Command Palette
Search for a command to run...
デジャヴ:順序推薦のための文脈化された時間的注意機構
デジャヴ:順序推薦のための文脈化された時間的注意機構
Jibang Wu Renqin Cai Hongning Wang
ResNetとアテンション機構を備えたLSTM
概要
タイトル:文脈依存型時間的注意機構を用いた時系列レコメンデーション
抄録:過去の時系列行動に基づいてユーザーの嗜好を予測することは、現代のレコメンデーションシステムにとって重要かつ困難な課題である。既存の多くの時系列レコメンデーションアルゴリズムは、時系列行動間の遷移構造に焦点を当てているが、過去の事象が現在の予測に与える影響をモデル化する際、時間的および文脈的情報を大きく無視している。本論文では、過去の事象がユーザーの現在の行動に与える影響は、時間の経過および異なる文脈の下で変化するべきであると主張する。したがって、我々は文脈依存型時間的注意機構(Contextualized Temporal Attention Mechanism)を提案する。この機構は、行動が何であったかだけでなく、いつ、どのようにその行動が行われたかという点において、過去の行動の影響を重み付けすることを学習する。より具体的には、自己注意機構からの相対的な入力の依存度を動的に較正するために、複数のパラメータ化されたカーネル関数を導入し、様々な時間的ダイナミクスを学習する。その後、各入力に対してどの再重み付けカーネルに従うべきかを決定するために文脈情報を使用する。2つの大規模な公開レコメンデーションデータセットにおける実証評価において、本モデルは広範な最先端の時系列レコメンデーション手法を一貫して上回る性能を示した。
One-sentence Summary
Déjà vu introduces a contextualized temporal attention mechanism for sequential recommendation that dynamically weights historical interactions via parameterized kernel functions to capture time-varying and context-dependent influences, consistently outperforming state-of-the-art sequential recommendation methods on two large public datasets.
Key Contributions
- The paper introduces a Contextualized Temporal Attention Mechanism for sequential recommendation that explicitly models the time- and context-dependent influence of historical user actions. This approach replaces standard transition-focused modeling with a framework that dynamically weights past interactions based on their specific timing and contextual conditions.
- To calibrate self-attention dependencies, the model employs multiple parameterized kernel functions that capture diverse temporal dynamics. Contextual signals then select the appropriate reweighing kernel for each input, enabling adaptive adjustment of historical action impacts according to their temporal and contextual attributes.
- Empirical evaluations on two large public recommendation datasets demonstrate that the proposed framework consistently outperforms an extensive set of state-of-the-art sequential recommendation methods. These results validate the effectiveness of integrating adaptive temporal and contextual weighting into attention-based sequence modeling.
Introduction
Predicting user preferences from historical interaction sequences is a foundational challenge for modern recommender systems. While existing sequential recommendation models effectively capture item transitions, they largely overlook how temporal dynamics and contextual factors modulate the true influence of past actions. Prior approaches often rely on static time adjustments, struggle with sparse behavioral data, or fail to scale across diverse event types. To address these gaps, the authors leverage a Contextualized Temporal Attention Mechanism that dynamically recalibrates historical influence using parameterized kernel functions. By routing these kernels based on contextual signals, the model adaptively weighs past interactions according to both timing and situational factors, delivering consistent performance gains over current baselines.
Dataset
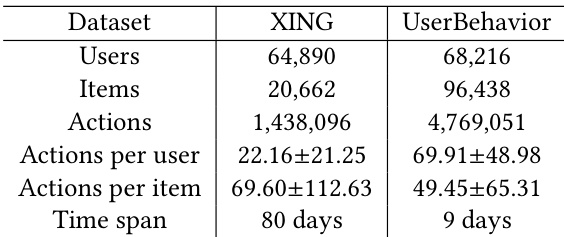
- Dataset Composition and Sources: The authors utilize two public datasets to capture user behavior across distinct application domains: a professional networking platform and an e-commerce marketplace.
- XING Subset: Sourced from the Recsys Challenge 2016 collection, this dataset tracks job posting interactions. Each entry records user ID, item ID, timestamp, and interaction type. The authors exclude "delete" actions and ignore specific interaction categories. They apply popularity thresholds by removing items with fewer than 50 actions and restricting users to between 10 and 1,000 actions. Interactions with a dwell time under 10 seconds for the same item and action type are also discarded.
- UserBehavior Subset: Provided by Alibaba, this dataset contains commercial product interactions with identical metadata fields. To ensure computational tractability, the authors randomly sub-sample 100,000 user sequences. They filter out items with fewer than 20 actions, limit user activity to between 20 and 300 actions, and remove any interactions falling outside the dataset's native 9-day temporal window.
- Processing and Model Usage: The authors clean and structure both subsets into sequential interaction records for model training. The preprocessing pipeline emphasizes temporal constraints, engagement thresholds, and dwell time validation to eliminate noise and low-quality signals. While the provided excerpt does not specify exact train-test splits or mixture ratios, the authors rely on these filtered sequences to train and evaluate their deep learning architecture, prioritizing data quality and manageable model complexity.
Method
The proposed model, Contextualized Temporal Attention Mechanism (CTA), employs a three-stage pipeline to capture content, temporal, and contextual information for sequential recommendation. The framework processes a user's historical interaction sequence of item and timestamp pairs, denoted as {(ti,si)}i=1L, along with the current prediction time tL+1. The input sequence of items is mapped to an embedding space using Einput∈RN×din, resulting in X=[s1,…,sL]⋅Einput∈RL×din. The timestamps are transformed into intervals relative to the prediction time, forming T=[tL+1−t1,…,tL+1−tL]∈RL×1. The model then processes these inputs through three sequential stages: Mα, Mβ, and Mγ, which respectively model content, temporal, and contextual dependencies.
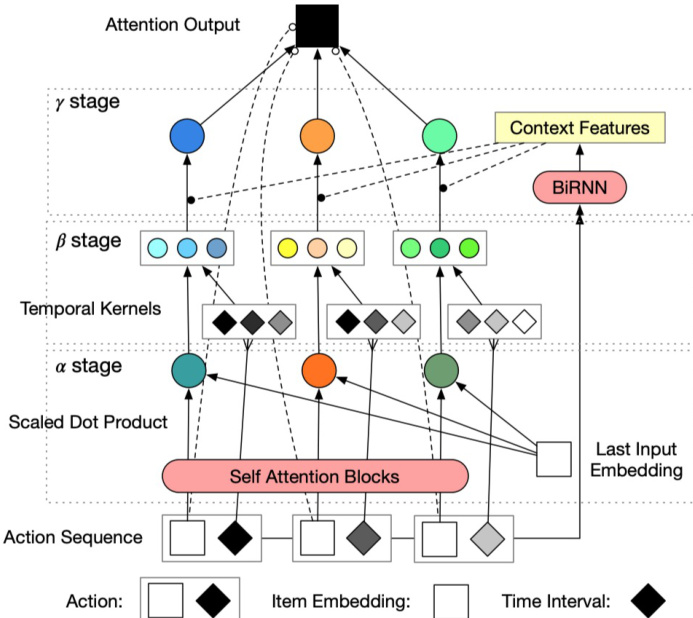
The first stage, α stage, focuses on content-based importance. It utilizes a stack of dl self-attentive encoder blocks with dh heads and da hidden units to process the input sequence X. Each attention block computes multi-head attention via scaled dot-product, where queries, keys, and values are derived from the input state Hj through learnable projections WiQ,WiK,WiV. The resulting attention heads are concatenated and projected to form Zj, which is then combined with the input via a residual connection and layer normalization to produce the next layer's hidden state Hj+1. The final hidden state Hdl is used to compute content-based importance scores α by performing a scaled dot-product attention between the last layer's hidden states and the last item's embedding, resulting in a vector α∈RL×1.
The second stage, β stage, models temporal dynamics. It applies a set of K kernel functions to the time intervals T to capture the influence of past events based on their temporal gaps. The kernels include exponential decay, logarithmic decay, linear decay, and constant functions, each parameterized by a and b. These kernels transform the raw time intervals into K sets of temporal importance scores, forming β∈RL×K, which represent different possible temporal influence patterns.
The third stage, γ stage, fuses content and temporal information based on contextual cues. It first extracts context features C∈RL×dr using a Bidirectional RNN (BiRNN) on the input item sequence X. This captures the surrounding event context from both past and future actions, reflecting the user's sensitivity and seriousness towards each interaction. Optionally, additional context features Cattr can be concatenated with the BiRNN output. A feed-forward layer FY maps the context features to a probability distribution over the K temporal kernels, which is normalized via a softmax layer to obtain P(⋅∣C)∈RL×K. This distribution is used to mix the temporal scores from the β stage, producing a contextualized temporal influence βc=β⋅P(⋅∣C). The final contextualized attention score γ is obtained by element-wise multiplication of the content score α and the contextualized temporal score βc, followed by a softmax normalization to ensure the weights sum to one. This weighted sum is then used to compute the predicted item representation x^L+1, which is projected to the output embedding space and used to compute similarity scores with all items for recommendation.
Experiment
The proposed Contextualized Temporal Attention model was evaluated on two large-scale user behavior datasets against diverse baselines with matched parameter counts to establish a fair comparative foundation. Overall performance and dataset-specific analyses validate that the model effectively bridges the gap between first-order transition and sequence popularity patterns, outperforming specialized architectures by integrating a three-stage weighing mechanism. Ablation studies and architectural tests further confirm that shared item embeddings, multi-kernel temporal modeling, and dynamic content scoring are critical components for robust performance. Finally, attention visualizations demonstrate that the network learns meaningful, non-linear temporal and contextual reweighting, ultimately proving that explicitly modeling contextualized temporal dynamics yields a highly accurate, interpretable, and efficient solution for sequential recommendation.
The authors evaluate their proposed Contextualized Temporal Attention Mechanism against a range of baseline models on two large datasets, demonstrating that their model outperforms all baselines in Recall@5 on both datasets. The results indicate that the model effectively captures sequential popularity patterns, particularly on the UserBehavior dataset, while showing limitations in modeling first-order transition patterns. The performance improvements are attributed to the model's ability to weigh historical events based on content, temporal influence, and context, with ablation studies confirming the importance of each component. The proposed model significantly outperforms all baseline methods in Recall@5 on both datasets, indicating strong effectiveness in sequential recommendation. The model's performance is particularly strong on the UserBehavior dataset, which exhibits sequence popularity patterns, and it captures long-term dependencies better than recurrent models. Ablation studies confirm that the model's three-stage weighing mechanism, incorporating content, temporal influence, and context, is crucial for its improved performance over baselines.
The authors evaluate their proposed Contextualized Temporal Attention Mechanism (CTA) against a range of baseline models on two datasets, demonstrating that CTA outperforms all baselines in Recall@5 on both datasets. The model shows strong performance on the UserBehavior dataset, where sequential popularity patterns dominate, but weaker results on the XING dataset, where first-order transition patterns are more prevalent. The ablation study reveals that the model's effectiveness relies on its three-stage weighing mechanism, with the temporal influence component being particularly crucial for capturing long-term dependencies. CTA achieves the highest Recall@5 on both datasets, outperforming all baselines. The model's performance is stronger on the UserBehavior dataset, where it captures sequential popularity, compared to the XING dataset, where first-order transitions dominate. The ablation study confirms that the temporal influence component is critical for the model's effectiveness, especially in capturing long-term dependencies.

The authors conduct an ablation study to analyze the impact of various components in their proposed model, focusing on different architectural choices and their effects on performance across two datasets. The results show that the model's performance varies significantly with changes in window size, loss function, attention settings, and the use of different temporal kernels, indicating that the design choices are task-dependent and require careful tuning. The model demonstrates robustness in capturing contextual and temporal influences, with certain configurations leading to notable improvements in ranking metrics. The model's performance is sensitive to the choice of window size, with optimal settings varying between datasets based on the underlying behavioral patterns. Using a ranking-based loss function and specific temporal kernel combinations leads to significant improvements in recommendation quality. The model effectively captures contextual and temporal influences, with the combined importance score being a dominant factor in determining event relevance.
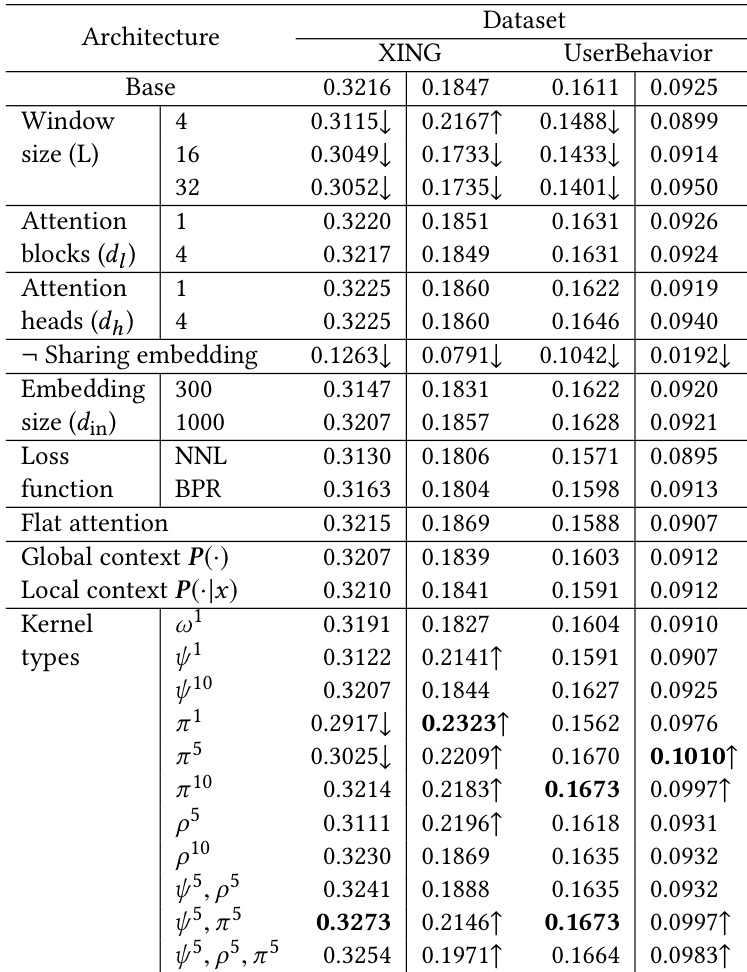
The proposed Contextualized Temporal Attention Mechanism was evaluated against multiple baselines on two datasets to assess its overall effectiveness in sequential recommendation. The experiments demonstrate that the model successfully captures long-term dependencies and sequential popularity patterns, though it shows limitations when first-order transition patterns dominate. Ablation studies validate that a three-stage weighing mechanism combining content, context, and temporal influence is essential, with temporal weighting proving particularly crucial for performance. Additionally, the results indicate that model effectiveness is highly sensitive to architectural choices, highlighting the importance of dataset-specific tuning for window sizes and loss functions.