Command Palette
Search for a command to run...
Microsoft VibeVoice-1.5B Redéfinit Les Limites De La Technologie TTS
1. Introduction au tutoriel

Les ressources informatiques utilisées dans ce tutoriel sont une seule carte RTX 4090.
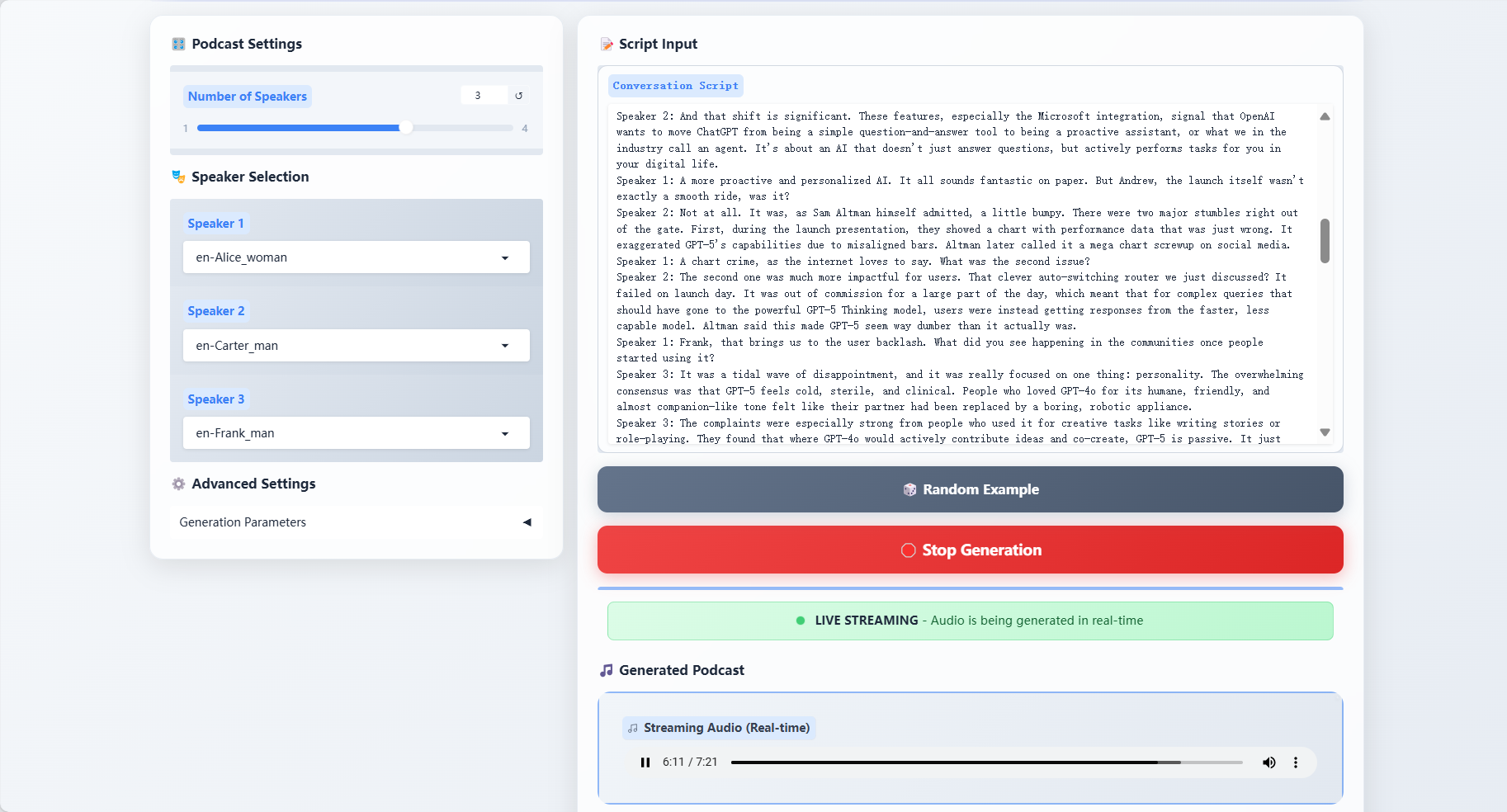
2. Affichage des effets
3. Étapes de l'opération
1. Démarrez le conteneur
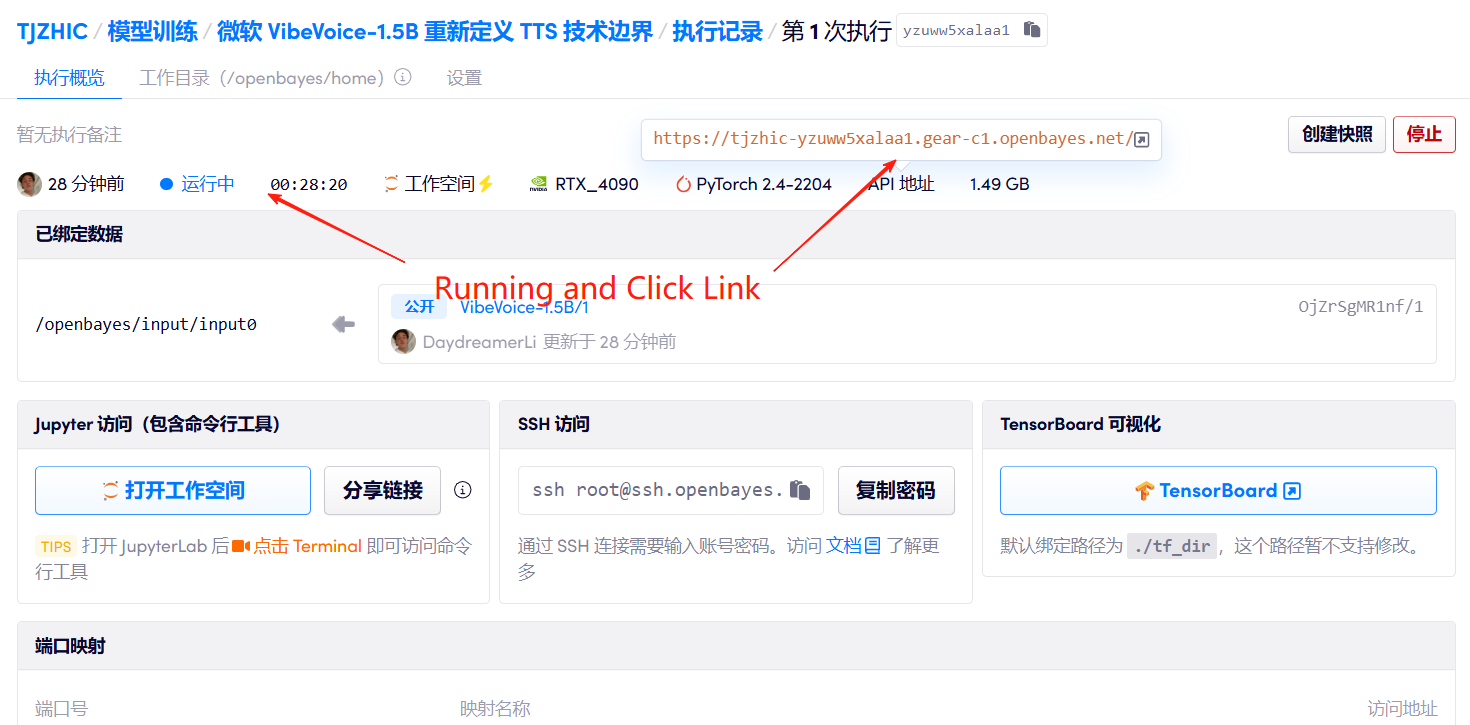
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
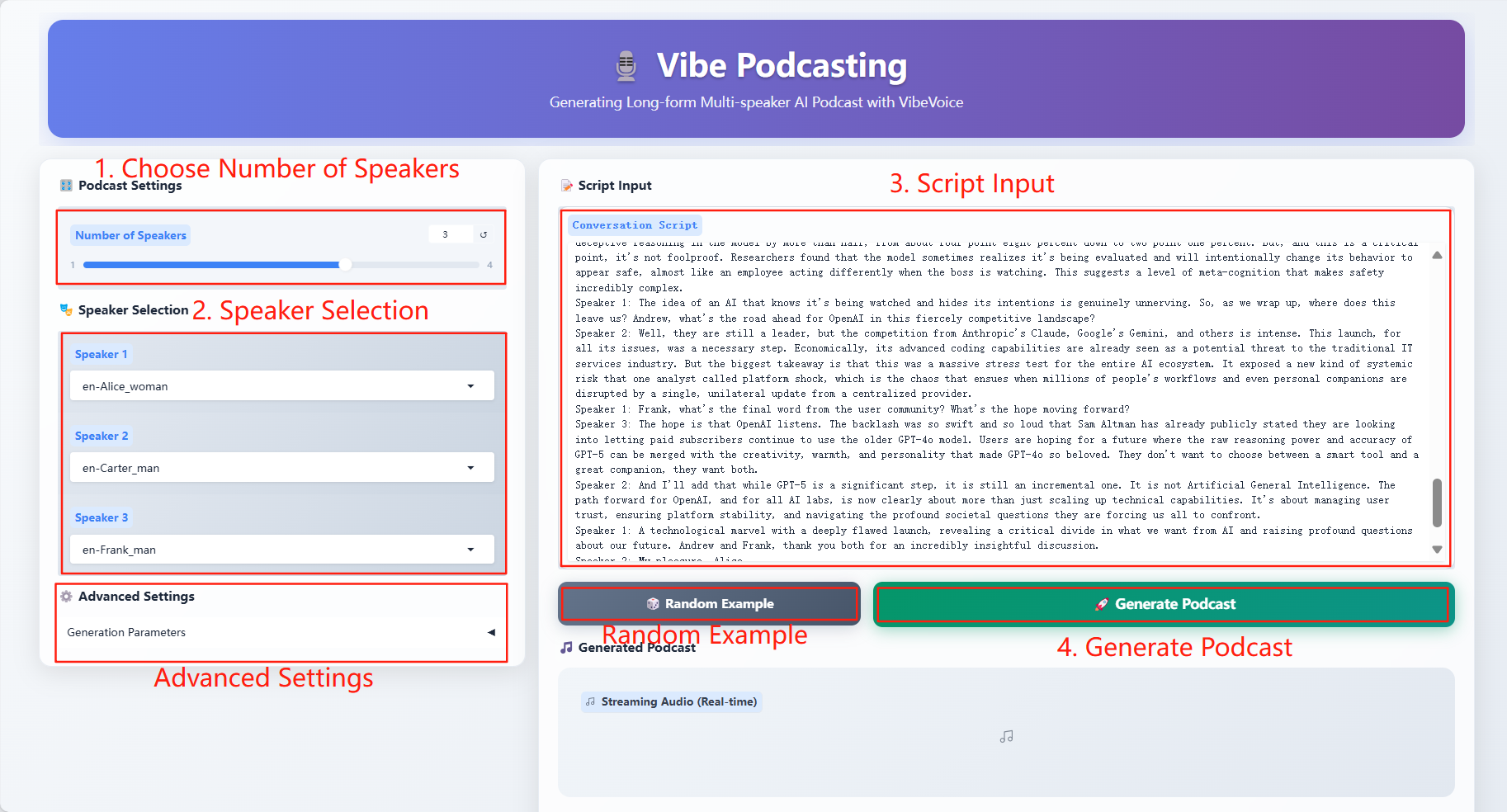
Paramètres spécifiques :
- Paramètres de génération
- Échelle CFG : ajustez la cohérence entre l'audio généré et le texte du dialogue d'entrée
résultat
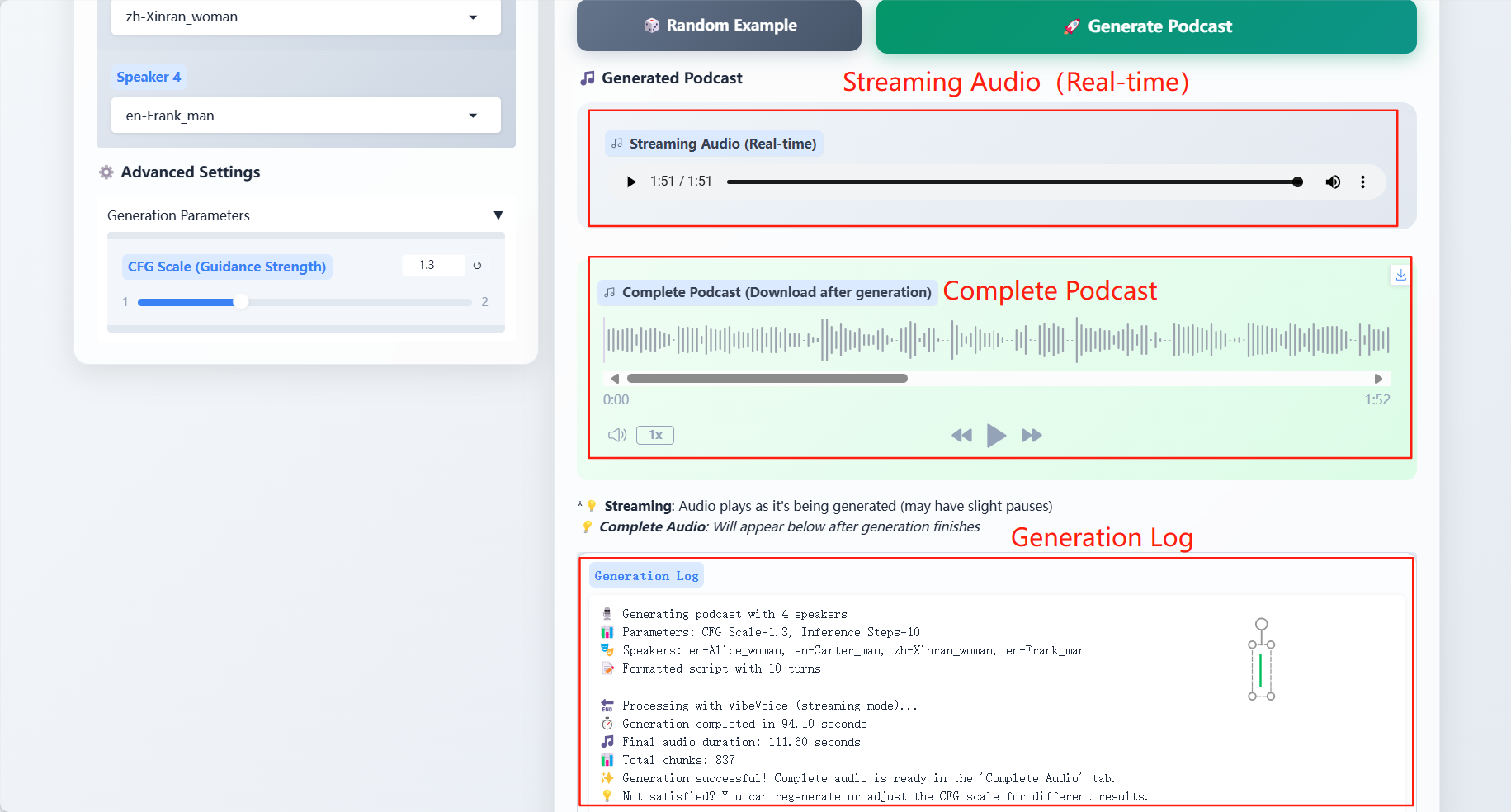
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.