Command Palette
Search for a command to run...
TensorFlow を用いた食品分類
概要
One-sentence Summary
Through interactive exploration of 21 food items using synchronized proprioceptive, audio, and visual sensors, the authors develop visual embedding networks trained with a triplet loss formulation that successfully improve material and shape classification performance to support material-aware robotic food manipulation planning.
Key Contributions
- A real-world dataset comprising 21 unique food items is collected through synchronized robotic interactions, capturing visual, proprioceptive, and audio signals to address the limited real-world transferability of simulation-based food property models.
- A visual embedding network trained with a triplet loss formulation fuses multimodal sensory data during training to encode material property similarities, while requiring only overhead images during inference.
- Downstream regressors and classifiers utilizing these learned embeddings consistently outperform vision-only and audio-only baselines across multiple material and shape classification tasks, demonstrating their effectiveness for material-aware robotic manipulation planning.
Introduction
The authors address the challenge of robotic food manipulation, where accurately modeling the diverse and deformable material properties of food is essential for effective physical interaction. Prior approaches often rely on computationally expensive simulations that fail to capture real-world deformations, specialized hardware, or time-consuming human annotations, while existing visual-only embedding methods overlook valuable multimodal cues. To overcome these limitations, the authors leverage a robotic platform to autonomously collect a synchronized multimodal dataset spanning vision, audio, proprioception, and force data across twenty-one food items. They then train a visual embedding network using a triplet loss formulation that integrates these interactive sensor signals during training. The resulting representations successfully encode complex material properties, enabling downstream classifiers and regressors to outperform unimodal baselines and providing a foundation for planning material-aware robotic manipulation skills.
Dataset

-
Dataset Composition and Sources: The authors collect multi-modal sensor data including RGB-D imagery, contact audio, force measurements, and proprioceptive feedback using two Franka Emika Panda robotic setups. One setup performs autonomous food cutting while the second handles post-cut manipulation. The sensor array features overhead Azure Kinect cameras, side-view Intel Realsense D435 units, custom wrist-mounted FingerVision fisheye cameras, and piezo contact microphones synchronized with ROS.
-
Subset Details: The collection spans 21 distinct food types, each processed into 10 standardized slices that vary in thickness, cutting angles, and orientation. The cutting subset captures the slicing process using Dynamic Movement Primitives derived from kinesthetic human demonstrations. The playing subset contains 5 trials per slice type, where the robot executes push, grasp, and drop actions to record material deformation. A legacy subset includes hand-cut slices collected in a separate environment. The authors note that certain angled cuts are excluded when food geometry prevents execution.
-
Data Processing and Usage: The authors organize the data hierarchically by food type, slice category, and trial number. They do not specify explicit train-test splits or mixture ratios, instead utilizing the full collection to train visual embedding networks optimized with a triplet loss formulation. These learned representations capture food material properties without explicit labels and outperform single-modality baselines across multiple evaluation tasks. The dataset also supports future applications in dynamics modeling, cooking monitoring, and manipulation policy development.
-
Metadata and Annotation: The team provides food segmentation masks for overhead and side-view imagery. Initial annotations are generated using Deep Extreme Cut on hand-labeled silhouettes. To expand coverage, the authors fine-tune a PSPNet model pre-trained on ADE20K using the manual annotations, producing additional neural network-generated masks. Audio streams are time-aligned with robot states, and every trial includes pre- and post-action RGB-D snapshots alongside gripper width recordings.
Method
The authors leverage a multi-modal unsupervised learning framework to train embedding networks for food recognition tasks. The overall approach, illustrated in the framework diagram, begins with the extraction of various feature modalities from raw sensor data. These include audio features derived from both cutting and playing actions, which are transformed into Mel-frequency cepstrum coefficients (MFCC) using Librosa and subsequently reduced via PCA to form Acut and Aplay. Proprioceptive features P are constructed from robot pose and force data, specifically capturing the final end-effector z position zf, the displacement Δz during push-down, and the final gripper width wg during grasping. These modalities, along with food class labels F and slice type labels S, serve as metrics for triplet formation.
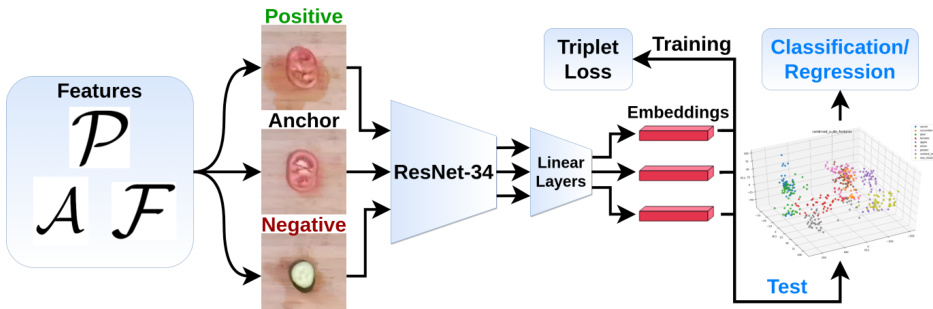
The embedding network architecture is built upon a ResNet34 backbone pretrained on ImageNet, with its final fully connected layer removed to allow for embedding extraction. This network processes input features—such as overhead images, audio, and proprioceptive data—through a series of linear layers with ReLU activation to reduce dimensionality and generate compact embeddings. The training process employs a triplet loss, where each training sample acts as an anchor, and positive samples are selected from the n nearest neighbors in the PCA feature space based on L2 distance, while all other samples serve as negatives. Triplets are formed dynamically during training to ensure the network learns to map similar instances closer in the embedding space. The learned embeddings are then used for downstream supervised tasks, including classification and regression, by feeding them into separate multilayer perceptrons. When combining multiple modalities, embeddings from individual networks are concatenated before being fed into the classifier or regressor.
Experiment
The evaluation assesses five prediction tasks using learned multimodal embeddings trained on interactive sensory data, compared against visual and audio-only baselines with leave-one-out classification to test generalization. Results indicate that while supervised visual models excel at category recognition, the proposed embeddings successfully encode relative physical and textural properties without explicit labels, enabling superior generalization to unseen food categories. Audio and proprioceptive features prove particularly effective for distinguishing material characteristics, while an auxiliary study confirms that playing audio autonomously captures structural changes like cooking. Overall, the experiments validate that interactive multimodal learning effectively captures diverse material properties for adaptable robotic food handling.
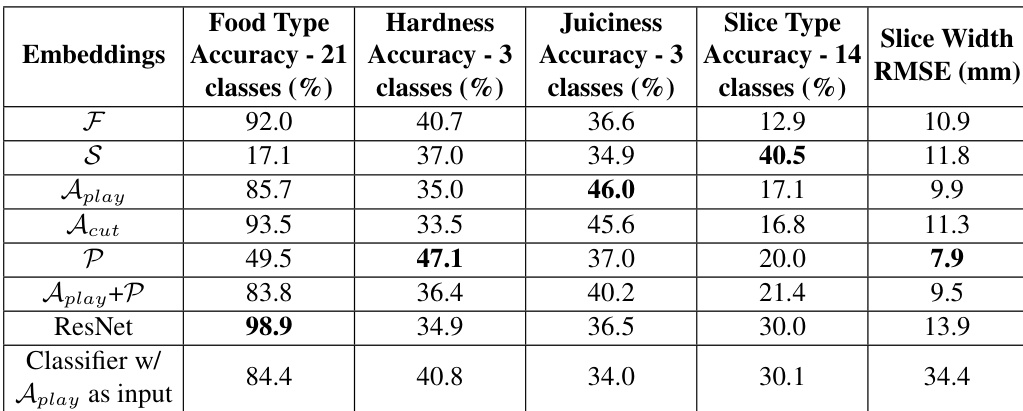
The authors evaluate multiple embedding networks trained on different modalities for predicting food properties across five tasks. Results show that certain embeddings outperform others on specific tasks, indicating that the learned representations capture relevant material properties, while a visual baseline performs well only on food type classification due to pre-training on large-scale image data. Embeddings trained with audio and proprioceptive features perform better than the visual baseline on tasks like hardness and juiciness prediction, suggesting they capture relevant physical properties. The visual baseline excels in food type classification but underperforms on other tasks, highlighting its limitation in generalizing to unseen data for non-classification tasks. Embeddings trained using slice type labels show superior performance on slice type prediction, indicating that task-specific training improves performance on that particular task.
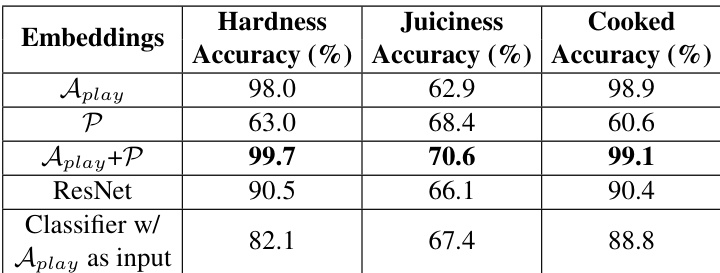
The authors evaluate various embedding networks trained on different modalities to predict food properties and classify cooked vs. uncooked states. Results show that embeddings combining audio and proprioceptive data perform best on hardness and juiciness tasks, while audio-only embeddings are effective for cooked vs. uncooked classification. The performance of different embeddings varies across tasks, indicating that each encodes specific material properties useful for distinct applications. Embeddings combining audio and proprioceptive features achieve the highest accuracy on hardness and juiciness prediction tasks. Audio-only embeddings perform well on cooked vs. uncooked classification, indicating their ability to capture material changes from cooking. Different embedding types show varying performance across tasks, suggesting they encode distinct material properties relevant to specific prediction goals.
The evaluation assesses multiple embedding networks trained on distinct modalities, including visual, audio, proprioceptive, and task-specific labels, across various food property prediction and classification tasks. These experiments validate that each representation captures unique material characteristics, as audio-proprioceptive combinations excel at estimating physical qualities, audio-only features reliably detect cooking states, and visual models remain effective primarily for food type classification. Ultimately, the results demonstrate that embedding efficacy is highly task-dependent, highlighting the importance of aligning modality selection with specific prediction objectives over relying on generalized visual baselines.