Command Palette
Search for a command to run...
音声翻訳における音声認識誤り分析のための音韻論的指向単語誤りアライメント
音声翻訳における音声認識誤り分析のための音韻論的指向単語誤りアライメント
Nicholas Ruiz Marcello Federico
ワンクリックで Whisper-large-v3-turbo をデプロイ
概要
音声認識評価に一般的に用いられる単語誤り率(WER)指標のバリエーションを提案する。本手法は、時間境界情報が存在しない状況下で音素の整列を統合する。参照および仮説トランスクリプト内の単語に対してレーベンシュタイン整列を計算した後、隣接するエラーの範囲を単語および音節境界付きの音素に変換し、音素ベースのレーベンシュタイン整列を実行する。得られた音素整列情報は、各エラー領域における単語整列ラベルの補正に用いられる。我々は、本手法による音素指向単語誤り率(POWER)が、WERと同等のスコアを生成しつつ、より良好な単語整列および音声認識仮説における同音異義エラーに対応する一対多の整列を捉える能力という追加の利点を持つことを実証する。これらの改善された整列により、音声翻訳などの下流タスクに対する音声認識におけるレーベンシュタインエラータイプの影響をより詳細に追跡することが可能となる。
One-sentence Summary
The authors propose the Phonetically-Oriented Word Error Rate (POWER), a WER variation that applies phonetic Levenshtein alignment within word error spans to correct alignment labels and capture homophonic mappings, producing scores comparable to standard WER while enabling more accurate tracing of recognition errors for downstream speech translation analysis.
Key Contributions
- This work introduces the Phonetically-Oriented Word Error Rate (POWER), a speech recognition evaluation metric that integrates phoneme-level alignment to resolve ambiguities in standard Levenshtein word alignment without requiring temporal boundary information.
- The method converts adjacent word error spans into phonemes using a text-to-speech text analysis component, executes a phonetic Levenshtein alignment, and applies the resulting mappings to refine word-level error labels within each affected region.
- Experimental evaluation demonstrates that POWER maintains standard Word Error Rate scores while producing more accurate word alignments, identifying homophonic one-to-many errors, and generating refined error distributions that enhance downstream speech translation analysis.
Introduction
Spoken language translation systems typically chain independent automatic speech recognition and machine translation models, making it critical to understand how speech recognition mistakes propagate into translation quality. Traditional evaluation relies on the Word Error Rate metric, which categorizes mistakes using standard Levenshtein alignment. This conventional approach frequently ignores phonetic and linguistic relationships, often misaligning content words and failing to detect homophonic errors that span multiple tokens. To overcome these limitations, the authors leverage a text-to-speech pronunciation dictionary and letter-to-sound rules to compute a phonetically oriented alignment for adjacent recognition errors. This revised method produces linguistically accurate error distributions, enabling more reliable pre-ASR text normalization and precise downstream analysis of how recognition mistakes impact translation performance.
Dataset
- Dataset Composition and Sources: The authors utilize automatic speech recognition hypothesis data, compiling error statistics from their experimental runs to analyze transcription mistakes that affect downstream processing.
- Key Subset Details: Errors are grouped into distinct categories, with closed class word insertions and deletions representing roughly 16.2% of total mistakes. Substitution spans make up the remaining frequent errors, typically stemming from homophonic confusions where the system selects phonetically similar word sequences.
- Data Usage and Processing: The team applies this error breakdown to train recovery models and evaluate statistical language translation experiments. They employ the POWER framework during development to accurately mark unaligned words, ensuring reliable training signals for insertion and deletion handling.
- Additional Processing and Metadata: Instead of relying on cropping or explicit metadata generation, the authors focus on extracting substitution spans and mapping phonetic error patterns. This approach enables model rescoring or preserves sequence ambiguity so downstream components can resolve similar sounding alternatives.
Method
The authors leverage a phonetically-oriented alignment approach to enhance the traditional Word Error Rate (WER) metric by incorporating phonetic information during the error analysis process. The framework begins with a standard Levenshtein alignment on the word level between reference and hypothesis transcripts. Following this, spans of adjacent errors—defined as sequences containing at least one substitution—are segmented into phonemes using word and syllable boundaries. This phonetic segmentation enables a second Levenshtein alignment to be performed at the phoneme level, which captures phonetic confusability and resolves ambiguities in word-level alignments. The resulting phonetic alignment information is then used to refine the original word-level alignment, particularly in error regions, to produce more accurate substitution, deletion, and insertion labels.

As shown in the figure below, the alignment process is visualized through a dynamic programming matrix where the optimal path is determined based on edit operations. The matrix tracks the cost of insertions, deletions, and substitutions, with arrows indicating transitions between states. The figure illustrates how phoneme-level alignment can resolve ambiguities in word-level alignments by considering phonetic similarity. For example, the alignment path reflects a substitution between "ao" and "ae" based on phonetic proximity, which is then used to refine the word-level error labels. This approach ensures that substitutions are correctly identified even when they involve homophonic or phonetically similar words, which are often misclassified as deletions or insertions in standard WER.
The phonetically-oriented alignment process is further refined using heuristics to resolve ambiguities in cases where multiple optimal paths exist. Specifically, the algorithm minimizes the number of gaps between the first and last word boundaries in both the reference and hypothesis by encoding the back-track paths into an edge-weighted graph and applying Dijkstra’s algorithm to select the most plausible alignment. Additionally, to prevent overzealous assignment of substitution labels to single-syllable words lacking phonetic correspondence, the method checks whether extra syllables correspond to the beginning of a new word, thereby correctly classifying them as deletions or insertions.
The final Phonetically-Oriented Word Error Rate (POWER) is computed using a formula nearly identical to WER, defined as:
POWER=LS+D+I+SS,SS=span∑max(∣spanref∣,∣spanhyp∣),where L is the length of the reference, S, D, and I are the counts of substitution, deletion, and insertion errors, respectively, and SS represents the weighted count of substitution spans, with each span weighted by the maximum number of words in the reference or hypothesis. This formulation accounts for one-to-many or many-to-many alignments, which are indicative of phonetic confusability and contribute to more accurate error modeling.
Experiment
The experiments evaluate speech-to-text translation using a corpus of TED talk utterances processed by multiple ASR systems and a baseline translation model. The first experimental set validates that traditional alignment metrics frequently misclassify complex recognition issues like homophony and multi-word substitutions, whereas a linguistically informed approach yields a more accurate error distribution. The subsequent analysis measures how these refined error categories impact downstream translation quality, revealing that within-class substitutions and substitution spans are the primary drivers of performance degradation. Ultimately, the study concludes that frequency-weighted, linguistically aware error analysis provides a more reliable framework for understanding and addressing the specific speech recognition flaws that hinder machine translation.
The authors compare the impact of ASR error types on translation quality using two alignment methods, WER and POWER, by analyzing mixed-effects models. Results show that substitution spans identified by POWER have a significant effect on translation errors, with different error types contributing variably to translation degradation depending on the alignment method. POWER-based alignment identifies substitution spans as a significant predictor of translation quality, which are not captured by WER. The impact of insertion errors on translation quality increases when using POWER alignment compared to WER. Within-class substitution errors are the most influential in terms of frequency-weighted contribution to translation degradation.
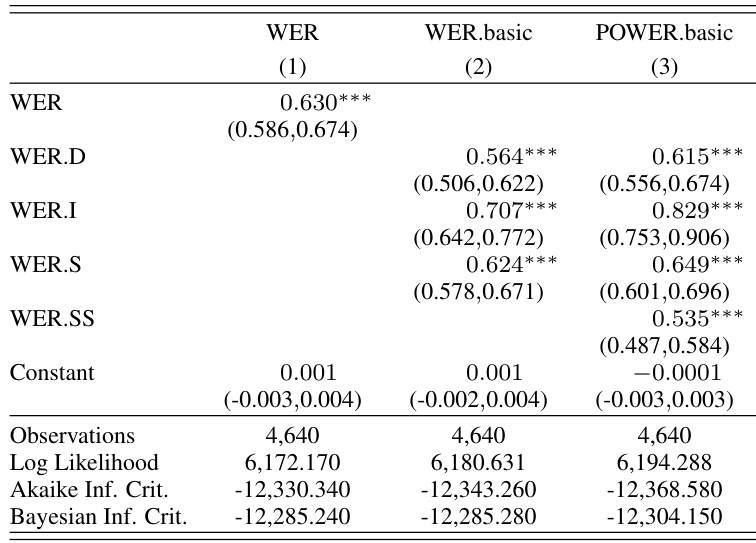
The authors analyze ASR error types and their impact on downstream translation quality using two alignment methods, WER and POWER. Results show that POWER provides a more nuanced error classification, particularly in identifying substitution spans and reducing the perceived impact of insertion and deletion errors. The analysis reveals that certain error types, especially those involving open-class words, have a greater influence on translation performance. POWER alignment reduces the reported impact of insertion and deletion errors compared to WER, highlighting more accurate error classification. Substitution errors involving open-class words contribute significantly to translation quality degradation. Substitution spans with multiple hypothesis words are common and have a notable impact on translation performance.
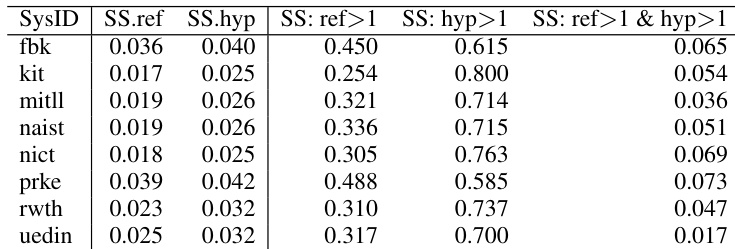
The authors analyze ASR error types and their impact on downstream translation quality using mixed-effects models. Results show that substitution errors, particularly those involving open-class words and substitution spans, have the most significant influence on translation degradation, with POWER-based alignment providing more accurate error classification than WER. Substitution errors involving open-class words and substitution spans are the most impactful on translation quality. POWER-based alignment identifies more accurate error types, especially for substitution spans, compared to WER. Within-class substitutions and substitution spans with open-class reference words contribute most significantly to translation error increases.
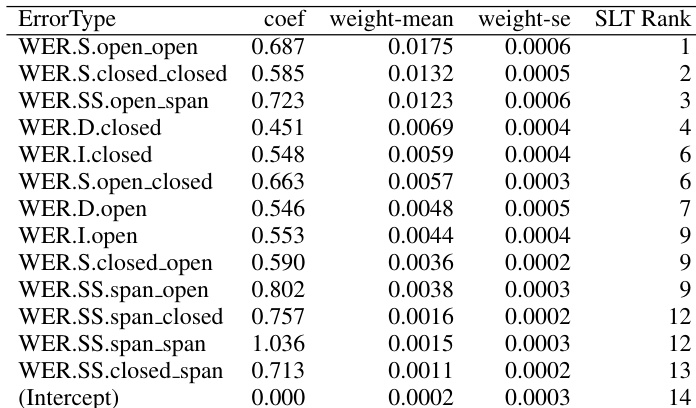
The authors compare error type distributions from two alignment methods, WER and POWER, using ASR hypotheses and reference data from the IWSLT 2013 evaluation. Results show that POWER provides a different error classification, particularly reducing the frequency of insertions and deletions while increasing the relative importance of substitution spans and certain word-class-specific errors. The analysis reveals that error types involving open class words and substitution spans have a stronger impact on downstream translation quality. POWER alignment reduces the reported frequency of insertions and deletions compared to WER, while increasing the relative importance of substitution spans. Substitution errors involving open class words and substitution spans are more impactful on translation quality than other error types. The contribution of ASR errors to translation quality varies significantly based on word class and alignment method, with POWER revealing more nuanced error patterns.
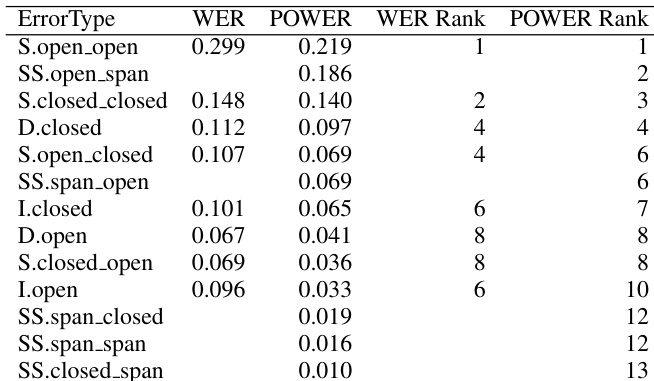
The authors analyze ASR errors and their impact on downstream translation tasks using two alignment methods, WER and POWER, to compare error distributions and their effects on translation quality. Results show that different alignment techniques lead to varying error type distributions and that certain error types, particularly those involving open-class words and substitution spans, have a significant impact on translation performance. POWER alignment reduces WER scores and provides a different distribution of error types compared to WER, particularly reducing the reported number of insertions and deletions. Substitution errors involving open-class words and substitution spans are identified as major contributors to translation quality degradation. The impact of ASR errors on translation is more accurately captured when using POWER-aligned error types, especially for substitution spans and open-class substitutions.
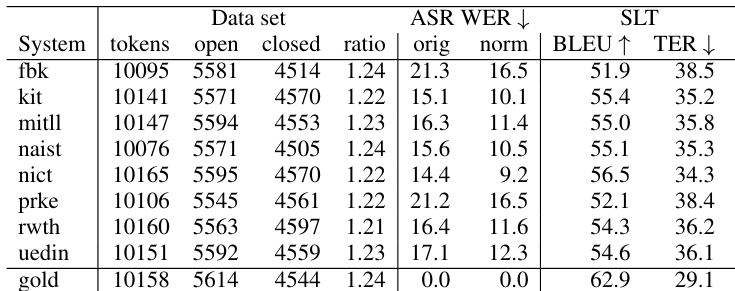
The experiments evaluate the impact of automatic speech recognition errors on downstream translation quality by comparing traditional WER alignment against a more nuanced POWER alignment method using mixed-effects modeling. The analysis validates that POWER provides a refined error classification that downplays insertions and deletions while emphasizing substitution spans. Qualitatively, substitution errors involving open-class words emerge as the most significant drivers of translation degradation, demonstrating that error impact varies substantially depending on both word class and alignment methodology. Ultimately, POWER alignment offers a more accurate assessment of how specific speech recognition mistakes compromise translation performance compared to standard metrics.