HyperAI
Command Palette
Search for a command to run...
WideSearch情報収集ベンチマークデータセット
※本データセットはオンライン利用に対応しておりますが、ここをクリックしてジャンプしてください。
WideSearchは、2025年にByteDanceのSeedチームによってリリースされた「広範な情報探索」向けに設計された最初のエージェント評価ベンチマークデータセットです。関連する論文の結果は次のとおりです。WideSearch:エージェントによる広範な情報探索のベンチマーク大規模な事実収集、統合、検証可能な構造化出力における大規模言語モデルの信頼性と整合性を体系的に評価し、促進することを目的としています。 このベンチマークは、実際のユーザークエリから研究チームが厳選し、手作業でクリーンアップした200個の高品質な質問(英語100個、中国語100個)で構成されています。これらの質問は15以上の異なる分野から集められています。
データフィールド:
- instance_id: タスクの一意の ID (ゴールド CSV ファイル名に対応)。
- クエリ: 通常、必要な列名と Markdown テーブルの出力要件を指定する自然言語の命令。
- 評価: 自動評価に使用されるシリアル化された (文字列) オブジェクト。次の内容が含まれます。
- unique_columns: 主キー列(行の位置合わせ用)
- 必須: 表示する必要がある列名。
- eval_pipeline: 列レベルの評価構成 (前処理、メトリック、基準など)。
- language: タスクの言語。値は en または zh になります。
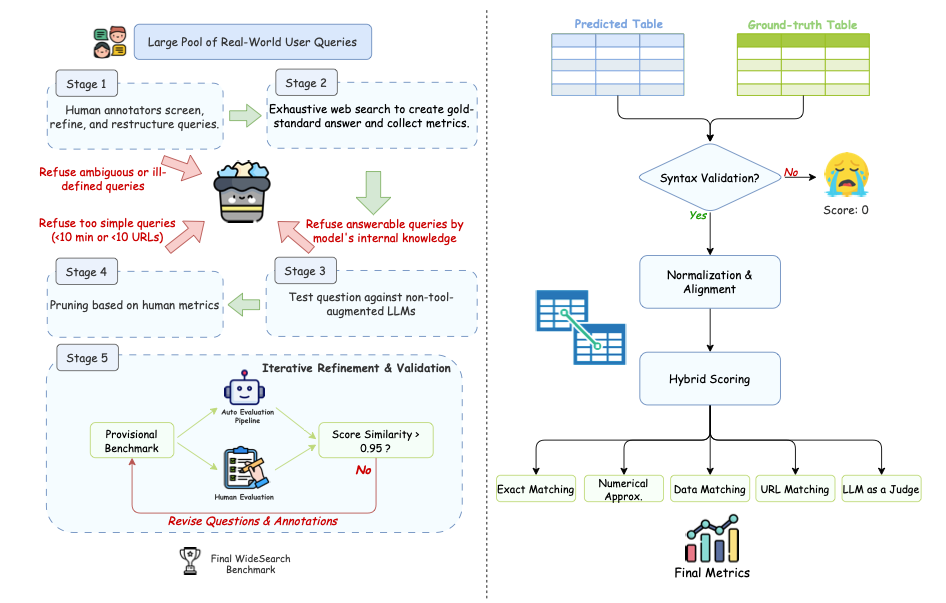
データ構築と自動評価フローチャート
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。