HyperAI
Command Palette
Search for a command to run...
LLM4Mat-Bench結晶構造データセット
LLM4Mat-Benchは、プリンストン大学、トロント大学などが共同で作成した、材料特性予測のためのマルチモーダル言語モデル評価データセットです。関連する論文の結果は「LLM4Mat-Bench: 材料特性予測のための大規模言語モデルのベンチマーク”は、材料特性予測および材料発見タスクにおける大規模言語モデル(LLM)の性能を評価することを目的としています。このデータセットには、10の公開材料データベースから約197万件の結晶構造サンプルが含まれており、45種類の異なる材料の物理的および化学的特性をカバーしています。これは、材料特性予測における大規模言語モデル(LLM)の性能を評価するための、これまでで最大のベンチマークです。
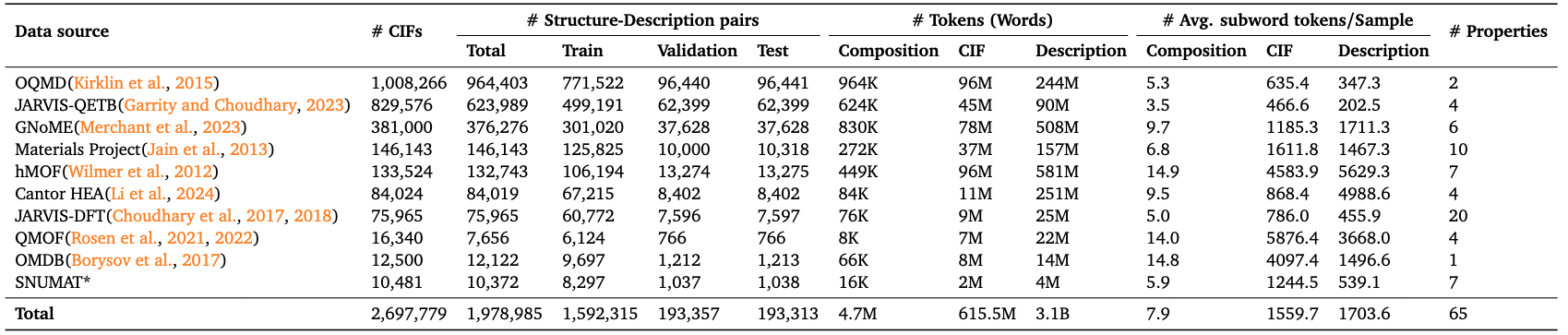
データの総量:
- 結晶合成モード(合成):約470万トークン
- 結晶構造モード(CIF):約6億1550万トークン
- テキスト説明: 約31億トークン このデータセットを構築するプロセスには、複数の主流の材料データベースから元の CIF ファイルと材料特性を収集し、結晶構造に基づいて構造言語記述を自動的に生成し、それによってマルチモーダルで統一された構造データ サンプルを形成することが含まれます。各サンプルレコードには、対応する材料ID、化学式、特性値(バンドギャップ、形成エネルギー、密度、弾性率など)、その他の情報が含まれています。 LLM4Mat-Bench の主な目標は、材料科学と自然言語処理の相互統合を促進し、タスク固有のモデル評価、特性予測、命令の微調整の分野での研究とアプリケーション開発を促進することです。マルチソース、マルチモーダル、大規模という特性により、マテリアル言語モデルの研究における重要な基準ベンチマークとなっています。
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。