HyperAI
Command Palette
Search for a command to run...
Firefly Chinese Llama2 増分事前トレーニング データ セット
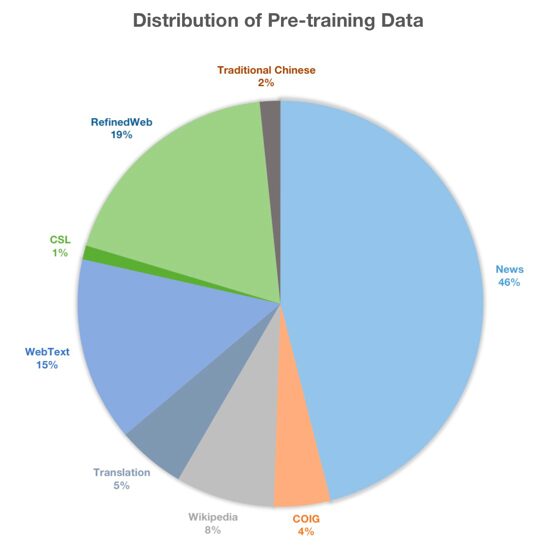
データセットは Firefly-LLaMA2-中国語プロジェクト 増分事前トレーニング データ (合計約 22 GB のテキスト) には、主に CLUE、ThucNews、CNews、COIG、Wikipedia などのオープンソース データ セットと、古代詩、散文、古典中国語などが収集されています。研究チームのデータ分布は以下の通り。
firefly-pretrain-dataset.torrent
シーディング 1ダウンロード中 0完了 169総ダウンロード数 278
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。