Command Palette
Search for a command to run...
RolmOCR のワンクリックデプロイ:クロスシナリオ高速 OCR オープンソースベンチマーク
概要
One-sentence Summary
Training the open-source Tesseract 2.01 OCR engine on 1,844 user-specific isolated characters and evaluating it on 1,133 lowercase Roman script characters yields an 83.5% character-level accuracy, with 5.56% segmentation failures and a 10.94% misclassification rate.
Key Contributions
- The work adapts the Tesseract 2.01 open-source OCR engine to recognize handwritten lower case Roman script via user-specific training on isolated and free-flow text samples.
- A customized model is developed using 1844 training characters per user to capture individual writing characteristics without building a new engine from scratch.
- Systematic evaluation on a 1133-character test set yields an 83.5 percent character-level accuracy, with empirical analysis reporting 5.56 percent segmentation failures and 10.94 percent classification errors.
Introduction
Optical character recognition systems automate the conversion of paper documents into digital text, enabling critical workflows like form processing, postal routing, and financial document handling. Despite decades of research, building a handwritten OCR engine that consistently delivers high accuracy remains a persistent technical challenge. While established open-source engines like Tesseract perform reliably on printed material, their effectiveness on handwritten input has rarely been rigorously evaluated or optimized. The authors leverage Tesseract 2.01 to address this gap by implementing user-specific training on lower-case Roman script. They systematically assess the engine on both isolated characters and free-flowing handwriting, measuring character-level and word-level accuracy to demonstrate its practical viability for handwritten document processing.
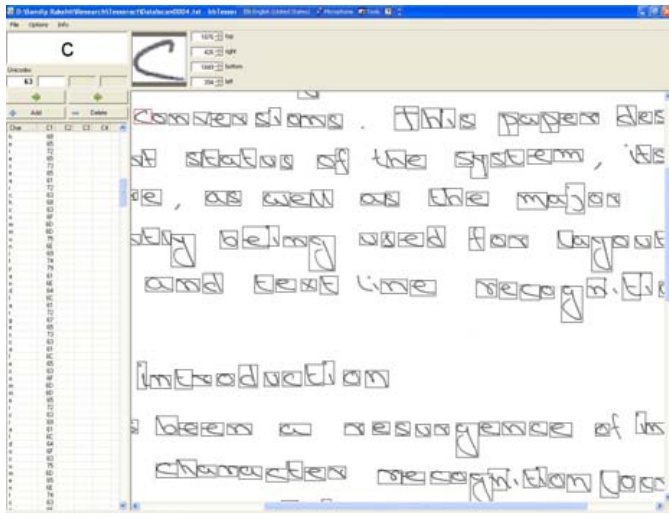
Dataset

-
Dataset Composition and Sources: The authors compiled a handwriting dataset focused exclusively on lowercase Roman script. Data was collected from four distinct users, with each contributor providing six handwritten document pages divided into two categories: isolated characters and free-flow text extracted from technical articles.
-
Subset Details and Splits: Each user's collection contains four pages of isolated lowercase characters and two pages of continuous text. The authors allocated three isolated pages and one free-flow page per user to the training set, while reserving one page from each category for testing. The training portion holds approximately 70 isolated character samples and 120 words (roughly 650 characters) of free-flow text per user, with individual user sets containing up to 1,844 labeled character samples.
-
Data Usage and Processing: The dataset trains Tesseract version 2.01 for custom handwriting recognition. The authors generate a reference box file for each training page, then use it to bootstrap the OCR engine and automatically label the remaining training images. They execute a standard Tesseract training pipeline using mftraining, cntraining, unicharset_extractor, and wordlist2dawg to produce eight core model files, including intemp, pffntable, Microfeat, normproto, unicharset, DAWG-based dictionaries, user-words, and DangAmbigs. These files are prefixed with a three-letter language code and placed in the tessdata directory for final recognition.
-
Metadata and Bounding Box Construction: Bounding box metadata is initially generated automatically by Tesseract, storing character order and coordinate data in a text-based box format. When the target character set diverges from the engine's default training, the authors manually correct inaccuracies using the bbTesseract tool before renaming the output files to match the required naming convention.
Method
The authors leverage the Tesseract OCR engine, an open-source optical character recognition system originally developed at Hewlett Packard and later maintained by Google under the Apache License 2.0, as the foundation for their character recognition pipeline. Tesseract operates through a modular architecture that includes key components such as a line and word finder, a word recognizer, a static character classifier, a linguistic analyzer, and an adaptive classifier. These modules work in concert to process input images, locate text regions, recognize individual characters, and apply language-specific rules to improve accuracy. The engine does not support document layout analysis or output formatting, focusing instead on character-level recognition.
To enable recognition in a specific language—such as English—Tesseract requires a set of eight training files stored in the tessdata subdirectory. These files include linguistic and structural data such as frequency dictionaries, word lists, character shape prototypes, and unicharset definitions, which collectively define the character set and language model. The training process begins with the preparation of labeled training images, where each character is annotated with bounding box coordinates. This is accomplished using a tool called bbTesseract, which facilitates the creation of box files that specify the location and label of each character in the training images.
As shown in the figure below, the training workflow proceeds by feeding a preprocessed image (e.g., fontfile.tif) into Tesseract with specific command-line parameters: tesseract fontfile.tif junk nobatch box.train. This command generates a .tr file containing feature vectors for each character in the image, capturing shape and structural information. The features are then processed using two specialized programs: mftraining, which clusters character shape features into prototypes, and entraining, which constructs the training data for the character classifier. These steps are essential for generating the language-specific models that enable Tesseract to recognize text with high accuracy.
Experiment
The experiments evaluate the core recognition accuracy and segmentation robustness of the Tesseract OCR engine by training a single-user model on isolated and free-flow handwritten lowercase Roman script while disabling linguistic analysis modules. Qualitative findings reveal that while baseline character recognition performs adequately, overall system reliability is compromised by segmentation failures, particularly over-segmentation and internal character splitting, which arise from the engine's inherent bias toward uniform printed text. Consequently, the study concludes that practical deployment requires multi-user validation alongside expanded training data and integrated word-level dictionary matching to effectively process connected handwriting.
The authors evaluate the performance of the Tesseract OCR engine on handwritten lower case Roman script, focusing on isolated and free-flow text samples. Results show that character-level recognition accuracy is higher than word-level accuracy, with segmentation failures being a major source of error, particularly for free-flow text. The system performs better on isolated characters compared to free-flow text, and misclassification rates are notably higher for words. Character-level recognition accuracy is higher than word-level accuracy, with free-flow text showing lower performance than isolated characters. Segmentation failures contribute significantly to errors, especially in free-flow text, where word-level accuracy is notably lower. Misclassification rates are higher for words than for isolated characters, indicating challenges in handling cursive and connected text.
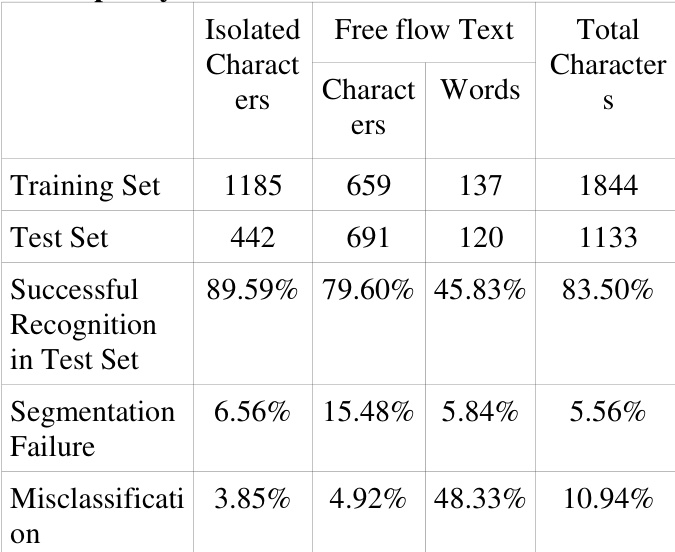
The authors evaluate the performance of the Tesseract OCR engine on handwritten lowercase Roman script, focusing on character and word recognition accuracy. Results show that the system achieves moderate character-level accuracy but struggles with segmentation, particularly for certain characters, leading to significant errors at the word level. The analysis reveals that a substantial portion of failures stems from over-segmentation and challenges in recognizing cursive text. The system exhibits high failure rates for specific characters, particularly the letter 'i', which contributes significantly to overall misclassification. Word-level accuracy is substantially lower than character-level accuracy due to segmentation issues. The majority of recognition errors are attributed to over-segmentation and challenges in handling cursive text.
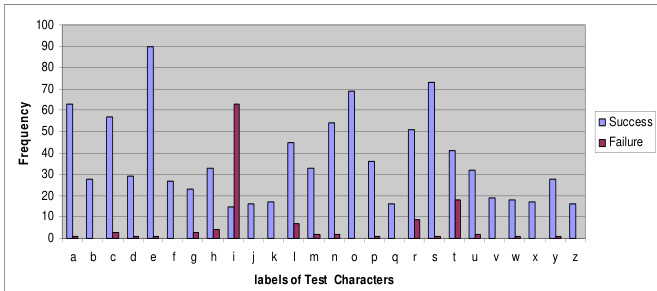
The authors evaluate the Tesseract OCR engine on handwritten lowercase Roman script to assess its character and word recognition capabilities across isolated and connected text samples. The experiments validate that character-level recognition consistently outperforms word-level accuracy, with performance degrading significantly for free-flow and cursive handwriting. Qualitative analysis reveals that segmentation failures, particularly over-segmentation, serve as the primary source of errors rather than fundamental recognition limitations. Consequently, the system demonstrates notable difficulty processing continuous text, establishing segmentation as the critical bottleneck for practical application.