Command Palette
Search for a command to run...
データセットのコンパイル | NVIDIA、OpenAI、および複数の研究機関からのオープンソース推論データセット。数学、パノラマ空間、Wiki質問応答、研究タスク、視覚的常識などを網羅しています。

大規模モデルが単に「話したり書いたりできる」ことから「推論したり考えたりできる」ことへと進化するにつれて、データの重要性が再定義されつつある。
かつては、大規模な汎用コーパスが言語モデルの表現力を支えていましたが、今日では、モデルの限界を決定づける真の障壁は、明確な構造、厳密な論理、そして多段階の推論プロセスを備えた推論データへと徐々に移行しつつあります。複雑な数学的問題、異分野知識に基づく質問応答、多段階の意思決定やツール呼び出し機能など、いずれも高品質な推論データセットのサポートに依存しています。
推論データセットは、数学や論理に焦点を当てたり、合成によって複雑な推論連鎖を構築したりすることができます。また、マルチタスク能力の評価や、科学的なベンチマーク、質問応答システムの最適化にも利用できます。しかし、これらのデータリソースは断片化が著しく、多くの場合異なる形式で存在するため、統一的に使用することが困難です。そのため、多くの開発者や研究者は、「データを探す」だけでかなりの時間を費やしています。
したがって、HyperAIは、マルチドメイン、マルチタスク推論、合成推論トレーニングデータ、科学研究ベンチマーク、大規模質問応答データなど、高品質な推論データセットを収集しました。また、データセットのダウンロードやオンラインでの利用もサポートしており、推論データセットの利用における参入障壁を低くしています。
より高品質なデータセット:
Open-RL推論問題データセット
* オンラインで利用する:
Open-RLは、2026年にTuringによって公開された、複数の領域にわたる推論問題データセットであり、物理学、数学、生物学、化学における、独立した、検証可能な、明示的なSTEM推論問題が含まれています。
各問題は複数段階の推論を必要とし、記号演算や数値計算を伴い、客観的に検証可能な最終解答を持ちます。このデータセットは、強化学習の微調整、報酬モデリング、結果に基づく教師あり学習、および検証可能な推論ベンチマークに適しています。
CHIMERA一般推論合成データセット
* オンラインで利用する:
CHIMERAは、推論トレーニング専用に設計された合成推論データセットであり、幅広いSTEM分野を網羅し、長い思考連鎖(CoT)の軌跡を提供します。
このデータセットには、8つの科目(数学、コンピュータサイエンス、化学、物理学、文学、歴史、生物学、音声学)にわたる9,225の質問が含まれています。すべての例は大規模言語モデル(LLM)によって生成され、手動によるアノテーションなしで自動的に検証されます。
被験者の分布:
* 数学: 4,452
コンピュータサイエンス:1,303
化学:1,102
物理学:742
*文献:504
*歴史: 422
生物学:383
言語学:317
Nemotron-Math-v2 数学推論データセット
* オンラインで利用する:
Nemotron-Math-v2は、NVIDIA Corporationが公開した数学的推論データセットです。主に、構造化された数学的推論を実行するLLM(言語学習モデル)のトレーニング、ツール強化型推論と純粋言語推論の違いの研究、および長文脈またはマルチトラック推論システムの構築に使用されます。
このデータセットには、約347,000件の高品質な数学問題と、モデルによって生成された700万件の推論軌跡が含まれています。各問題は、推論深度が高/中/低、Python TIRの有無の6つの構成で解かれ、LLMをアービターとして用いたパイプラインによって検証されます。
OmniSpatial パノラマ空間推論ベンチマークデータセット
* オンラインで利用する:
OmniSpatialは、2025年に清華大学が上海宇宙技術高等研究所、上海人工知能研究所、その他の機関と共同で公開した、パノラマ空間推論ベンチマークデータセットです。関連論文のタイトルは「OmniSpatial:視覚言語モデルのための包括的な空間推論ベンチマークに向けて」で、視覚言語モデルの空間理解の評価におけるギャップを埋めることを目的としています。
このデータセットには、動的推論、複雑な空間論理、空間相互作用、視点取得という 4 つの主要な空間推論タスクのカテゴリを網羅する、約 1,533 の画像質問応答サンプルが含まれており、合計 50 のサブタスクがあります。データ ソースは、インターネット画像、心理テスト、運転免許試験問題など多岐にわたります。注釈は、品質と多様性を確保するために複数回のレビューを受けています。従来のベンチマークと比較して、OmniSpatial はテンプレートベースの構築を避け、現実世界の複雑なシナリオにより近いものとなっています。基本的な空間関係 (前後、左右、距離など) をテストするだけでなく、複数オブジェクトの相互作用、シーンの変化、および異なる視点からの推論も重視しています。
このデータセットは、特にインテリジェントナビゲーション、拡張現実(AR)、仮想現実(VR)、複雑なシーン理解といったアプリケーションにおいて、大規模マルチモーダルモデルの空間推論能力の学習と評価に適しています。包括的かつ挑戦的な標準化ベンチマークデータセットです。
FrontierScience推論研究タスク評価データセット
* オンラインで利用する:
FrontierScienceは、OpenAIが2025年に公開した、推論および科学研究タスクを評価するためのデータセットです。専門家レベルの科学的推論および科学研究のサブタスクにおける大規模モデルの能力を体系的に評価することを目的としています。
このデータセットは、「専門家の作成 + 2 層のタスク構造 + 自動採点メカニズム」という設計メカニズムを採用しており、クローズドエンドの精密推論とオープンエンドの科学的研究推論の 2 種類の能力に対応する 2 つのサブセットに分かれています。
オリンピックデータセット
元々は国際物理オリンピック、化学オリンピック、生物学オリンピックのメダリストやナショナルチームのコーチによって設計されたこれらの問題は、IPhO、IChO、IBOなどのトップレベルの国際大会に匹敵する難易度です。短答式の推論問題に焦点を当てたこのモデルは、結果の検証可能性と自動評価の安定性を確保するために、単一の数値、代数式、またはあいまい一致可能な生物学的用語を出力する必要があります。
研究データセット
博士課程の学生、ポスドク研究員、教授陣によって作成されたこれらの問題は、物理学、化学、生物学という3つの主要分野を網羅し、実際の科学研究で遭遇する可能性のある副次的な問題をシミュレートしています。各問題には、解答の正誤だけでなく、モデリングの前提条件の完全性、推論経路、中間結論など、いくつかの重要な側面におけるモデルのパフォーマンスを評価するための、きめ細かな10点満点の採点システムが付属しています。
HotpotQA の質問と回答のデータ セット
* オンラインで利用する:
HotpotQAデータセットは、英語版ウィキペディアから収集された大規模な質疑応答データセットで、113,000件のクラウドソーシングによる質問が含まれています。これらの質問に答えるには、2つのウィキペディア記事の冒頭部分を参照する必要があります。
各質問には、正解となる2つの段落と、その段落から抜粋したいくつかの文のリストが含まれています。これらの文は、質問に答えるために必要と思われる裏付けとなる事実を提供します。このデータセットには、以下の特徴があります。
この質問に答えるには、複数の関連資料を調べ、論理的に検討する必要がある。
* 問題は多岐にわたり、既存の知識ベースや知識モデルによって限定されるものではありません。
このデータセットは、推論に必要な文レベルの裏付けとなる事実を提供し、QAシステムが強力な監視下で推論を行い、予測を解釈することを可能にする。
このデータセットは、関連する事実を抽出し、必要な比較を行うQAシステムの能力をテストするための、斬新な事実比較問題を提示する。
VCR 視覚常識推論データ セット
* オンラインで利用する:
VCR (Visual Commonsense Reasoning の正式名) は、視覚的な常識推論のための大規模なデータ セットです。このデータセットは画像に関する難しい質問を提起しており、マシンは質問に正しく答えることと、その答えを正当化する理由を提供することという 2 つのサブタスクを完了する必要があります。
VCR データセットには、トレーニング用に 212K、検証用に 26K、テスト用に 25K という多数の質問が含まれています。答えと理由は、110,000 を超えるユニークな映画のシーンから得られます。

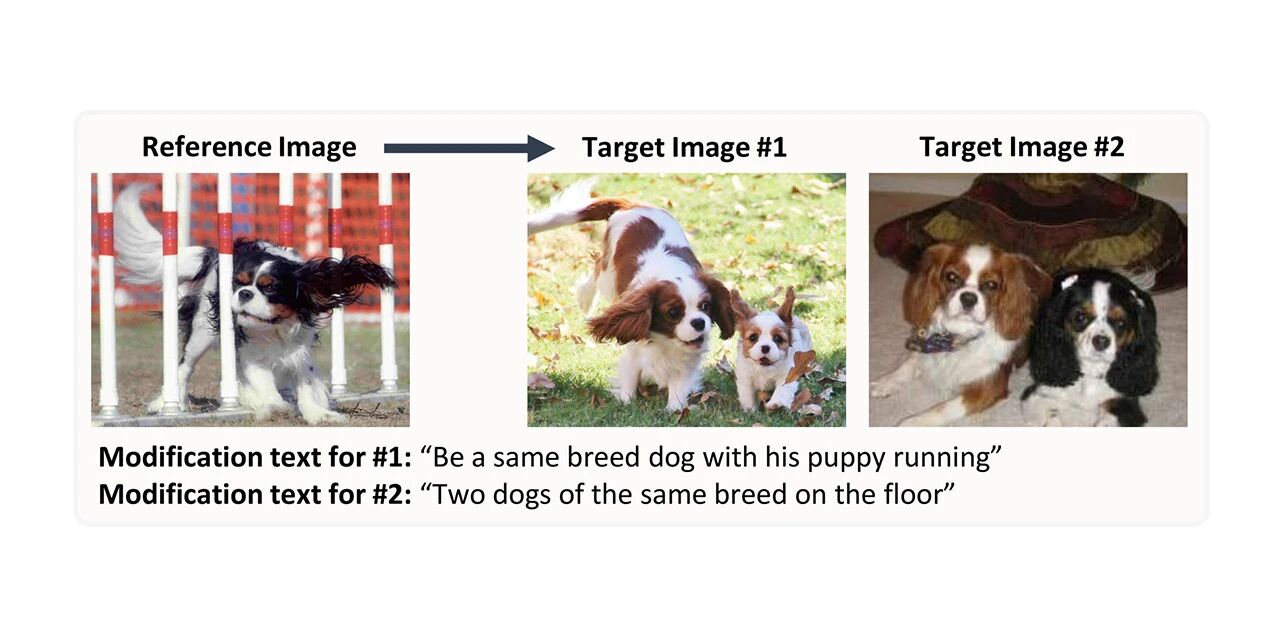
CIRR画像合成検索データセット
* オンラインで利用する:
CIRR は Compose Image Retrieval on Real-life image の略で、クラウドソーシングされたオープンドメインの画像と手動で生成された修正テキストが 36,000 組以上含まれています。このデータセットは、視覚的な言語概念の微妙な推論と対話による反復検索に関する将来の研究を促進することを目的としており、オープンドメインで視覚的に類似した画像を区別することに重点を置くことで既存のデータセットの欠点に対処します。