Command Palette
Search for a command to run...
教師なしテキスト選択
概要
One-sentence Summary
This work proposes a framework for unsupervised automatic speech recognition trained exclusively on unaligned speech and text, which first extracts phonetic- and speaker-disentangled vector representations via a sequence-of-sequence autoencoder, derives semantic audio embeddings using a skip-gram model, and finally maps these embeddings to words through an unsupervised transformation into the text embedding space.
Key Contributions
- Introduces a framework for unsupervised automatic speech recognition that processes unaligned audio and text corpora to generate word-level transcriptions.
- Constructs acoustic semantic representations by extracting phonetic and speaker-independent vectors via a sequence-to-sequence autoencoder and mapping them to semantic embeddings using a skip-gram model.
- Aligns audio embeddings to a textual embedding space through an iterative transformation algorithm, demonstrating word-level prediction on a read English speech dataset without manual supervision.
Introduction
Automatic speech recognition powers countless applications, but its dependence on costly audio-text alignment severely limits deployment in low-resource or novel linguistic environments. Previous methods typically require aligned corpora or struggle to extract semantic representations that effectively bridge acoustic and textual data without supervision. The authors leverage adversarial sequence-to-sequence autoencoders to isolate clean phonetic embeddings, then apply a skip-gram framework to derive semantic vectors from unannotated audio. By iteratively aligning these audio embeddings with standard text embeddings through a shared transformation space, they achieve word-level speech recognition using only unaligned speech and text, representing the first fully unsupervised approach to the task.
Method
The proposed unsupervised automatic speech recognition (ASR) framework operates in three distinct stages, each designed to progressively extract and align semantic information from unaligned audio and text data. The overall architecture is structured to disentangle phonetic and speaker-specific features from audio segments, learn semantic embeddings from these features, and then map the resulting audio semantic representations into a textual semantic space without relying on aligned audio-text pairs.
The first stage focuses on extracting phonetic embeddings from word-level audio segments while disentangling speaker-specific information. Given a collection of audio segments, each segment is processed by two separate encoders: a phonetic encoder Ep and a speaker encoder Es. These encoders are designed to extract a phonetic vector vp and a speaker vector vs, respectively, from the input acoustic features. The outputs of both encoders are then fed into a decoder, which reconstructs the original acoustic features. The primary objective is to minimize the reconstruction loss Lr, defined as the sum of squared differences between the original and reconstructed features, thereby ensuring that the combined output of the encoders retains sufficient information for accurate reconstruction.
To achieve the disentanglement of phonetic and speaker information, the framework employs two distinct training criteria. The speaker encoder Es is trained to minimize a loss Ls that encourages embeddings of segments from the same speaker to be close in the embedding space, while embedding vectors from different speakers are kept apart by a margin λ. This is implemented using a combination of a mean-squared error term for same-speaker pairs and a hinge loss term for different-speaker pairs. Simultaneously, the phonetic encoder Ep is trained to "fool" a discriminator D that attempts to classify whether two phonetic vectors originate from the same speaker. The discriminator is trained to maximize the loss Ld, which measures the difference in predicted probabilities for same- and different-speaker pairs, while the phonetic encoder is trained to minimize this same loss. This adversarial training ensures that the phonetic vector vp contains only phonetic information, as the speaker information has been effectively encoded in the separate vs vector. The entire optimization procedure iteratively minimizes Lr+Ls−Ld, balancing reconstruction, speaker consistency, and phonetic disentanglement.
The second stage leverages the extracted phonetic embeddings to learn semantic embeddings, drawing a parallel to the skip-gram model in natural language processing. Given a phonetic vector vpi for a segment, a semantic encoder Esem maps it to a semantic embedding vwi. For each segment, a context window of neighboring segments is defined, and the phonetic vectors of these context segments are passed through a context encoder Econ to produce context embeddings vcj. The training objective is to maximize the similarity between the semantic embedding of a segment and the context embeddings of its neighboring segments, while minimizing this similarity for non-contextual pairs. This is achieved by minimizing a semantic loss Lsem, which uses the sigmoid of the dot product to measure similarity and incorporates negative sampling to efficiently train on a subset of negative examples. This process ensures that segments with similar contextual patterns are mapped to nearby points in the semantic space, thereby capturing their shared semantic meaning.
The final stage performs an unsupervised transformation to align the learned audio semantic embeddings with textual semantic embeddings. The framework takes a set of audio semantic embeddings Vw and a set of textual semantic embeddings Uw obtained from a text corpus. Since these embeddings exist in different semantic spaces, a transformation is learned to map one into the other. This is achieved using the MBC-ICP algorithm, which first projects both sets of embeddings to their top K principal components via PCA, resulting in matrices A and B. A pair of transformation matrices, Tab and Tba, are learned iteratively. The algorithm finds nearest neighbors between the projected spaces and optimizes the transformation matrices to minimize the distance between a point and its transformed nearest neighbor in the other space. Cycle constraints are included to ensure that transforming a point to the other space and back results in a nearly identical point, promoting a consistent and stable mapping. After the transformation is learned, audio segments can be mapped to the textual semantic space, and the corresponding text word is identified as the one whose embedding is the nearest neighbor, effectively achieving word-level recognition.
Experiment
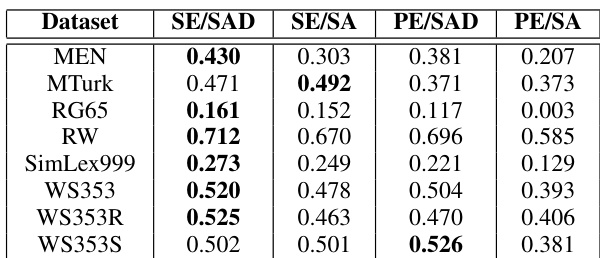
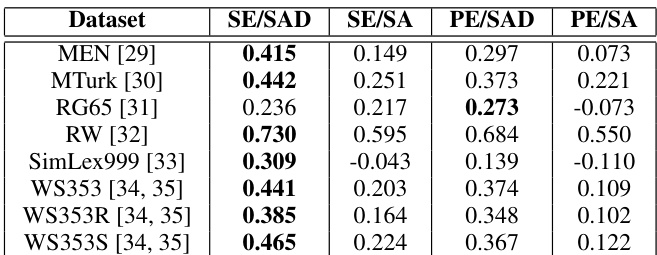
The evaluation setup employs standard benchmark datasets to measure semantic correlation between audio and textual embeddings, alongside transformation accuracy tests to assess cross-modal alignment. These experiments validate that incorporating disentanglement and semantic training significantly enhances the representational quality of audio embeddings, confirming the effectiveness of the initial extraction stages. Subsequent alignment tests demonstrate that while fully unsupervised approaches struggle to identify the optimal mapping, semi-supervised methods successfully establish a robust affine transformation between audio and text spaces. Ultimately, the findings indicate that the proposed framework effectively bridges the two modalities, providing a strong foundation for future fully unsupervised speech recognition systems.
The authors evaluate the alignment between audio and textual semantic embeddings using correlation scores across multiple datasets. Results show that disentangled audio semantic embeddings consistently outperform non-disentangled ones, and the proposed method achieves higher transformation accuracy when labeled data is available. The findings suggest that an affine transformation can effectively map audio embeddings to textual embeddings, particularly with semi-supervised learning. Disentangled audio semantic embeddings achieve higher correlation with textual embeddings than non-disentangled ones across all datasets. The proposed method demonstrates improved transformation accuracy when using semi-supervised learning with labeled pairs. Audio semantic embeddings outperform phonetic embeddings in capturing semantic similarities, as indicated by higher correlation scores.
The authors evaluate the correlation between audio and textual semantic embeddings across multiple datasets, comparing different embedding types. Results show that disentangled semantic embeddings generally perform better than non-disentangled ones, and audio semantic embeddings outperform phonetic embeddings in most cases. The best-performing method achieves the highest correlation across various benchmarks, indicating the effectiveness of the proposed framework. In the transformation stage, semi-supervised learning significantly improves accuracy compared to unsupervised methods, suggesting that an affine transformation between audio and text embeddings exists but is difficult to learn without labeled data. Disentangled semantic embeddings achieve higher correlation with textual embeddings than non-disentangled ones across most datasets. Audio semantic embeddings consistently outperform phonetic embeddings in capturing semantic similarity with text. Semi-supervised learning significantly improves transformation accuracy compared to unsupervised approaches, indicating the existence of an affine transformation between audio and text embeddings.
The authors evaluate the performance of different audio embedding methods in capturing semantic information and transforming it to text representations. Results show that disentanglement improves correlation with textual embeddings, and semi-supervised learning achieves higher transformation accuracy compared to unsupervised approaches. The best-performing method consistently demonstrates superior results across both evaluation metrics. Disentanglement improves the correlation between audio and textual embeddings in most cases. Audio semantic embeddings outperform embeddings extracted directly from speech analysis in most scenarios. Semi-supervised learning achieves higher transformation accuracy than unsupervised methods.

The authors evaluate the effectiveness of audio semantic embeddings in capturing semantic information similar to textual embeddings through correlation analysis and transformation accuracy. Results show that disentanglement improves correlation scores and that semi-supervised learning achieves higher transformation accuracy compared to unsupervised methods, indicating that an affine transformation between audio and text embeddings is feasible with labeled data. Disentanglement improves correlation between audio and textual embeddings in most cases. Semi-supervised learning achieves higher transformation accuracy than unsupervised learning. Audio semantic embeddings outperform embeddings extracted directly from speech analysis in most scenarios.
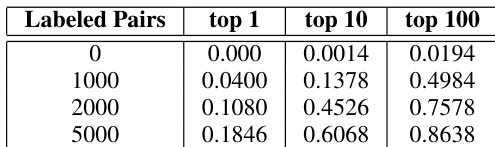
The experiments evaluate cross-modal alignment by measuring the correlation between audio and textual semantic embeddings across multiple datasets, alongside the accuracy of mapping audio representations to text. Initial validations compare embedding architectures, demonstrating that disentangled audio semantic representations capture linguistic meaning more effectively than non-disentangled or phonetic alternatives. Subsequent assessments test the feasibility of affine transformations between modalities, confirming that semi-supervised learning substantially improves mapping accuracy compared to unsupervised methods. Collectively, these results establish that semantic disentanglement paired with limited labeled data enables robust and accurate audio-to-text alignment.