Command Palette
Search for a command to run...
定期血液検査を用いた冠動脈性心疾患の予測
定期血液検査を用いた冠動脈性心疾患の予測
Ning Meng Peng Zhang Junfeng Li Jun He Jin Zhu
冠動脈疾患予測
概要
本研究の目的は、定期血液検査結果と冠動脈疾患(CHD)リスクとの関連を検討し、それらを冠動脈疾患予測モデルに組み込み、このアプローチの識別性能を他の予測関数と比較することである。本研究は、病院ベースのコホートを対象とした後向き・単施設研究として設計された。ベースライン時の年齢が1〜97歳で、2009年から2017年までの8年間の医療記録、5051件の健康診断、および5075件の他の疾患の症例を有する5060人のCHD患者(男性2365人、女性2695人)を対象とした。我々は、定期血液データに基づいて冠動脈疾患のリスクを予測するための2層勾配ブースティング決定木(GBDT)モデルを開発し、これにより冠動脈疾患を有する人の86%を同定することができた。15,000件の定期血液検査結果からなるデータセットを構築した。このデータセットを用いて、2層GBDTモデルを訓練し、健康状態、冠動脈疾患、および他の疾患を分類した。機械学習による分類の結果、全データにおける健康データの検出感度は約93%であり、冠動脈疾患を含む疾患データにおけるCHDの検出感度は93%であった。この結果に基づき、定期血液検査結果と関連データ項目との相関を可視化し、全データ表示において健康状態および冠動脈疾患に明らかなパターンが存在することを確認した。このパターンは臨床的な参考として活用可能である。最後に、上記の結果を病理生理学の観点から簡潔に分析した。定期血液データは、検査結果と関連データ項目との相関を通じて我々が既に把握している情報よりも、CHDに関するより多くの情報を提供している。GBDTアルゴリズムを用いた単純な冠動脈疾患予測モデルを開発した。このモデルにより、顕著なCHDを呈していない患者のCHDリスクを医師が予測できるようになる。
One-sentence Summary
Drawing on 15,000 routine blood test results, this study develops a two-layer Gradient Boosting Decision Tree (GBDT) model that classifies healthy status, coronary heart disease, and other conditions with approximately 93% sensitivity, demonstrating the clinical utility of routine blood markers for CHD risk prediction.
Key Contributions
- A two-layer Gradient Boosting Decision Tree (GBDT) model is developed using a dataset of 15,000 routine blood test records to classify healthy status, coronary heart disease, and other diseases. This framework enables early risk stratification by processing standard hematological markers.
- The algorithm achieves approximately 93% sensitivity for general health classification and identifies 86% of coronary heart disease cases within the evaluated cohorts. These performance metrics demonstrate the predictive utility of routinely collected laboratory data.
- Correlations between specific hematological indices, including platelet distribution width and red cell distribution width, and coronary pathology are visualized and analyzed. This investigation reveals distinct physiological patterns that differentiate healthy cohorts from diseased patients and supports pathophysiological interpretation.
Introduction
Coronary heart disease imposes a significant global health burden, yet early detection remains difficult because conventional diagnostics like angiography only reveal advanced pathology. Existing clinical risk scores frequently fail to identify high-risk individuals, particularly younger patients, due to their dependence on specialized lipid panels, clinical assessments, or genomic testing that are often costly or inaccessible. To bridge this gap, the authors leverage widely available routine blood test data to train a two-layer Gradient Boosting Decision Tree model that classifies health status and predicts coronary heart disease risk with approximately 93 percent sensitivity. By correlating specific hematological markers with underlying pathophysiological mechanisms such as chronic hypoxia, systemic inflammation, and coagulation dysregulation, the team delivers a low-cost, automated screening framework that empowers clinicians to initiate preventative interventions earlier.
Dataset
- Dataset Composition and Sources: The authors compiled clinical records from 16,860 patients enrolled across eastern China, extracting information from outpatient systems, inpatient examination logs, and routine health check databases. The cohort was initially divided into three diagnostic categories: coronary heart disease, other diseases, and a healthy population.
- Subset Details and Labeling: The initial breakdown included 5,060 CHD patients, 5,075 patients with other diseases, and the remaining healthy individuals. Original labels assigned a value of 1 to CHD, -1 to other diseases, and 0 to healthy subjects. After quality control steps reduced the pool to 15,033 records, the authors randomly sampled 5,000 cases from each group to establish a strictly balanced 1:1:1 mixture.
- Data Processing and Feature Engineering: Raw inputs were standardized, including binary conversion of gender categories. High sparsity was addressed by first dropping rows with missing values, then imputing remaining gaps using group-specific averages. Clinical outliers were filtered using domain-specific rules. The final feature matrix combined demographic basics with 22 standardized blood routine indices, such as white blood cell count, hemoglobin levels, platelet parameters, and differential cell percentages.
- Training Strategy and Model Usage: The authors structured the analysis into a two-layer classification pipeline. The first layer separated healthy subjects from all diseased patients using a 10,000 record subset split into 70 percent training and 30 percent validation. The second layer isolated CHD from other diseases by removing healthy records and applying the same 70/30 partition to the remaining 10,000 cases. The balanced data was evaluated across logistic regression, support vector machines, and gradient boosting decision trees, with GBDT selected as the optimal model following grid search tuning (learning rate of 0.23 and 70 estimators).
Method
The authors leverage a two-layer Gradient Boosting Decision Tree (GBDT) classification model to perform low-cost risk assessment for coronary heart disease (CHD) using blood routine data. The model is designed to classify patients into high-risk and low-risk categories based on a large dataset of clinical cases. The overall framework consists of two sequential stages, where the first layer performs an initial classification, and the second layer refines the prediction using a subset of features, thereby enhancing the model's discriminative capability. Each layer is composed of multiple decision trees, with the construction of each tree involving feature selection based on a specified metric. Features that are selected closer to the root node of the tree and split more frequently are considered more important, reflecting their higher contribution to classification accuracy.
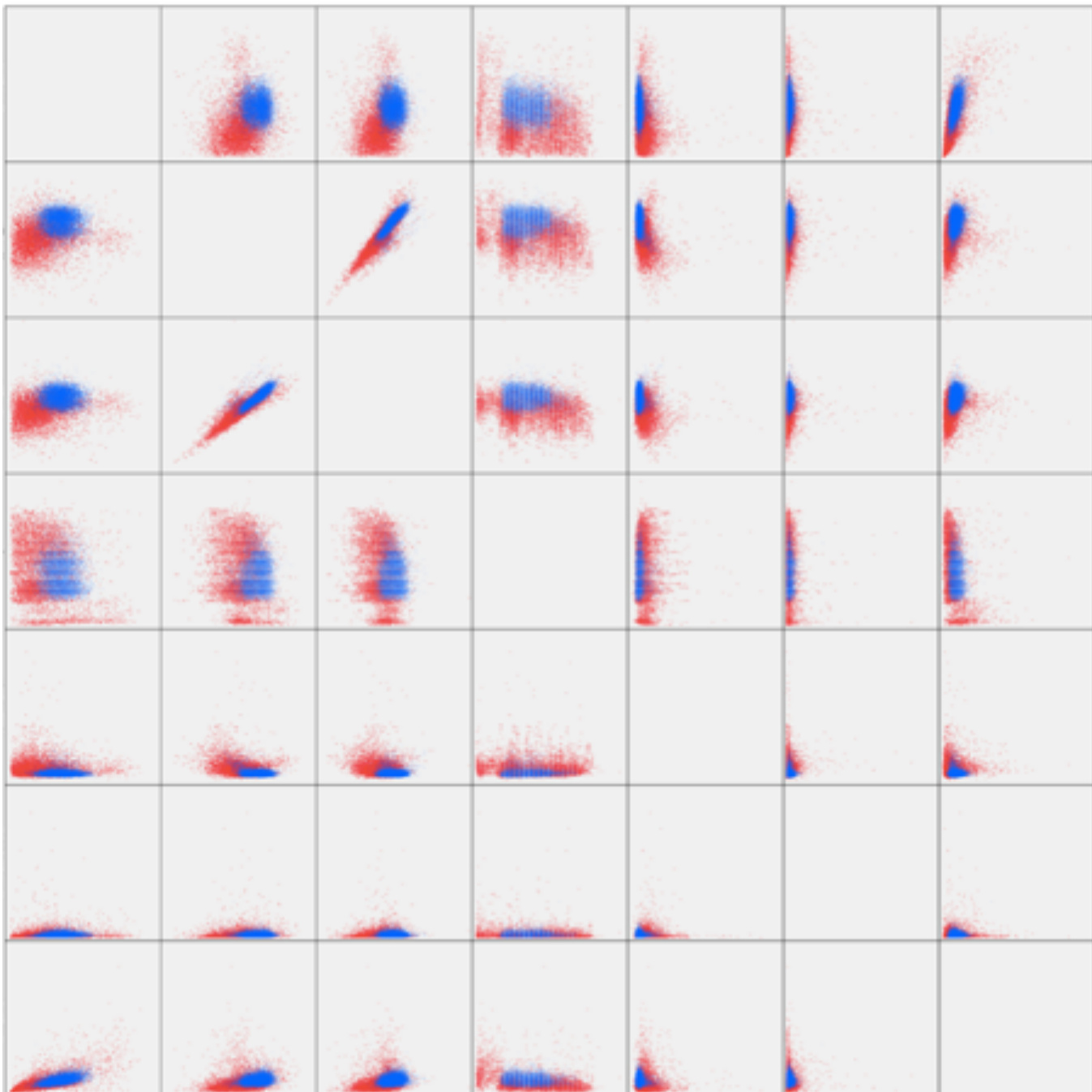
As shown in the figure below, the authors conduct a correlation analysis using the selected features with the highest contribution in both layers—LY%, HCT, RBC, age, RDW, BASO%, and LY—based on feature importance rankings. The scatter plot illustrates the aggregation effect of healthy individuals and CHD patients, with blue dots representing the healthy population and red dots representing CHD patients. The separation between the two groups is evident, indicating that the selected features effectively capture distinguishing patterns between the populations. The visualization also reveals that the healthy population exhibits a tighter aggregation, which aligns with the model's higher recall rate for healthy individuals (91%) compared to CHD patients (86.5%).
Refer to the framework diagram, which presents a visual representation of the relationships among all features in the blood routine data. The authors connect the features with dashed lines to illustrate the complex interdependencies and clustering patterns. The plot distinguishes between healthy individuals (green), CHD patients (red), and other diseases (blue), with clear separation between green and red clusters. This confirms the model's classification performance and provides insight into the underlying data structure, demonstrating that the selected features form distinct groupings that support the model’s predictive decisions.
Experiment
The evaluation employs a two-layer gradient boosting decision tree model trained on routine blood test data to classify individuals into healthy, coronary heart disease, and other disease categories. This experimental design validates both the predictive equivalence of hierarchical versus direct classification and the interpretability of clinical biomarkers by systematically mapping data associations to underlying physiological mechanisms. Qualitative analysis confirms that the framework effectively distinguishes disease states while revealing clear, clinically relevant patterns that align with known pathophysiological processes. Ultimately, the study concludes that routine blood tests provide sufficient structural information to support accurate risk stratification and meaningful clinical interpretation.
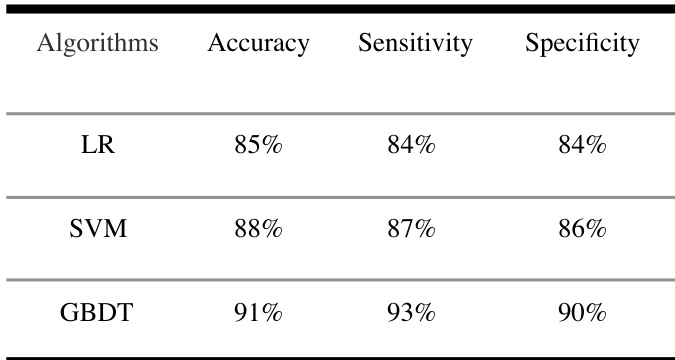
The authors compare the performance of different machine learning algorithms, including logistic regression, SVM, and GBDT, using a dataset of routine blood test data. Results show that the GBDT algorithm achieves higher accuracy, sensitivity, and specificity compared to the other two models. GBDT outperforms LR and SVM in terms of accuracy, sensitivity, and specificity. The GBDT algorithm demonstrates the highest sensitivity among the compared models. SVM shows better performance than LR across all evaluation metrics.
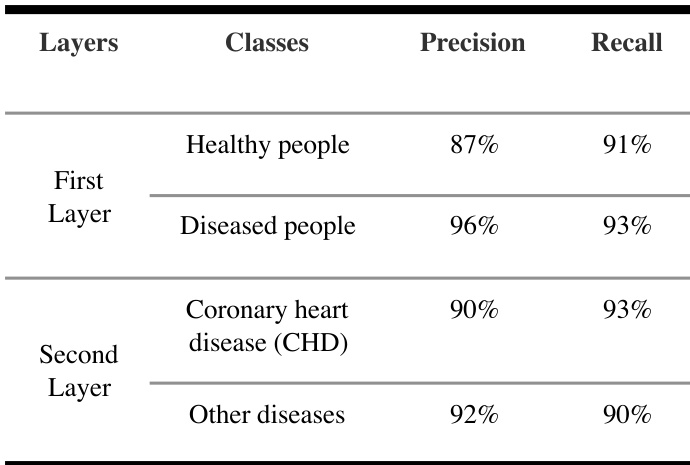
{"summary": "The authors developed a two-layer GBDT model to classify health, coronary heart disease, and other diseases using routine blood test data. The model achieved high precision and recall in both layers, with the first layer distinguishing healthy from diseased individuals and the second layer further classifying diseased cases into coronary heart disease and other conditions. Results show that the two-layer approach performs comparably to a direct three-classification model while providing interpretability for clinical use.", "highlights": ["The two-layer GBDT model achieves high precision and recall in distinguishing healthy individuals from diseased people in the first layer.", "In the second layer, the model maintains strong performance in identifying coronary heart disease and other diseases.", "The model's classification results are consistent with the overall performance reported in the study, supporting its use for clinical risk prediction."]
The authors compare multiple machine learning algorithms for classifying health, coronary heart disease, and other diseases using routine blood test data. The GBDT model achieves the highest accuracy and sensitivity among the compared models, indicating strong performance in identifying both healthy individuals and those with coronary heart disease. The GBDT model outperforms LR and SVM in both accuracy and sensitivity. The GBDT model achieves high sensitivity for identifying both healthy individuals and those with coronary heart disease. The two-layer GBDT model is effective in classifying health, coronary heart disease, and other diseases using routine blood test data.
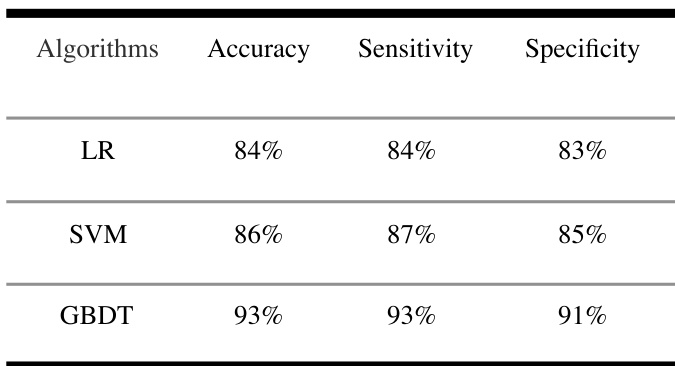
The authors developed a two-layer GBDT model using routine blood test data to predict coronary heart disease, achieving comparable performance to a three-classification model. Results show that the model identifies individuals with coronary heart disease with high precision and recall, and the approach reveals consistent patterns in blood test data that may have clinical relevance. The model also demonstrates strong sensitivity for both health and disease categories. The two-layer GBDT model achieves high precision and recall for coronary heart disease detection. The model demonstrates strong sensitivity in identifying both healthy individuals and those with coronary heart disease. The approach reveals consistent patterns in routine blood test data that could be useful for clinical reference.

The experiments compare multiple machine learning algorithms using routine blood test data to classify health status and specific cardiovascular conditions. These evaluations validate the effectiveness of a hierarchical two-layer GBDT architecture against a direct multi-class approach, emphasizing classification reliability and clinical interpretability. The results consistently indicate that GBDT substantially outperforms logistic regression and SVM across all performance dimensions. Ultimately, the two-layer framework proves highly effective for disease stratification, matching the accuracy of direct classification while delivering transparent, clinically actionable insights for routine health screening.