Command Palette
Search for a command to run...
言語モデル
概要
One-sentence Summary
By training a Support Vector Machines classifier on word unigram and part-of-speech distribution features, the authors achieve 99.8% accuracy in dating historical Portuguese literary texts to half-century and century intervals, with feature analysis linking informative lexical and morphosyntactic markers to language change.
Key Contributions
- Presents a temporal text classification framework for historical Portuguese literary texts that models language evolution through lexical variation via word n-grams and morphosyntactic variation via part-of-speech distributions.
- Investigates the most informative linguistic features through a dedicated analysis and explicitly links these patterns to historical language change processes.
- Demonstrates that a Support Vector Machine classifier utilizing word unigram features achieves 99.8% accuracy in predicting publication dates across one-century and half-century intervals.
Introduction
The provided text contains only metadata and acknowledgements, so it lacks the research background, prior limitations, and specific contributions required for a summary. Once you share the abstract or body text, I will gladly draft a concise explanation that highlights the application context, existing challenges, and the authors’ main contribution. I will ensure the final output remains technical yet accessible, strictly following your formatting guidelines.
Dataset
-
Dataset Composition and Sources: The authors use the Colonia corpus, a historical Portuguese collection spanning the 16th to early 20th centuries. It comprises 100 full novels and text collections totaling over 5.1 million tokens, featuring preprocessed sentence boundaries and coarse-grained part-of-speech (POS) tags generated by TreeTagger.
-
Subset Details: Documents are organized by historical era to serve as classification labels. The subset sizes are naturally imbalanced, ranging from 13 documents in the 16th century to 38 in the 19th century.
-
Data Usage and Processing: To address the limited number of original documents per period and standardize input lengths, the authors synthesize composite documents by randomly sampling and concatenating sentences from the same time period. These artificial texts average approximately 330 tokens each and are partitioned into training and testing splits. This construction method mixes different authorship styles and topics within each class while enforcing uniform length to increase classification difficulty.
-
Feature Construction and Modeling: The authors extract raw words and POS tags from the composite documents to serve as lexical and morphosyntactic features. These features are used to train a multi-class temporal text classification model designed to track diachronic language variation.
Method
The authors leverage a support vector machine (SVM) classifier to model lexical and syntactic variation in historical Portuguese texts for temporal classification. The framework relies on feature extraction from both word-level and part-of-speech (POS) information, enabling the identification of patterns indicative of language change across different centuries. Features are ranked based on their contribution to the SVM model, using the weights assigned during training, which allows for the identification of the most discriminative linguistic patterns. This approach enables the detection of both topical and structural shifts in language use over time.
Word unigrams are used as a primary feature set, capturing vocabulary changes across periods. In addition, POS n-grams—such as sequences of POS tags—are incorporated to capture syntactic and grammatical shifts. The use of POS tags allows the identification of stylistic preferences, such as the increased use of adjectives in the 19th and 20th centuries, reflected in patterns like ADJ NOM ADJ and NOM ADJ CONJ. These patterns are particularly informative for distinguishing later periods, where stylistic choices become more pronounced.
The framework also incorporates named entities, which, while less indicative of linguistic change, contribute significantly to classification accuracy. For instance, references to historical figures like Dom Afonso and Dom João, or formal titles such as Sua Majestade, serve as period-specific markers in 17th-century texts. Similarly, archaic forms such as per, asi, mui, mi, and despois are prominent in 16th-century texts, with per being especially discriminative due to its Latin origin and frequent use in Latin quotations.
To address the limited availability of historical texts, the authors employ a data augmentation strategy by generating artificial training and test instances from fragments of texts written in the same period. This method allows for the evaluation of models under conditions where real-world data is scarce, enhancing generalization and robustness.
Experiment
The evaluation employs a historical Portuguese corpus labeled by publication era, utilizing lexical n-grams and morphosyntactic part-of-speech distributions to train supervised classifiers. Preliminary and scaled experiments validate that generating composite documents significantly boosts performance by mitigating data scarcity and neutralizing author-specific stylistic bias. Subsequent tests across century and fifty-year intervals confirm that word-level features effectively track vocabulary shifts, while structural patterns capture underlying grammatical evolution. Ultimately, the findings demonstrate that supervised classification reliably models diachronic language change, though future methodologies must refine arbitrary temporal boundaries to better capture continuous linguistic development.
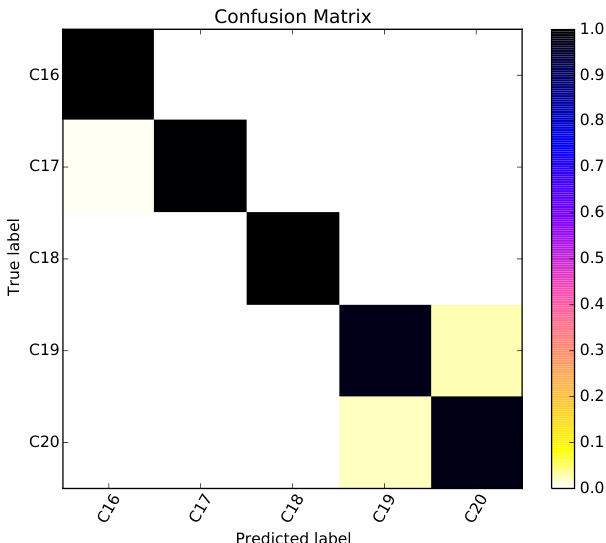
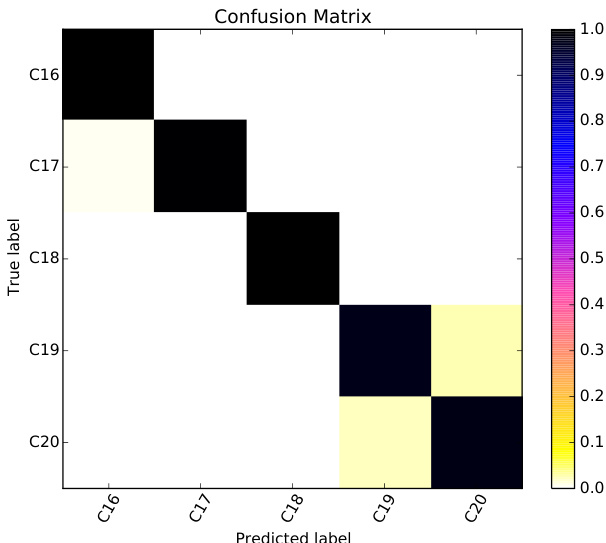
The authors conduct experiments to classify historical Portuguese texts by publication date using supervised machine learning, focusing on lexical and morphosyntactic features. Results show high accuracy in classifying texts into century and half-century intervals, with word unigrams performing best and POS trigrams capturing structural language variation. The confusion matrix reveals near-perfect classification for most periods, with some confusion between adjacent time spans. Word unigrams achieve the highest classification accuracy, outperforming other feature types. POS trigrams capture structural language variation, showing strong performance despite lower accuracy than word unigrams. Confusion is highest between adjacent time intervals, particularly in the 19th and 20th centuries, indicating similar linguistic features across these periods.
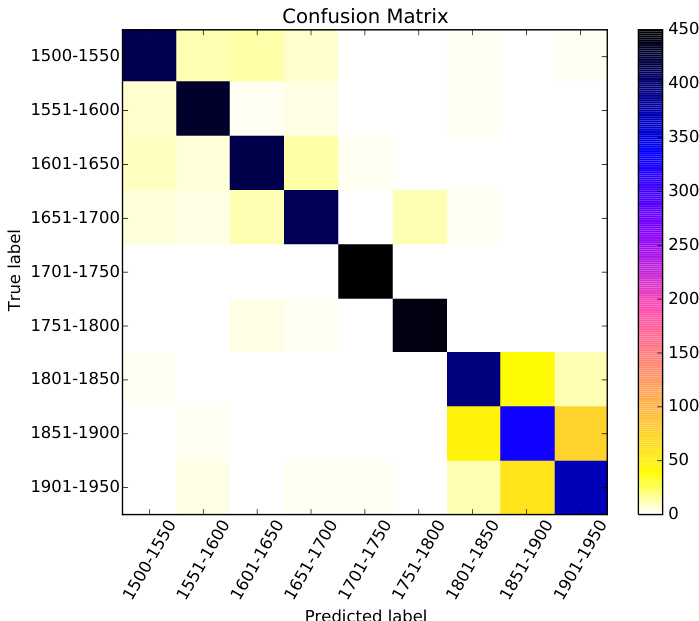
The authors conduct experiments to classify historical Portuguese texts by publication date using machine learning models with lexical and morphosyntactic features. Results show high accuracy in predicting century-level time intervals, with word unigrams performing best, and indicate that performance remains strong even when using finer 50-year intervals, though some confusion occurs between adjacent periods. Classification accuracy is very high for century-level intervals, with word unigrams achieving the best performance. Performance remains strong for 50-year intervals, though some confusion is observed between adjacent time periods. The model shows robustness to data generation methods, with artificial documents improving results compared to smaller samples.
The authors conducted experiments to classify historical texts by publication date using word and part-of-speech n-grams as features. Results show that word unigrams achieved the highest accuracy, significantly outperforming other feature types and the baseline. Performance varied with feature type, where word-based features peaked at unigrams and POS-based features improved with higher n-gram orders. Word unigrams achieved the highest classification accuracy, outperforming all other feature types. Accuracy decreased for higher-order word n-grams, while POS n-grams showed improved performance with increasing n-gram order. The classifier using word unigrams achieved near-perfect accuracy, substantially surpassing the random baseline.

{"summary": "The authors conduct experiments to classify historical Portuguese texts by publication date using machine learning classifiers trained on lexical and morphosyntactic features. Results show high classification accuracy using word unigrams with a linear SVM, with performance improving significantly when using larger, artificially generated datasets. The best-performing model achieves near-perfect accuracy for both century and half-century time intervals, while POS-based features also yield strong results, particularly for trigrams.", "highlights": ["Classification accuracy improves substantially with larger datasets generated through artificial document composition.", "Word unigrams achieve the highest performance, with near-perfect accuracy for both century and half-century time intervals.", "POS trigrams also yield strong results, indicating that structural language changes are detectable even with shorter time spans."]
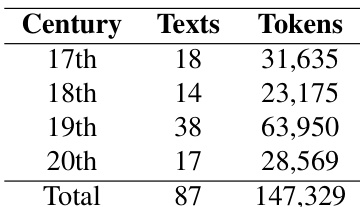
The authors conduct experiments to classify historical Portuguese texts by publication date using machine learning models with lexical and morphosyntactic features. Results show high classification accuracy using word unigrams, with performance remaining strong even when time intervals are reduced to 50 years, indicating the method's effectiveness in capturing temporal language variation. Classification accuracy remains high using word unigrams even with smaller time intervals of 50 years. Performance is strong across all time intervals, with slight confusion observed between the 19th and early 20th centuries. POS trigrams achieve notable accuracy, suggesting structural language changes are detectable over time.
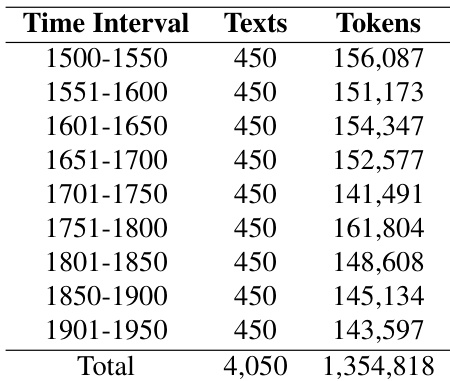
The experiments evaluate supervised machine learning models trained on lexical and morphosyntactic features to classify historical Portuguese texts by publication date. The results demonstrate that word unigrams consistently yield the highest classification accuracy across both century and half-century intervals, while part-of-speech trigrams effectively capture underlying structural language shifts. Although the models maintain strong performance, minor classification overlaps occur between adjacent periods, particularly in the nineteenth and twentieth centuries, reflecting gradual linguistic transitions. Overall, the findings validate that temporal language evolution can be reliably detected through n-gram-based feature extraction, with model robustness further enhanced by expanded and synthetically augmented training data.