.
- Extensive experiments on the CUB200-2011 and mini-ImageNet benchmarks demonstrate consistent performance improvements across both meta-learning and non-meta-based architectures, alongside stable accuracy gains in the conventional pre-training and fine-tuning paradigm.
Introduction
Few-shot learning tackles the challenge of training classifiers with minimal labeled examples, a capability that is essential for data-scarce applications like medical diagnosis and rare species tracking. Conventional transfer learning pipelines typically pre-train models on large base datasets and then either freeze the entire backbone or fine-tune all parameters for novel classes. This rigid approach struggles because base and novel classes share no overlap, causing models to either retain biased prior knowledge or overfit to the extremely limited support set. To address this, the authors leverage a partial transfer framework that selectively freezes or fine-tunes specific network layers. They introduce an efficient evolutionary search method to automatically identify the optimal layer configuration and assign distinct learning rates to each, effectively balancing prior knowledge retention with novel class adaptation. This strategy integrates seamlessly with both meta-learning and non-meta baselines, delivering consistent performance gains across standard few-shot benchmarks.
Dataset
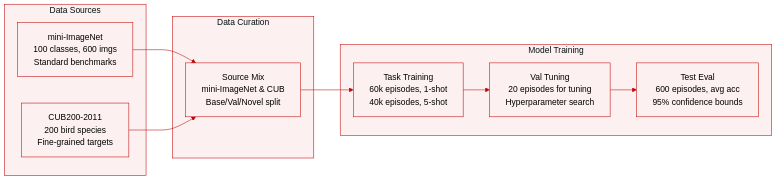
- Dataset Composition and Sources: The authors evaluate their approach using two established benchmarks. They source mini-ImageNet from ImageNet, which contains 100 classes with 600 images per class, and CUB200-2011, a fine-grained bird dataset comprising 200 species.
- Subset Details and Splits: The authors partition mini-ImageNet into 64 base, 16 validation, and 20 novel classes. They divide CUB200-2011 into 100 base, 50 validation, and 50 novel classes. This structure supports experiments in generic classification, fine-grained recognition, and cross-domain adaptation.
- Data Usage and Training Configuration: For meta-learning, the authors construct episodes by sampling five classes per task. Each episode provides k images per class for the support set and 15 images per class for the query set. They train the model on the base dataset across 60,000 episodes for one-shot tasks and 40,000 episodes for five-shot tasks. They use 20 validation episodes for hyperparameter search and measure final performance over 600 novel episodes. A non-meta baseline trains the feature extractor for 400 epochs with a batch size of 16.
- Processing and Augmentation Strategy: The pipeline applies standard data augmentation, including random cropping, horizontal flipping, and color jittering. The authors fine-tune the network on the support set for 100 iterations before evaluating on the query set. They report average accuracy alongside 95 percent confidence intervals across all evaluation runs.
Method
The authors present a framework for few-shot classification termed Partial Transfer (P-Transfer), which enables the search for optimal transfer strategies during fine-tuning of a pre-trained backbone model. The overall pipeline consists of three distinct stages: base class pre-training, evolutionary search for an optimal fine-tuning configuration, and partial transfer to novel classes using the discovered strategy. In the first stage, a feature extractor is trained from scratch on the base class dataset using a standard cross-entropy objective, as shown in the training stage of the framework diagram. This pre-trained model serves as the foundation for subsequent adaptation to novel classes. The second stage employs an evolutionary algorithm to explore the space of possible fine-tuning configurations, where different layers of the backbone may be frozen or updated with varying learning rates. The evolutionary process operates on a population of candidate strategies, evaluating each on a validation set to determine its performance, and then applying selection, crossover, and mutation to generate improved configurations over successive generations. 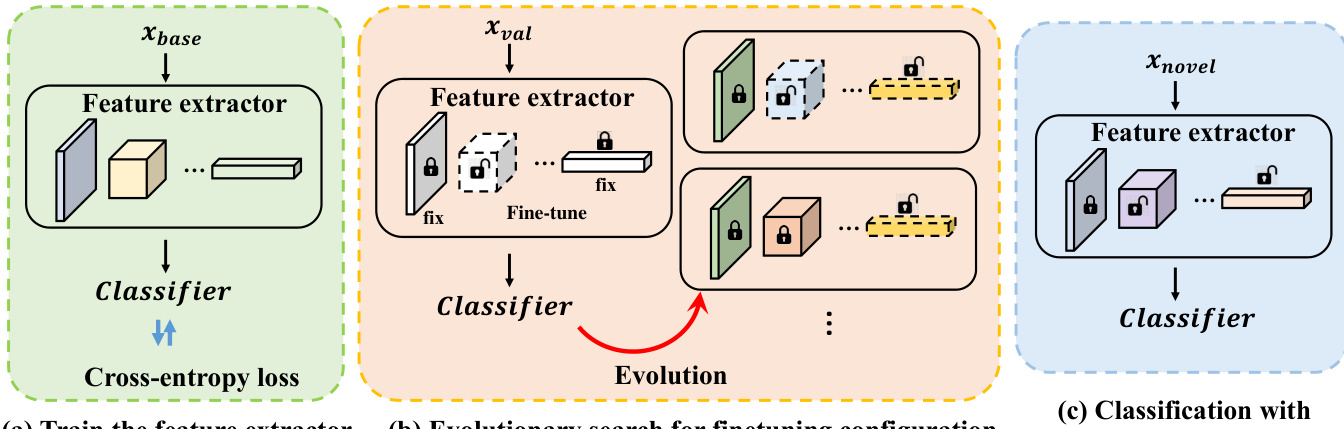
The search space for fine-tuning strategies is defined at the layer level, encompassing both the decision to freeze a layer (by setting its learning rate to zero) and the selection of a learning rate value for layers that are to be fine-tuned. This space is formalized as mK, where m represents the number of discrete learning rate choices (including zero) and K is the total number of layers in the network. For instance, with a four-element learning rate zoo {0,0.01,0.1,1.0} and a Conv6 architecture, the search space comprises 46 potential configurations. The evolutionary algorithm efficiently navigates this space to identify the optimal strategy, which is then applied in the final stage. In this stage, the pre-trained model is partially fine-tuned on the support set of the novel class using the learned configuration, and the resulting model is evaluated on the query set. This partial transfer approach, as illustrated in the fine-tuning stage of the framework, contrasts with conventional methods that either freeze the entire backbone or fine-tune all layers uniformly. 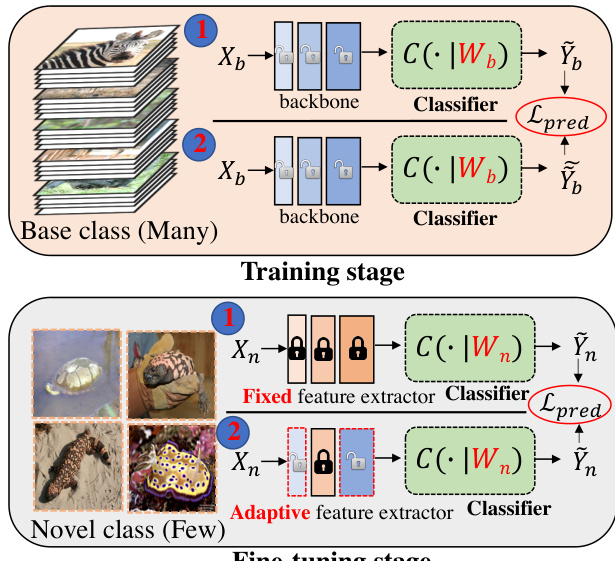
The proposed framework is designed to be compatible with both non-meta and meta-learning based few-shot classification methods. For non-meta approaches, such as the baseline++ method, the evolutionary search operates on the feature extractor fθ(x) to find an optimal configuration of learning rates for fine-tuning, while the classifier remains unchanged. This allows for an end-to-end optimization of the entire model. For meta-learning methods, such as ProtoNet, the search process is integrated into the meta-training stage, where the fine-tuning strategy is learned to optimize the model's ability to adapt to new tasks from a small support set. The framework is general enough to be incorporated into various classification pipelines, as demonstrated by the detailed illustrations of the integration with both baseline++ and meta-learning methods. 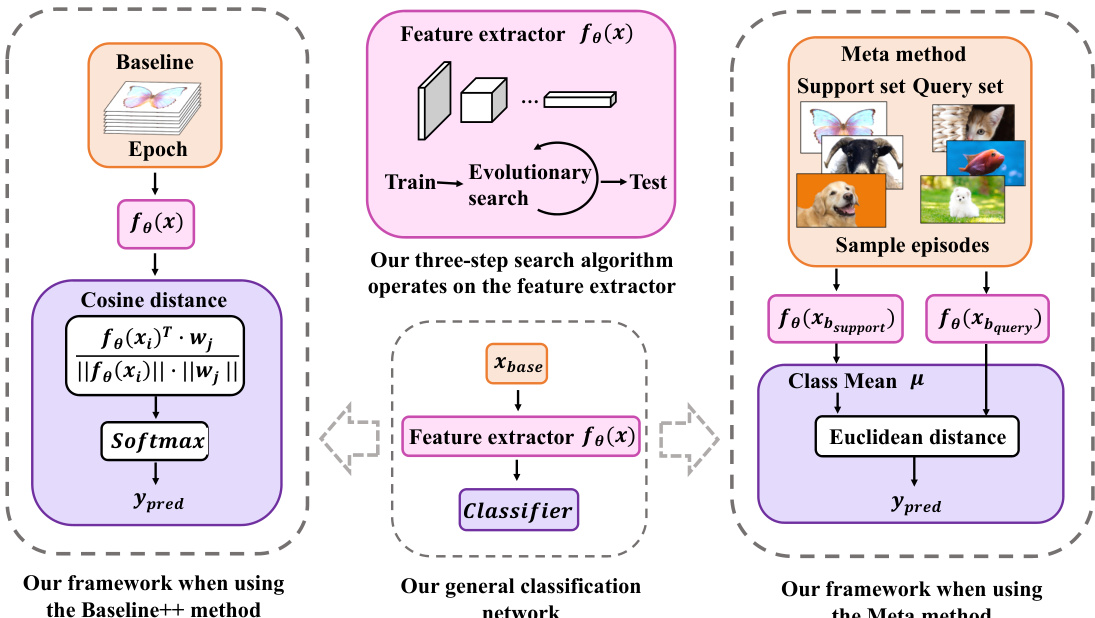
Experiment
The experiments validate the proposed evolutionary-searched fine-tuning strategy against fixed and manually designed baselines across multiple architectures, while also assessing normalization techniques and transfer strategies in cross-domain few-shot settings. Visual analysis of the learned schemes reveals that deeper networks and larger domain gaps consistently require fine-tuning a greater number of layers, confirming that flexible adaptation scales with model complexity and distribution shift. Additionally, ablation studies demonstrate that partial transfer outperforms complete weight inheritance by filtering out irrelevant base-class information, ultimately proving that search-driven fine-tuning consistently surpasses state-of-the-art methods without auxiliary training techniques.
The authors compare different fine-tuning strategies in few-shot learning, evaluating the effectiveness of fixed, manually designed, and evolutionarily searched partial transfer methods. Results show that the searched approach consistently outperforms fixed and manual strategies across various models and shot settings, with improvements observed in both 1-shot and 5-shot scenarios. The searched fine-tuning strategy achieves higher accuracy than fixed and manually designed methods across all configurations. The performance improvement is consistent across different models and few-shot settings, indicating robustness. The results demonstrate that partial transfer through evolutionary search is more effective than complete or manually selected fine-tuning in few-shot learning.
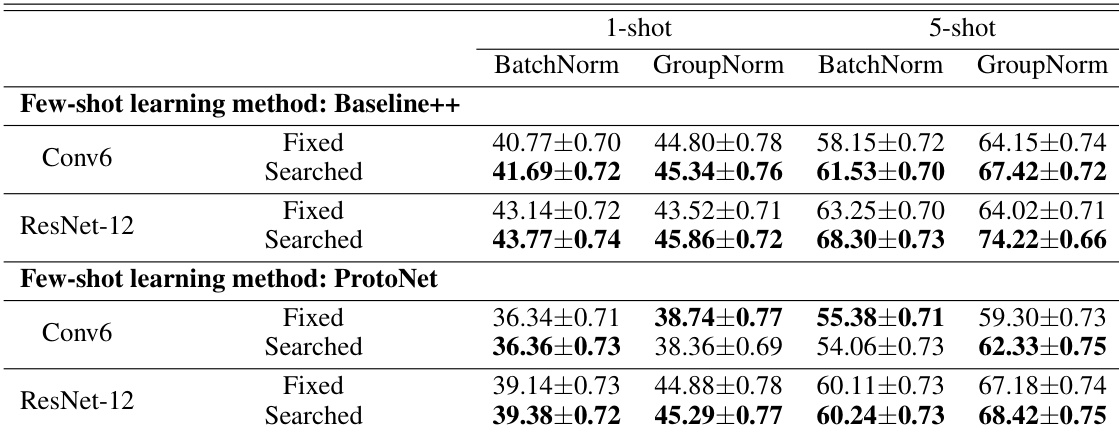
The authors compare different fine-tuning strategies in few-shot learning, including fixed, manually designed, and evolutionary-searched approaches. Results show that the searched method outperforms both fixed and manual strategies across different datasets and shot settings, with consistent improvements in accuracy. The findings suggest that selectively fine-tuning layers based on evolutionary search leads to better knowledge transfer compared to full or hand-crafted fine-tuning. The method demonstrates robust performance even without additional training techniques, highlighting the effectiveness of partial transfer. The searched fine-tuning strategy achieves higher accuracy than fixed and manual approaches across both datasets and shot settings. The evolutionary method consistently outperforms baseline strategies, indicating better knowledge transfer in few-shot learning. The results show that partial fine-tuning leads to improved performance compared to full or fixed fine-tuning, especially in cross-domain scenarios.
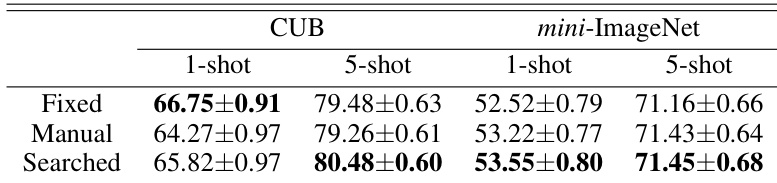
The authors compare their partial transfer method with a baseline approach that uses full transfer, showing that the partial transfer method achieves higher accuracy. The results indicate that selectively transferring knowledge from the pre-trained model leads to better performance in few-shot learning scenarios. The partial transfer method outperforms the baseline method in accuracy. Selective knowledge transfer improves performance compared to full transfer. The method achieves higher accuracy without additional training techniques.

The authors analyze the impact of network complexity on few-shot learning by comparing different architectures, including Conv6, ResNet-12, and ResNet-K. They observe that deeper networks generally require more layers to be fine-tuned, and that the complexity of the network influences the effectiveness of partial transfer methods in adapting to novel classes. Deeper networks require more layers to be fine-tuned for effective few-shot learning. Network complexity affects the performance of partial transfer methods in adapting to novel classes. The choice of network architecture influences the number of layers that need fine-tuning in few-shot scenarios.

The authors compare their proposed evolutionary search method for fine-tuning schemes against fixed and manually designed approaches in few-shot learning tasks. Results show that the searched method consistently achieves higher accuracy than both fixed and manual strategies across different models and datasets, with improvements observed in both 1-shot and 5-shot settings. The findings suggest that adaptive fine-tuning of specific layers, rather than full or fixed-layer adjustments, leads to better performance, especially when domain differences are significant. The proposed evolutionary search method outperforms both fixed and manually designed fine-tuning strategies across multiple few-shot learning methods and datasets. The searched fine-tuning schemes adapt to task complexity, with deeper networks and greater domain differences requiring more layers to be fine-tuned. The approach achieves consistent improvements over baselines without relying on additional training techniques like DropBlock or label smoothing.
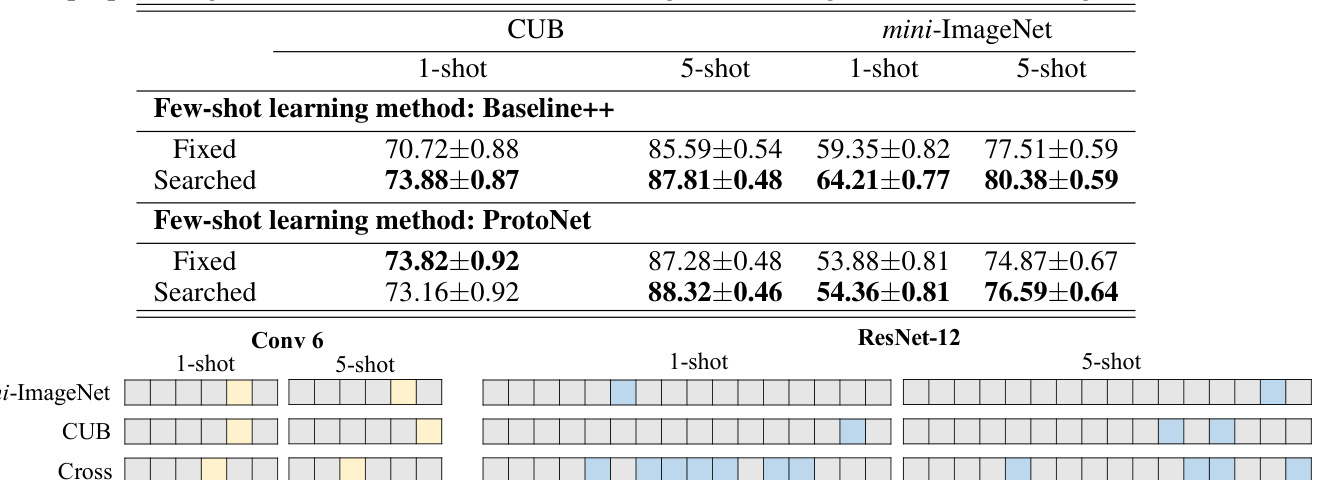
The experiments evaluate various fine-tuning strategies in few-shot learning by comparing fixed, manually designed, and evolutionarily searched partial transfer methods across multiple models, datasets, and shot settings. Results demonstrate that adaptively selecting layers through evolutionary search consistently yields higher accuracy than complete or hand-crafted approaches, validating the effectiveness of targeted knowledge transfer. Further analysis reveals that network architecture significantly influences adaptation, with deeper models requiring more extensive layer fine-tuning to handle complex tasks and domain shifts. Overall, the findings establish that evolutionary-guided partial transfer provides a robust and efficient alternative to conventional fine-tuning without relying on auxiliary training techniques.