Command Palette
Search for a command to run...
K+ 平均法:K平均クラスタリングアルゴリズムの改良
K+ 平均法:K平均クラスタリングアルゴリズムの改良
Srikanta Kolay Kumar S. Ray Abhoy Chand Mondal
K 平均法アルゴリズム
概要
K-means(MacQueen, 1967)[1]は、よく知られたクラスタリング問題を解決する最も単純な教師なし学習アルゴリズムの一つである。この手法は、与えられたデータセットを事前に定義された、例えばK個のクラスタに分類するという、単純で容易な手順に従う。Kの決定は困難な作業であり、直感に合うようにオブジェクトを分割するKの値がどれであるかは不明である。この問題を克服するために、我々はK+ Meansアルゴリズムを提案する。このアルゴリズムは、K-Meansアルゴリズムの改良版である。
One-sentence Summary
To address the difficulty of selecting an appropriate number of clusters in traditional K-means, the authors propose K+ Means, an enhanced unsupervised clustering algorithm that simplifies the data partitioning process.
Key Contributions
- The K+ Means algorithm enhances standard K-Means clustering by automatically determining the final number of clusters based on data characteristics rather than requiring a predefined count.
- The method calculates minimum, maximum, and average intra-cluster dissimilarity to detect outliers, subsequently promoting high-distance objects as new centroids until cluster representatives and assignments stabilize.
- Evaluations against standard K-Means demonstrate that the approach isolates anomalous points into separate clusters while preserving the O(tk²n) time complexity and eliminating sensitivity to outlier placement.
Introduction
No source text was provided. Please share the abstract or body snippet so I can draft a concise summary that outlines the technical context and its practical significance, identifies the limitations of existing approaches, and explains the authors' main contribution from an explainer perspective.
Dataset
- Dataset composition and sources: The authors rely on a small illustrative dataset presented in a single table to demonstrate the algorithm.
- Key details for each subset: Only one example subset is provided. It contains a limited number of objects chosen specifically for a worked walkthrough rather than large scale modeling.
- How the paper uses the data: The dataset functions exclusively as a practical example to walk readers through the K+ Means clustering steps. The excerpts do not mention formal training splits, mixture ratios, or evaluation protocols.
- Processing and visualization details: The raw table values are directly mapped to a 2D coordinate space for visual demonstration. No cropping, metadata construction, or additional preprocessing pipelines are described.
Method
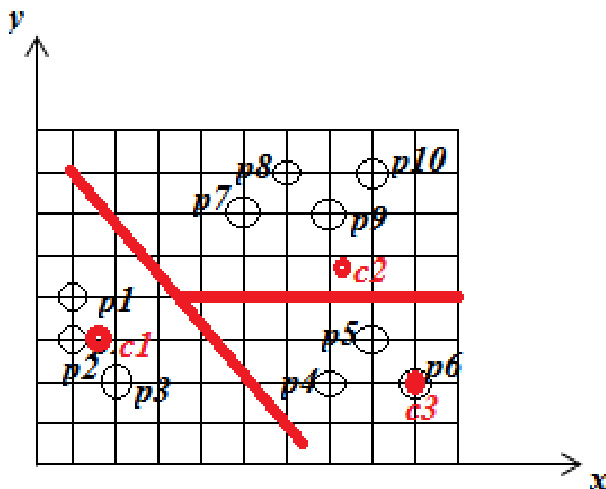
The authors leverage the K-Means algorithm as a foundational component to develop the K+ Means algorithm, which addresses key limitations of the original method. The framework begins by initializing K centroids and assigning data points to the nearest cluster, following the standard K-Means procedure. After convergence, the algorithm computes intra-cluster dissimilarity metrics—minimum, maximum, and average—for each cluster. The core enhancement lies in dynamically identifying outliers based on these metrics. Specifically, clusters exhibiting a high average intra-cluster distance, particularly when accompanied by a large maximum distance, are flagged for further analysis. The data point corresponding to the maximum distance within such a cluster is identified as an outlier and treated as a new cluster representative. This process iteratively increases the number of clusters by one, reassigning data points and recalculating centroids until no new representatives are formed and cluster assignments stabilize.
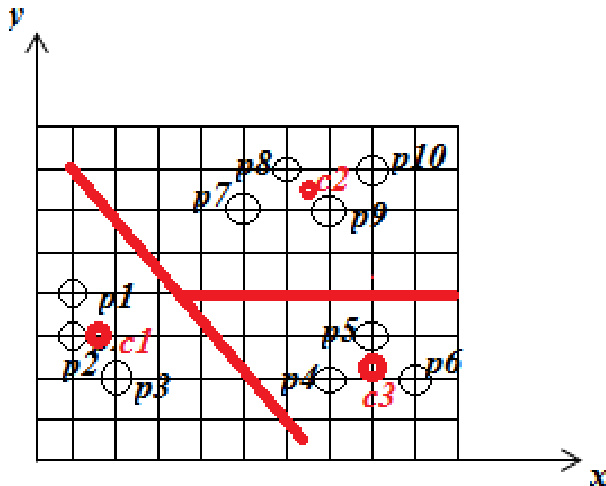
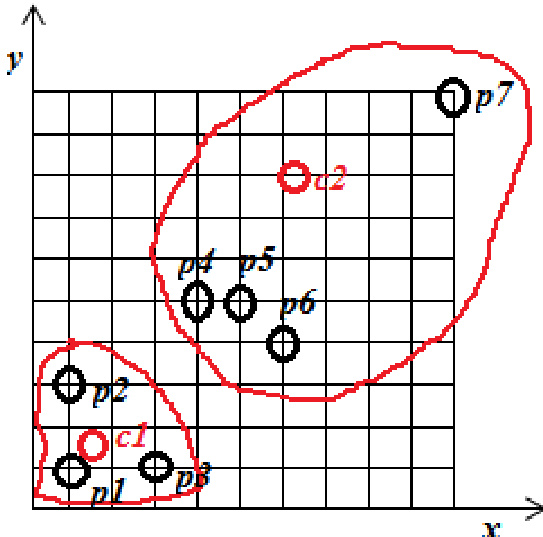
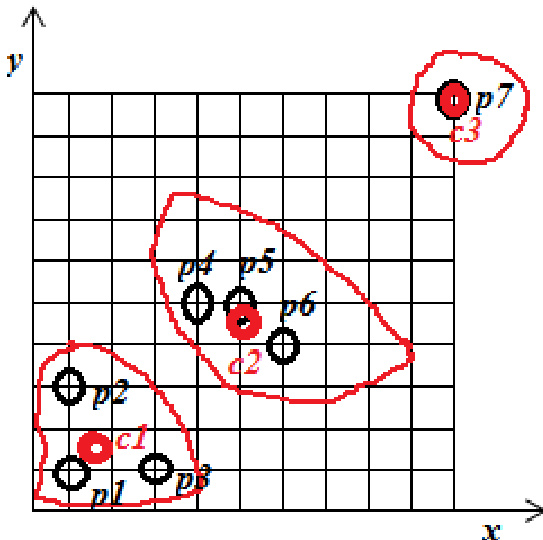
Experiment
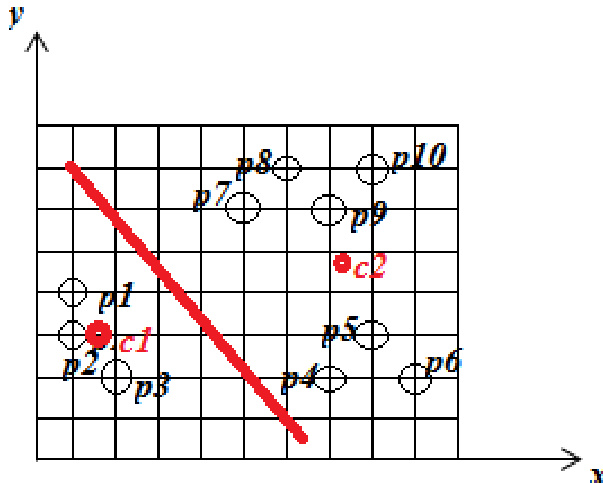
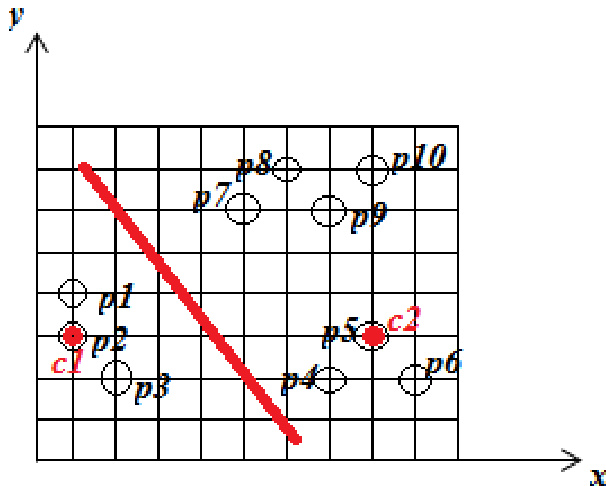
The evaluation compares the standard K-means algorithm with the K+ Means approach using a two-cluster configuration on a dataset of objects. The experiments validate that while K-means establishes initial groupings based on selected centroids, the K+ Means algorithm delivers more accurate and robust cluster assignments, particularly in effectively managing outlier objects. Although the K+ Means method entails slightly higher computational complexity, it consistently achieves superior clustering outcomes overall.
The authors apply the K-means algorithm with initial centroids at p1 and p5, resulting in two clusters where one contains points p1, p2, and p3, and the other contains the remaining points. A comparison is made between K-means and K+ Means algorithms, with the latter producing better clustering results despite higher complexity, particularly in handling outlier objects. K-means clustering groups points into two clusters based on initial centroid selection. K+ Means algorithm produces superior clustering compared to K-means, especially for outlier objects. The K+ Means algorithm has higher computational complexity than K-means.
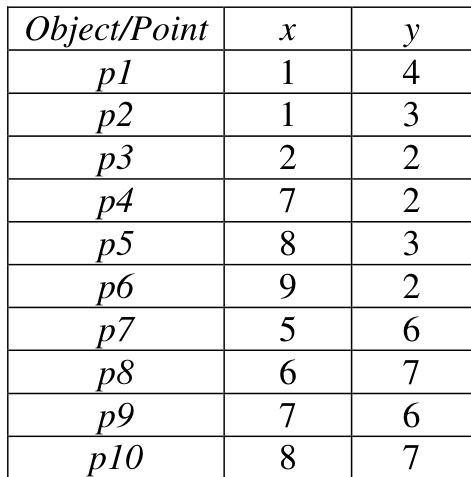
The evaluation compares standard K-means clustering against the K+Means algorithm using defined initial centroids to partition data into distinct groups. This setup validates the comparative effectiveness of both methods in forming coherent clusters while assessing their handling of anomalous data points. The findings demonstrate that K+Means consistently yields superior clustering quality, particularly in managing outlier objects, despite incurring greater computational overhead.