Command Palette
Search for a command to run...
深層 CNN を用いた画像のカラー化
概要
One-sentence Summary
By randomly pruning 25-50% of filters from VGG-16 and ResNet-50 architectures, this work demonstrates that deep convolutional networks recover performance through inherent plasticity rather than structured ranking criteria, achieving competitive classification accuracy, a 74% frames-per-second speedup in Faster R-CNN object detection, and comparable SegNet segmentation results on a custom ImageNet benchmark.
Key Contributions
- The experiments demonstrate that pruned network performance recovery stems from the inherent plasticity of deep neural networks rather than specific importance-ranking criteria, enabling a simple random pruning strategy to remove 25 to 50 percent of filters while maintaining accuracy after fine-tuning.
- Extensive evaluations on VGG-16 and ResNet-50 validate this finding, and a new ImageNet-derived benchmark for class-specific pruning is introduced to show that random filter removal consistently matches state-of-the-art performance on restricted test sets.
- The methodology extends to object detection and image segmentation, achieving a 74 percent fps improvement for Faster R-CNN with preserved accuracy and maintaining comparable performance for SegNet.
Introduction
Deep convolutional neural networks deliver state-of-the-art results across computer vision tasks but impose heavy computational and memory demands that hinder deployment on resource-constrained devices. Filter pruning has emerged as a practical compression strategy to slash inference costs, yet prior approaches heavily rely on heuristic scoring metrics to rank and discard filters. The field generally assumes that post-pruning performance recovery validates these metrics, but it overlooks broader recovery dynamics and remains largely confined to image classification. The authors leverage this gap to demonstrate that deep networks recover pruned weights primarily through inherent plasticity rather than optimal scoring criteria. They show that randomly discarding twenty-five to fifty percent of filters yields performance comparable to advanced criterion-based methods across classification, object detection, and segmentation tasks. Additionally, they introduce a new benchmark for class-specific pruning and provide a comprehensive evaluation framework that measures damage, recovery speed, and data efficiency.
Dataset

-
Dataset Composition and Sources: The authors construct two benchmarks from the ImageNet repository. The baseline is ImageNet-1000, the original 1,000-class dataset. They also create ImageNet-52P, a custom subset designed to align with the 20 categories in Pascal VOC.
-
Subset Details and Filtering Rules: ImageNet-52P contains exactly 52 ImageNet classes that correspond to the Pascal VOC categories. The authors manually curated this subset by selecting only the immediate hyponyms of each Pascal VOC class and discarding overly fine-grained subclasses. Both datasets retain the standard train, validation, and test splits from ImageNet. The training split is strictly non-overlapping with the test and validation sets. Exact image counts are not specified, but the class composition serves as the main differentiator.
-
Data Usage and Training Protocol: The authors use ImageNet-1000 to train baseline networks and ImageNet-52P to evaluate class-specific pruning. During the pruning workflow, fine-tuning after each layer and at the final stage exclusively uses the ImageNet-52P training data. This setup allows them to compare a model trained on all 1,000 classes against a pruned model optimized for just the 52 target categories.
-
Processing and Evaluation Details: No image cropping or metadata construction is applied. The primary processing involves the manual class mapping, split extraction, and a fixed 25% filter pruning ratio. Model performance is measured on the ImageNet-52P test split to demonstrate that targeted pruning can match the accuracy of a network trained from scratch on the smaller dataset.
Method
The authors leverage a generic algorithmic framework for filter pruning in convolutional neural networks (CNNs), which is designed to systematically reduce model complexity while preserving performance. The overall methodology begins with a formal definition of the pruning task: given a CNN with K convolutional layers, where the kth layer contains nk filters, the objective is to rank all filters {Fk1,Fk2,…,Fknk} and retain only the top-mk filters—where mk<nk is a hyperparameter determined by computational constraints. This pruning reduces both the number of computations within the layer and the spatial dimensions of the output feature map, which in turn reduces the input size to the subsequent layer. The process is applied iteratively across all layers, with fine-tuning performed after each pruning step to recover lost accuracy.
As shown in the figure below, the framework operates in a layer-by-layer manner, beginning from the outermost layer and proceeding inward. At each layer, a scoring function is applied to compute an importance score for every filter. These scores are then used to select the top-mk filters, which are retained while the rest are pruned. The pruned network is subsequently fine-tuned for p epochs to adapt to the reduced architecture. After all layers have undergone pruning and fine-tuning, the entire network is further fine-tuned for q epochs to ensure convergence and optimal performance.
The effectiveness of the pruning process hinges on the choice of scoring function, which determines the ranking of filters. The authors review several existing criteria and introduce new variants. The mean activation criterion measures the average activation of a filter’s output across the training set; filters with low mean activation are considered less important due to their infrequent activation under ReLU. The l1-norm of a filter’s weights is another criterion, where smaller norms suggest less influence on the network output. Entropy-based criteria assess the informativeness of a filter’s output by measuring the distribution of its activations across bins; higher entropy indicates more diverse and potentially useful responses. The average percentage of zeros (APoZ) quantifies sparsity in the feature map, with higher zero percentages indicating lower filter importance. Sensitivity is computed via the l1-norm of the gradient of the loss with respect to the filter, capturing how much each filter affects the final prediction.
The authors propose a novel variant called scaled entropy, which combines entropy with mean activation to penalize filters that produce high-entropy but low-activation outputs. This is defined as SEi=−∑j=1bpijlogpij⋅Meani, where Meani is the average activation of the ith filter. Additionally, a class-specific importance criterion is introduced for scenarios where the model is to be used for a subset of the original classes. This approach computes filter importance by averaging the gradient norm only over images belonging to the target classes, thereby prioritizing filters relevant to those classes. Finally, the authors demonstrate that even random pruning, when followed by fine-tuning, yields performance comparable to structured pruning methods, challenging the assumption that importance-based ranking is essential for effective pruning.
Experiment
Evaluations across image classification, object detection, and segmentation tasks using standard convolutional architectures validate that random pruning consistently matches the performance, recovery speed, and fine-tuning efficiency of sophisticated, criteria-based methods. Further experiments confirm that pre-training larger networks before pruning significantly outperforms training smaller models from scratch, while targeted pruning of decoder layers can yield beneficial regularization effects that surpass baseline performance. Collectively, these findings demonstrate that pruned networks maintain remarkable robustness when transferred to entirely new tasks, ultimately establishing random pruning as a highly effective and computationally efficient alternative to complex pruning heuristics.
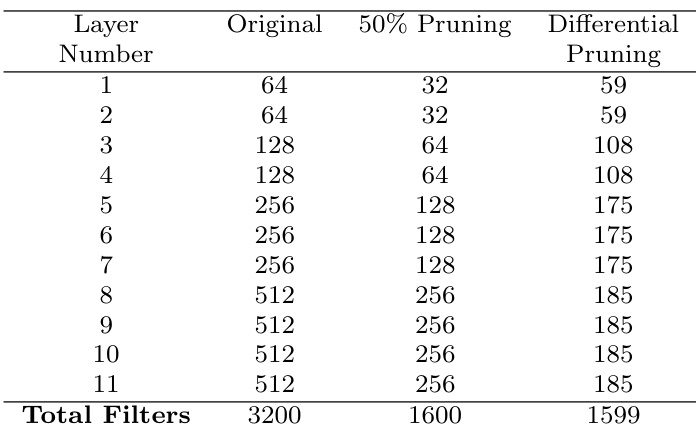
The the the table presents a comparison of filter pruning strategies applied to a VGG-16 network, specifically comparing standard 50% pruning with a differential pruning approach that adjusts the pruning ratio based on the number of filters in each layer. The results show that the total number of filters is reduced in both cases, but the differential pruning strategy retains more filters in lower layers and prunes more in higher layers, leading to a slightly higher total number of retained filters. The performance of the pruned networks is evaluated in the context of recovery after fine-tuning, where the differential pruning strategy shows a marginal improvement in accuracy. Differential pruning retains more filters in lower layers and prunes more in higher layers compared to uniform 50% pruning. The total number of filters retained under differential pruning is higher than under uniform 50% pruning. The differential pruning strategy results in a slight improvement in network accuracy compared to uniform 50% pruning.
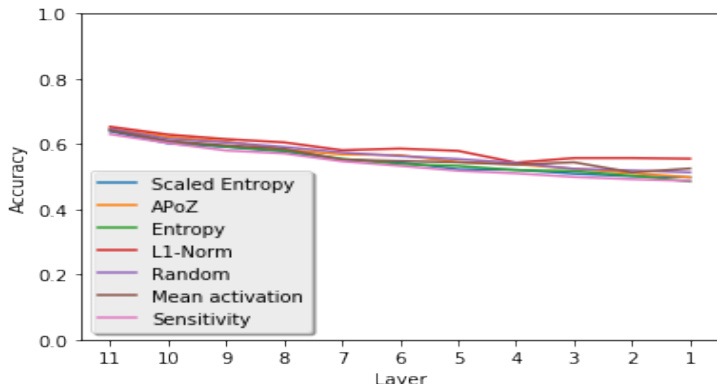
The authors compare various filter pruning strategies on a VGG-16 network for image classification, evaluating performance after pruning and fine-tuning. Results show that random pruning achieves performance comparable to more principled methods like l1-norm, with minimal differences in accuracy across different pruning percentages and strategies. The findings suggest that the recovery after pruning is not significantly influenced by the choice of pruning criteria, and that random pruning is as effective as structured approaches in maintaining network performance. Random pruning achieves performance comparable to structured pruning methods like l1-norm across different pruning percentages. The amount of recovery after pruning is similar across all strategies, indicating that random pruning is not inferior to principled methods. Pruning strategies have minimal impact on final performance when using fine-tuned networks, regardless of the initial damage caused by pruning.
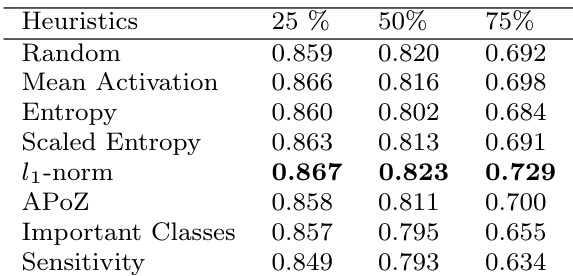
The authors compare various filter pruning strategies on a VGG-16 network, evaluating performance after pruning and fine-tuning at different levels of sparsity. Results show that random pruning performs similarly to or better than principled methods across different pruning ratios, with minimal differences in recovery and speed of recovery. The findings suggest that the choice of pruning strategy has little impact on final performance when sufficient fine-tuning is applied. Random pruning achieves comparable performance to principled pruning methods across different sparsity levels. The amount of recovery after pruning is similar across all strategies, indicating that final performance is not significantly influenced by the pruning criterion. The speed of recovery and the amount of data required for fine-tuning are comparable for all pruning methods, with random pruning performing as well as more sophisticated strategies.
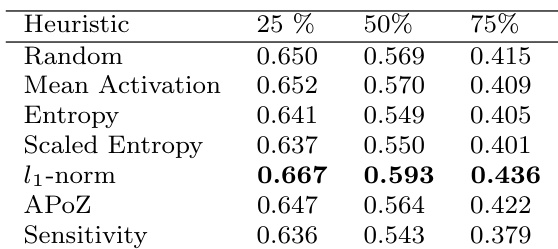
The authors compare different filter pruning strategies on VGG-16, focusing on performance after pruning and fine-tuning across varying levels of compression. Results show that random pruning performs comparably to principled methods like l1-norm, with similar recovery, speed of recovery, and data requirements, indicating that the choice of pruning strategy has minimal impact on final performance. The findings extend to other tasks such as object detection and image segmentation, where random pruning also yields robust results. Random pruning performs as well as principled methods like l1-norm in terms of recovery and performance after fine-tuning. The choice of pruning strategy has minimal impact on the final performance across different compression levels and tasks. Random pruning achieves comparable results to other methods in object detection and image segmentation tasks, even when applied to different network components.
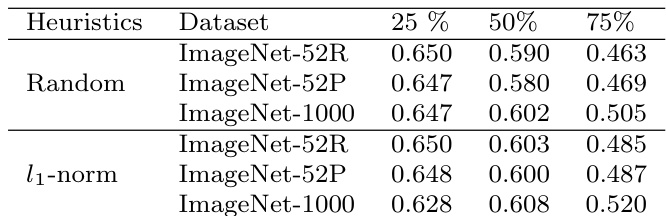
The authors compare different filter pruning strategies on a VGG-16 network, evaluating their performance after pruning and fine-tuning. The results show that random pruning achieves performance comparable to more principled methods like l1-norm, with minimal differences in recovery and speed of recovery. The findings suggest that the choice of pruning strategy has little impact on final performance when sufficient fine-tuning is applied. Random pruning performs as well as principled methods like l1-norm in terms of final performance after fine-tuning. The speed of recovery and amount of data required for fine-tuning are comparable across different pruning strategies. The choice of pruning strategy does not significantly affect performance, indicating that recovery is not dependent on the initial pruning criteria.
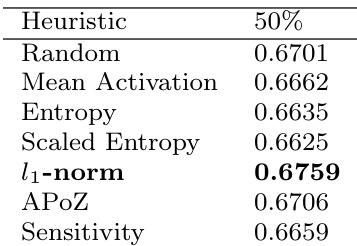
The experiments evaluate various filter pruning strategies, including random, uniform, differential, and l1-norm methods, on VGG-16 and related vision tasks to validate whether the initial pruning criterion significantly affects network recovery and post-fine-tuning accuracy. The results demonstrate that random pruning performs comparably to structured approaches, with negligible differences in final accuracy, recovery speed, and fine-tuning data requirements across varying compression levels. Ultimately, the findings indicate that the choice of pruning method has minimal impact on overall performance, as sufficient fine-tuning effectively restores network capabilities regardless of the selection strategy.