Command Palette
Search for a command to run...
ムハラフ氏手書きのアラビア語データセット
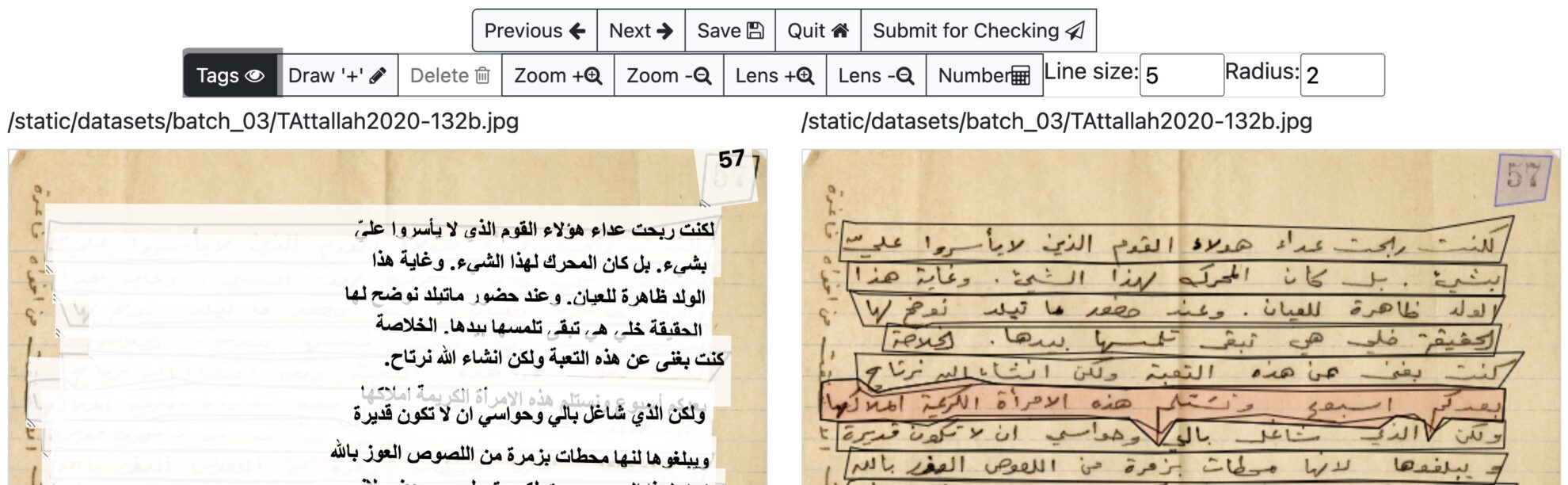
Muharaf データセットは、2024 年に Mehreen Saeed らによって作成された、手書きのアラビア語認識に焦点を当てた機械学習データセットです。ムハラフ: 筆記体認識用の手書きアラビア語データセットの写本」が NeurIPS 24 に受理されました。このデータセットには、アーカイブ アラビア語の専門家によって転写された歴史的な手書きのページの 1.6k 以上の画像が含まれています。各ドキュメント画像には、そのテキスト行の空間ポリゴン座標と、基礎となるページ要素に関する情報が伴います。 Muharaf データセットは、アラビア語写本だけでなく結合テキストの認識についても、手書きテキスト認識 (HTR) 分野の技術進歩を促進するために構築されました。 このデータセットには、個人的な手紙、日記、メモ、詩、教会の記録、法的通信など、多様な書き方と幅広い種類の文書が含まれています。研究論文の中で、著者らはデータ取得プロセス、データセットの顕著な特徴と統計について説明し、これらのデータを使用して畳み込みニューラル ネットワークをトレーニングした結果の予備的なベースライン結果を提供します。 Muharaf データセットは 2 つの部分に分かれています。公開部分には 1,216 個の画像が含まれ、CC BY-NC-SA 4.0 ライセンスに基づいて配布されます。制限付き部分には 428 個の画像が含まれ、独自のライセンスに基づいて配布され、レバノン人カルロス・ユネス研究フェニックスセンターをダウンロードしてください。このデータは研究目的のみであり、再配布は許可されていません。さらに、Muharaf データセットは ScribeArabic 注釈ソフトウェアを使用して作成されており、ソフトウェアのマニュアルはユーザーがその仕組みを理解するのに役立ちます。データセット内の画像ファイルは、対応する注釈、転写、タグとともに、PAGE-XML ビューアを使用して表示できます。