Command Palette
Search for a command to run...
Démonstration Du Modèle De Compréhension Vocale Voxtral-Small-24B-2507
1. Introduction au tutoriel
Voxtral est un modèle audio avancé lancé par Mistral AI en juillet 2025. Grâce à son excellente transcription vocale et à ses capacités de compréhension approfondie, il favorise la voix comme moyen naturel d'interaction homme-machine. Voxtral est disponible en versions 24B et 3B, adaptées respectivement à la production et au déploiement local. Voxtral prend en charge plusieurs langues, le contexte de texte long, des fonctions intégrées de questions-réponses et de résumé, et peut déclencher directement des appels de fonctions backend. Les performances de Voxtral surpassent celles des modèles open source et des API propriétaires existants dans de nombreux benchmarks, tout en étant plus économique et largement utilisé dans divers scénarios, contribuant ainsi à populariser l'interaction vocale.
Caractéristiques principales :
- Traitement contextuel de texte long : prend en charge jusqu'à 30 minutes de transcription audio et 40 minutes de compréhension audio, et peut gérer un contenu long et complexe.
- Questions-réponses et résumé intégrés : posez des questions directement sur le contenu audio ou générez des résumés structurés sans avoir besoin de modèles ASR et de langage supplémentaires.
- Prise en charge multilingue : détection automatique de la langue, prise en charge de plusieurs langues courantes (telles que l'anglais, l'espagnol, le français, le portugais, l'hindi, l'allemand, etc.) pour répondre aux besoins des utilisateurs du monde entier.
- Appels de fonction déclenchés par la voix : déclenchez directement des fonctions backend, des workflows ou des appels d'API en fonction de l'intention vocale de l'utilisateur sans avoir besoin d'étapes d'analyse intermédiaires.
- Capacité de compréhension de texte : La capacité de compréhension de texte de Mistral Small 3.1 est conservée, prenant en charge la saisie et le traitement de texte.
- Performances de transcription optimisées : fournit des points de terminaison de transcription hautement optimisés, rentables et adaptés aux applications à grande échelle.
Les ressources informatiques de ce tutoriel utilisent une carte graphique RTX A6000 à double carte, et le modèle déployé est le Voxtral-Small-24B-2507. Deux fonctions, Transcription audio et Compréhension audio, sont fournies pour les tests.
Annexe : Déploiement en un clic de la démonstration du modèle 3B Voxtral
2. Affichage des effets
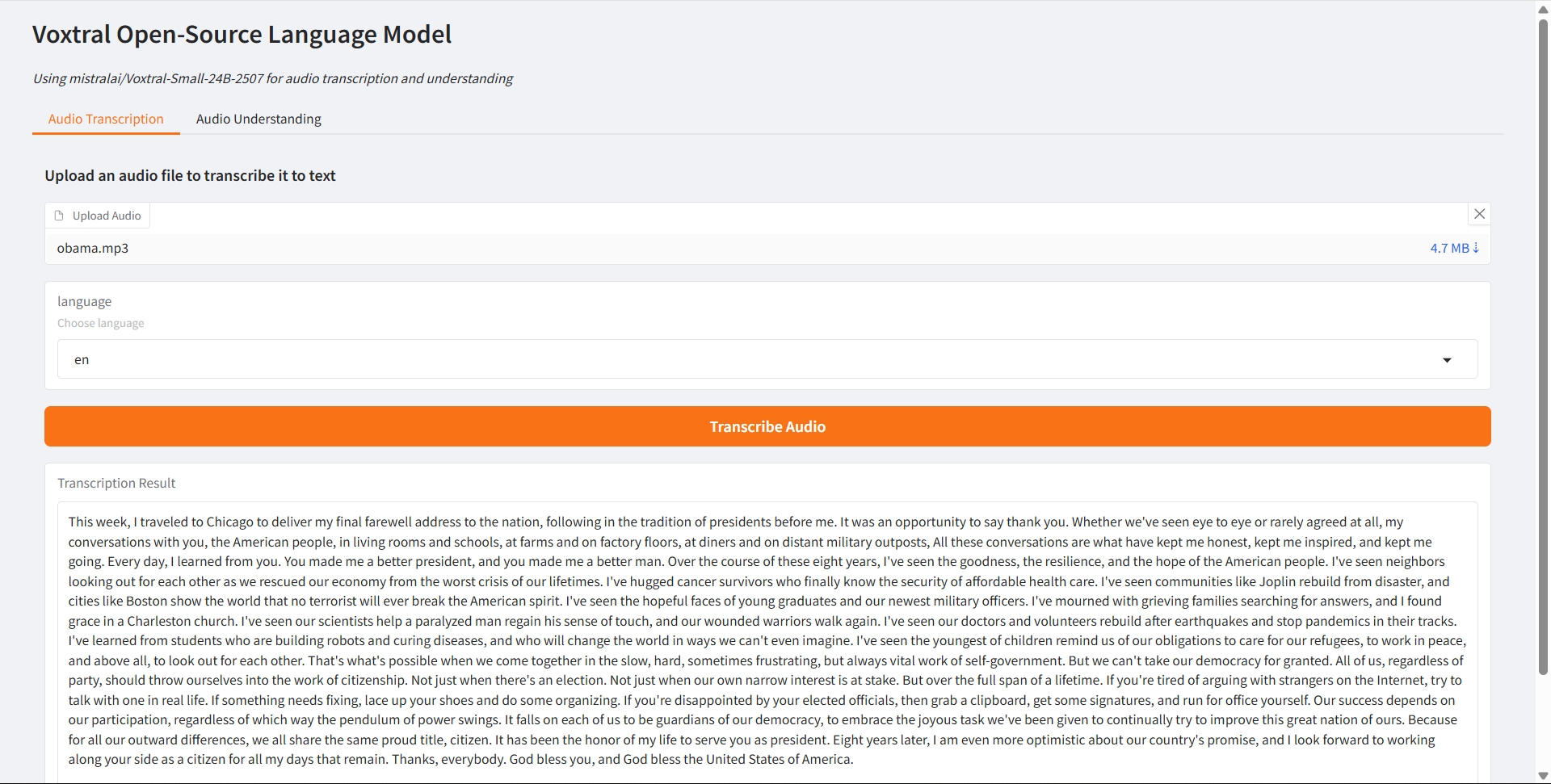
Transcription audio
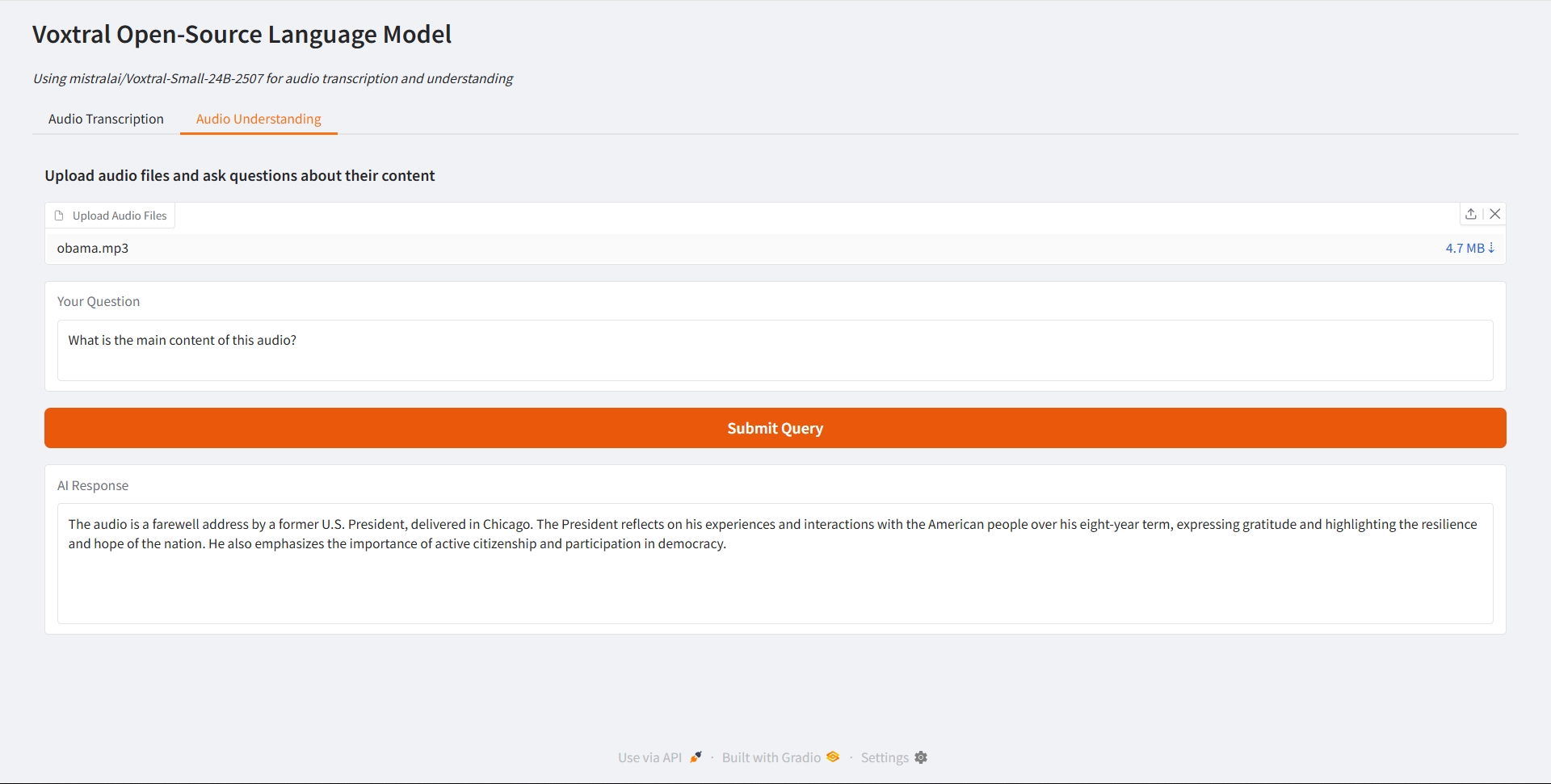
Compréhension audio
3. Étapes de l'opération
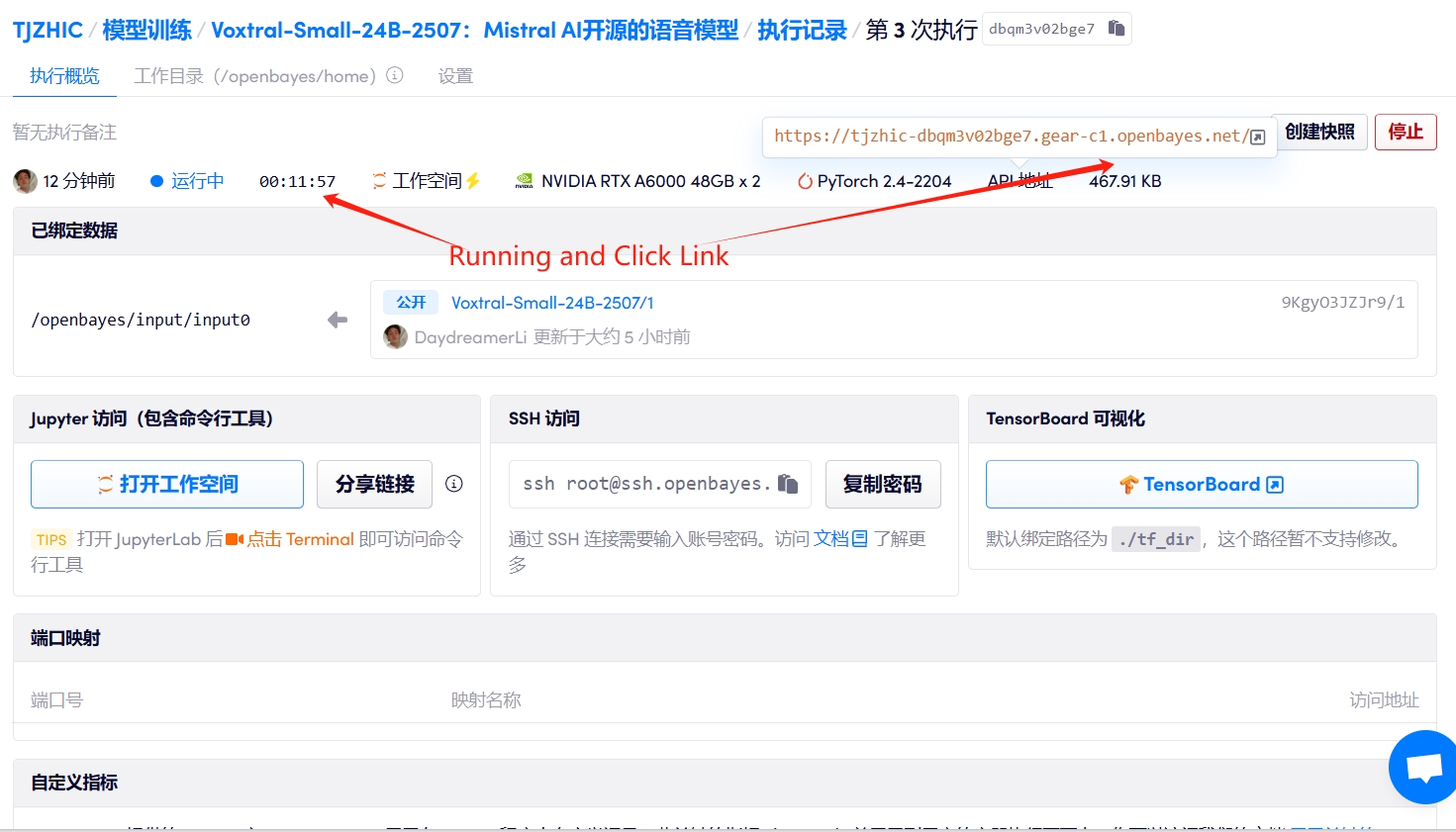
1. Démarrez le conteneur
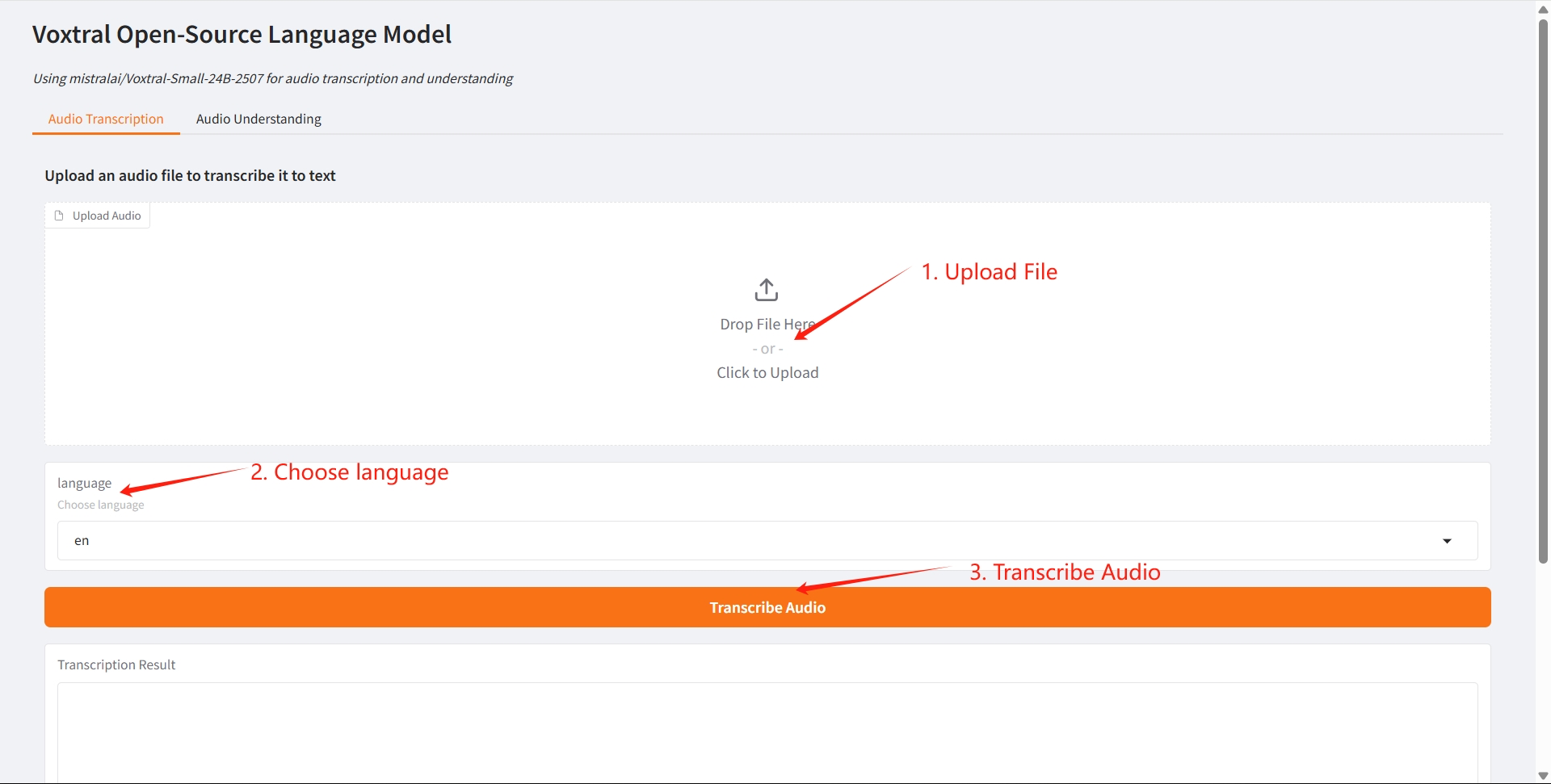
2. Étapes d'utilisation
Si le message « Passerelle incorrecte » s'affiche, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 5 à 10 minutes avant d'actualiser la page.
1. Transcription audio
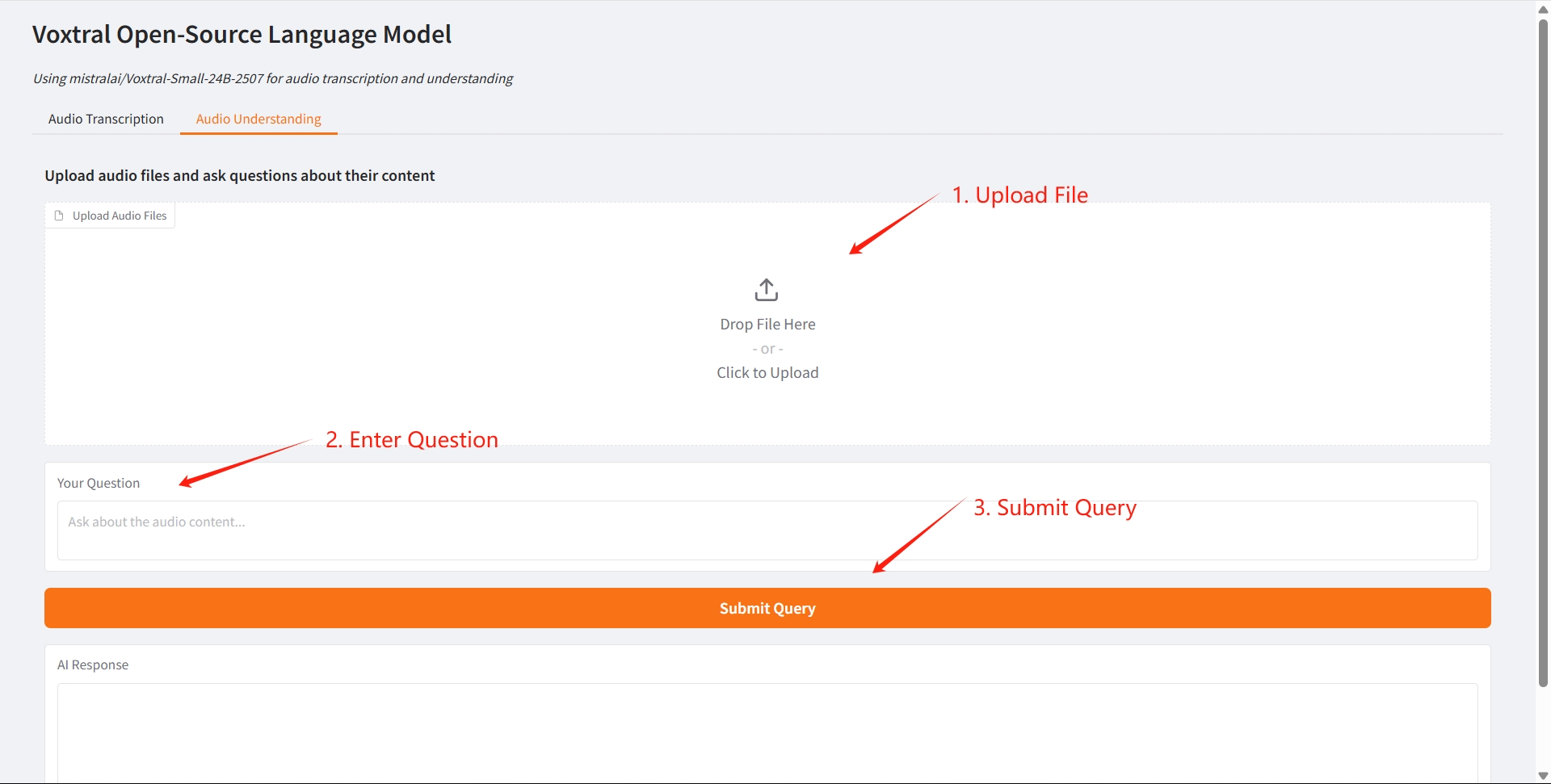
2. Compréhension audio
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.