Command Palette
Search for a command to run...
ペルソナ ハブ Web データから自動的にキュレーションされた 10 億の固有ペルソナのデータセット
データセットの紹介
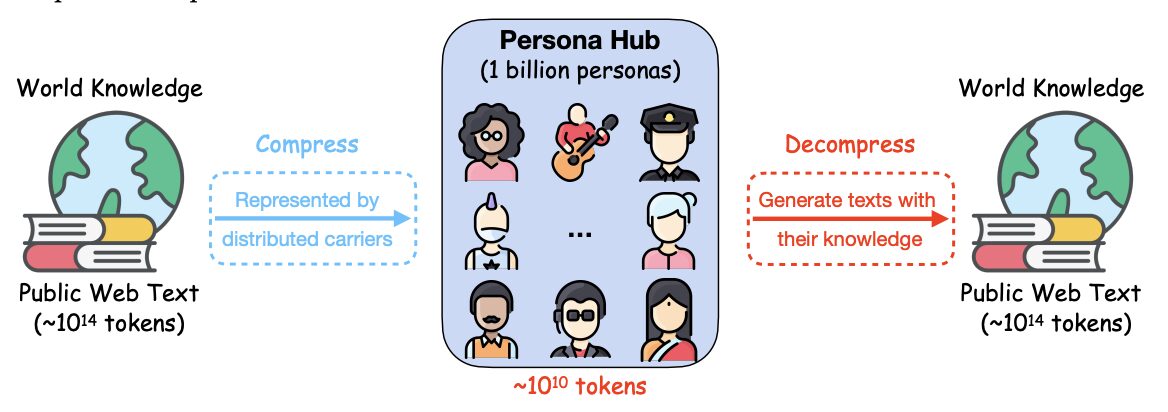
このデータセットは、2024 年にテンセントのシアトル人工知能研究所によって開始されたネットワーク データから自動的に整理された 10 億の異なる文字のコレクションです。これらの 10 億文字 (世界の総人口の約 13%) は、世界の知識の分散キャリアとして機能し、LLM にカプセル化されたほぼすべての視点を活用できるため、さまざまなシナリオ向けの多様な合成データの大規模な作成が容易になります。研究チームは、高品質の数学的および論理的推論の質問、指示 (つまり、ユーザー プロンプト)、知識豊富なテキスト、ゲーム NPC、およびツール (機能) を大規模に合成する際の PERSONA HUB の使用例を実証することで、キャラクターがいかに多用途であるかを実証しています。 -ドリブンなデータ合成は、機能的でスケーラブルで柔軟性があり、使いやすいため、合成データの作成と実用化におけるパラダイムシフトを促進する可能性があり、LLM の研究開発に大きな影響を与える可能性があります。 関連論文は「1,000,000,000 人のペルソナによる合成データ作成のスケーリング」
データセットの背景
Tencent のシアトル人工知能研究所は、大規模言語モデル (LLM) の複数の視点を活用して多様な合成データを作成する、新しいロール駆動型のデータ合成手法を開始しました。研究者らは、ネットワークデータから10億種類(世界総人口の約13%)の異なるキャラクターを自動的に選別する「ペルソナハブ」と呼ばれるシステムを立ち上げた。世界の知識を分散して伝達するこれらの役割は、LLM に含まれるほぼすべての視点に到達できるため、さまざまなシナリオ向けの多様な合成データを大規模に作成することが容易になります。この技術レポートでは、データ セキュリティ、既存の LLM リーダーシップに対する脅威、仮想世界で現実社会をシミュレートする可能性など、ペルソナ ハブの使用から生じる可能性のある広範な影響と倫理的問題についても説明します。