Command Palette
Search for a command to run...
希少な訓練データを持つドメインにおける微細な物体認識のためのサリエンス
希少な訓練データを持つドメインにおける微細な物体認識のためのサリエンス
Carola Figueroa Flores Abel Gonzalez-Garcia Joost van de Weijer Bogdan Raducanu
Keras を用いた花認識 CNN
概要
本論文は、学習データが限られている場合に、畳み込みニューラルネットワーク(CNN)の分類精度を向上させるために、サリエンス(注目性)の役割を調査するものである。我々のアプローチは、既存のCNNアーキテクチャにサリエンスブランチを追加し、元の画像入力からの標準的なボトムアップ型視覚特徴をモジュレートするものである。このブランチは注意機構として機能し、特徴抽出プロセスを誘導する。提案手法の主な目的は、限られた学習サンプルで微細な認識モデルを効果的に訓練可能にし、タスク上の性能を向上させることで、大規模データセットのアノテーション必要性を軽減することである。サリエンス手法の大半は、サリエンスマップを生成する能力に基づいて評価されており、完全なビジョンパイプライン内での機能性に基づいて評価されているわけではない。我々が提案するパイプラインは、オブジェクト認識という高レベルタスクにおいてサリエンス手法を評価することを可能にする。我々は、異なる条件下で複数の微細データセット(Flowers、Birds、Cars、Dogs)に対して広範な実験を行い、サリエンスが特に学習データが限られている場合に、ネットワークの性能を大幅に向上させ得ることを示す。
One-sentence Summary
By integrating a saliency branch that modulates bottom-up visual features as an attentional mechanism, the proposed CNN considerably improves fine-grained object recognition accuracy on the Flowers, Birds, Cars, and Dogs datasets, particularly when training samples are scarce, thereby validating saliency methods within complete vision pipelines rather than restricting evaluation to map generation alone.
Key Contributions
- Introduces a convolutional neural network architecture that integrates a dedicated saliency branch to modulate standard bottom-up visual features as an attentional mechanism.
- Establishes a complete vision pipeline that evaluates saliency generation methods by measuring their direct impact on high-level object recognition performance rather than relying solely on traditional saliency map quality metrics.
- Demonstrates through extensive experiments on the Flowers, Birds, Cars, and Dogs datasets that the proposed architecture significantly improves classification accuracy, particularly under limited training data conditions.
Introduction
Fine-grained object recognition requires distinguishing highly similar subclasses, a task that traditionally demands expensive expert annotations and large labeled datasets to capture subtle visual differences. While computational saliency methods effectively highlight visually prominent regions, prior work primarily optimizes these models for map accuracy or human gaze prediction rather than measuring their actual impact on downstream classification. Additionally, existing attention-based neural networks typically require learning new parameters from scratch, making them unstable and prone to overfitting when labeled examples are scarce. The authors leverage a pretrained saliency network as a fixed attention module that modulates standard visual features within a dual-branch architecture. By guiding the recognition model to focus on discriminative regions without requiring explicit part annotations, this approach significantly boosts classification accuracy under data-scarce conditions and reduces the need for costly dataset collection.
Dataset
- Dataset Composition and Sources: The authors evaluate their framework on four standard fine-grained classification benchmarks sourced from established academic repositories.
- Subset Specifications:
- Oxford Flower 102 provides 8,189 images across 102 classes, with 40 to 258 samples per category.
- The Birds dataset contains 11,788 images spanning 200 species, originally equipped with bounding boxes and 15 keypoints, though the authors process the full uncropped images.
- The Cars dataset offers 16,185 images across 196 classes, already partitioned into roughly equal training and testing portions.
- Stanford Dogs includes 20,580 images across 120 breeds, with a preprocessing step that removes any images overlapping with ImageNet.
- Training Protocol and Data Utilization: For each class, the authors enforce a fixed split of five test images, five validation images, and the remainder for training. To measure performance under limited data conditions, they train models on subsets of k images per class, where k takes values from 1 to 30 and includes the complete available training set. The base AlexNet architecture is pretrained on ImageNet and fine-tuned for 70 epochs using a learning rate of 0.01 and weight decay of 0.003. The authors also validate the pipeline with ResNet-50 and ResNet-152, reporting classification accuracy averaged over five independent random initializations.
- Processing and Input Engineering: The workflow avoids explicit cropping, operating directly on full images. Although the Birds dataset includes bounding box and keypoint metadata, these annotations are intentionally ignored. Instead, the authors construct an additional saliency input channel by generating attention maps through five established algorithms (iSEEL, SALICON, Itti and Koch, GBVS, and BMS) and two geometric baselines (uniform white and centered Gaussian distributions) to determine whether learned visual attention enhances recognition beyond standard pixel features.
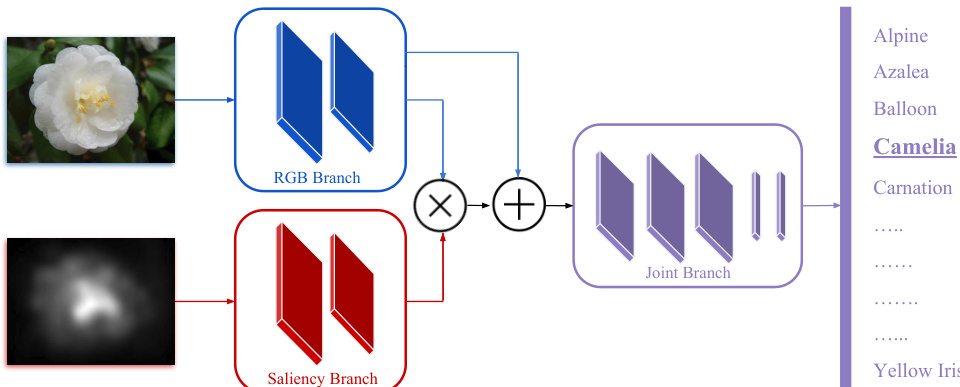
Method
The authors leverage a dual-branch architecture to integrate saliency information into a convolutional neural network (CNN) for fine-grained object classification under conditions of scarce training data. The framework consists of two primary pathways: an RGB branch that processes the original color image and a saliency branch that operates on a precomputed saliency map derived from the same image. These two streams are designed to interact through a modulation mechanism that dynamically adjusts the importance of visual features during feature extraction. The RGB branch follows a standard CNN processing pipeline, while the saliency branch transforms the input saliency map into a modulation image of matching spatial dimensions. This modulation image is then used to scale the feature maps of an intermediate layer in the RGB branch, effectively emphasizing salient regions and de-emphasizing less relevant background areas. The modulated features are subsequently combined with the original features via a skip connection and fed into a shared joint branch, which continues processing through additional layers before reaching the final classification layer. The architecture is designed to be modular and compatible with various base networks, such as AlexNet, ResNet-50, and ResNet-152, and is trained end-to-end to jointly optimize both the classification and modulation components.