Command Palette
Search for a command to run...
テキストをテンソルとして表現する
概要
One-sentence Summary
This paper proposes a compositional hierarchical tensor factorization that disentangles intrinsic object properties from extrinsic imaging conditions by unifying recursive wholes and parts into an interpretable framework that subsumes multilinear block tensor decomposition as a special case, yielding occlusion-robust representations that reduce training data requirements while achieving encouraging face verification results on the Freiburg and Labeled Face in the Wild (LFW) datasets.
Key Contributions
- The paper introduces a unified hierarchical tensor model that disentangles the intrinsic and extrinsic causal factors of object appearance through compositional hierarchical tensor factorization. This approach optimizes across a tree-structured hierarchy of visual wholes and parts to learn interpretable multi-level features while subsuming multilinear block tensor decomposition as a special case.
- The resulting combinatorial representation enhances recognition robustness to occlusion and significantly lowers training data requirements by bypassing the need for large-scale labeled datasets.
- Face verification experiments demonstrate the method's effectiveness on the Freiburg and Labeled Faces in the Wild (LFW) datasets using a synthetic training set containing less than one percent of the data typically required by comparable deep learning approaches.
Introduction
The authors tackle the fundamental challenge of disentangling intrinsic and extrinsic causal factors in visual data, a capability essential for robust object recognition and efficient representation. While traditional computer vision relies on either global features or local descriptors, each approach remains vulnerable to occlusion or noise. Deep learning has largely superseded these methods, yet it introduces new bottlenecks including massive data requirements, heavy computational overhead, and limited model interpretability that hinder deployment on resource-constrained hardware. To resolve these issues, the authors introduce a compositional hierarchical tensor factorization framework that treats input data as a structured tree of wholes and parts. This mathematical model simultaneously optimizes across all hierarchical levels to learn interpretable convolutional features and generate a combinatorial object representation that is inherently robust to occlusion. The resulting approach dramatically reduces training data needs while offering a principled method to compress and improve the generalization of existing neural networks.
Dataset
-
Dataset composition and sources: The authors represent observational data as a general tensor D that can be recursively decomposed into wholes and parts. Rather than drawing from a specific public benchmark, the framework is designed to process any multi-dimensional data exhibiting hierarchical structure, whether composed of partially overlapping children, non-overlapping components, or fully overlapping segments.
-
Key details for each subset: Data is partitioned into segments Ds using a filter bank {Hs}. Each filter is a 2D convolutional operator implemented as a doubly or triply block circulant matrix, and the complete bank sums to the identity matrix. These segments capture varying overlap relationships between parent wholes and child parts, enabling flexible structural representation across different data modalities.
-
How the paper uses the data: The authors organize the segmented data into a hierarchical data tensor DH with individual segments placed along its super-diagonal. This structure supports compositional hierarchical tensor factorization to model intrinsic and extrinsic causal factors. The authors optimize a reconstruction objective with orthogonality regularization, initializing the process via the M-mode SVD of the hierarchical tensor before applying truncation for dimensionality reduction.
-
Cropping strategy and processing details: Segmentation functions as the primary cropping mechanism, applied through convolutional filtering along the measurement mode. When a filter matrix acts as a block identity, it extracts data portions without introducing blurring, subsampling, or upsampling. The authors note that perceptual parts may not align perfectly with vectorized inputs, requiring trivial permutations to achieve proper chunking. All processing relies on mode-n products to yield a part-based causal factorization that isolates independent computations for non-overlapping segments.
Method
The proposed method introduces a compositional hierarchical tensor factorization designed to disentangle the hierarchical causal structure underlying object image formation, particularly for visual recognition tasks. The framework operates on a higher-order data tensor D, where each observation corresponds to a vectorized image, and the tensor's modes represent the various causal factors of data formation, such as person, view, illumination, and expression. The core of the approach is a unified tensor model of wholes and parts, which re-conceptualizes the data tensor into a hierarchical structure that explicitly models the recursive composition of perceptual wholes and their constituent parts.
The model's architecture is built upon a hierarchical data tensor DH, which is decomposed into a core tensor ZH and a set of mode matrices Ucx for each causal factor c. The decomposition is expressed as D=ZH×0U0x×1U1x⋯×CUCx. This formulation allows the model to represent an image as a combinatorial choice of representations from both the whole and its constituent parts, enabling a hierarchical disentanglement of intrinsic and extrinsic causal factors. The hierarchical structure is designed to be robust to occlusions, as it can represent an object's appearance based on its visible parts rather than relying on a single global representation.
The training process involves an iterative optimization algorithm, Algorithm 2, which alternates between solving for the mode matrices and the core tensor. The optimization is based on minimizing a loss function that measures the reconstruction error of the data tensor. For each mode c, the optimal mode matrix Ucx is computed by solving the equation ∂e/∂Ucx=0, which yields a closed-form solution involving the pseudo-inverse. The core tensor ZH is then updated by solving a linear system derived from the vectorized form of the reconstruction error. This alternating least squares approach ensures convergence to a local minimum of the objective function.
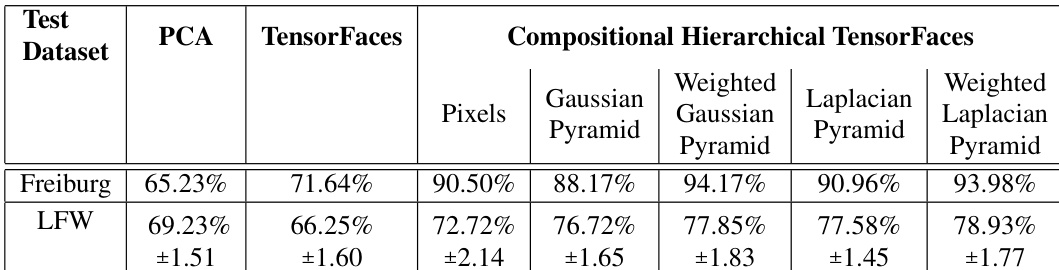
The method is demonstrated in the context of face recognition, where the data tensor is constructed from synthetic images of faces under various lighting and viewing conditions. The resulting facial representations are interpretable and hierarchical, allowing for the disentanglement of factors such as illumination and viewpoint. The model's ability to learn from a reduced dataset of synthetic images and achieve robust performance on real-world datasets like LFW and Freiburg underscores its suitability for data-starved domains. The compositional nature of the factorization allows the model to represent facial features at multiple scales and resolutions, enhancing its ability to handle variations in image appearance.