Command Palette
Search for a command to run...
Chandra : OCR De Documents De Haute Précision
1. Introduction au tutoriel

Chandra est un système de reconnaissance optique de caractères (OCR) de haute précision développé par l'équipe Datalab-to en octobre 2025. Axé sur la reconnaissance de la mise en page et l'extraction de texte, Chandra traite directement les fichiers PDF et image, générant des sorties en texte structuré, Markdown et HTML, et fournissant des schémas de mise en page pour une inspection aisée des résultats de l'OCR.
Fonctionnalités principales :
- OCR de haute précisionOptimisé pour les mises en page de documents, de tableaux et à plusieurs colonnes, prenant en charge les mises en page complexes.
- Connaissance de l'agencementGénère des schémas de mise en page visuels, en marquant les blocs de texte, les tableaux et les zones d'image.
- Sortie multiformatPermet de télécharger des fichiers Markdown, HTML et texte brut.
- Déploiement simpleBasé sur l'interface Streamlit, il permet une interaction rapide dans le navigateur.
- Modèle légerVous pouvez charger directement le modèle à l'aide de Transformers sans avoir besoin d'ajouter une dépendance à vLLM.
Ce tutoriel utilise Streamlit pour déployer le modèle de base Chandra OCR, avec des ressources de calcul « RTX_5090 », permettant une inférence rapide des documents et une visualisation de la mise en page.
2. Affichage des effets
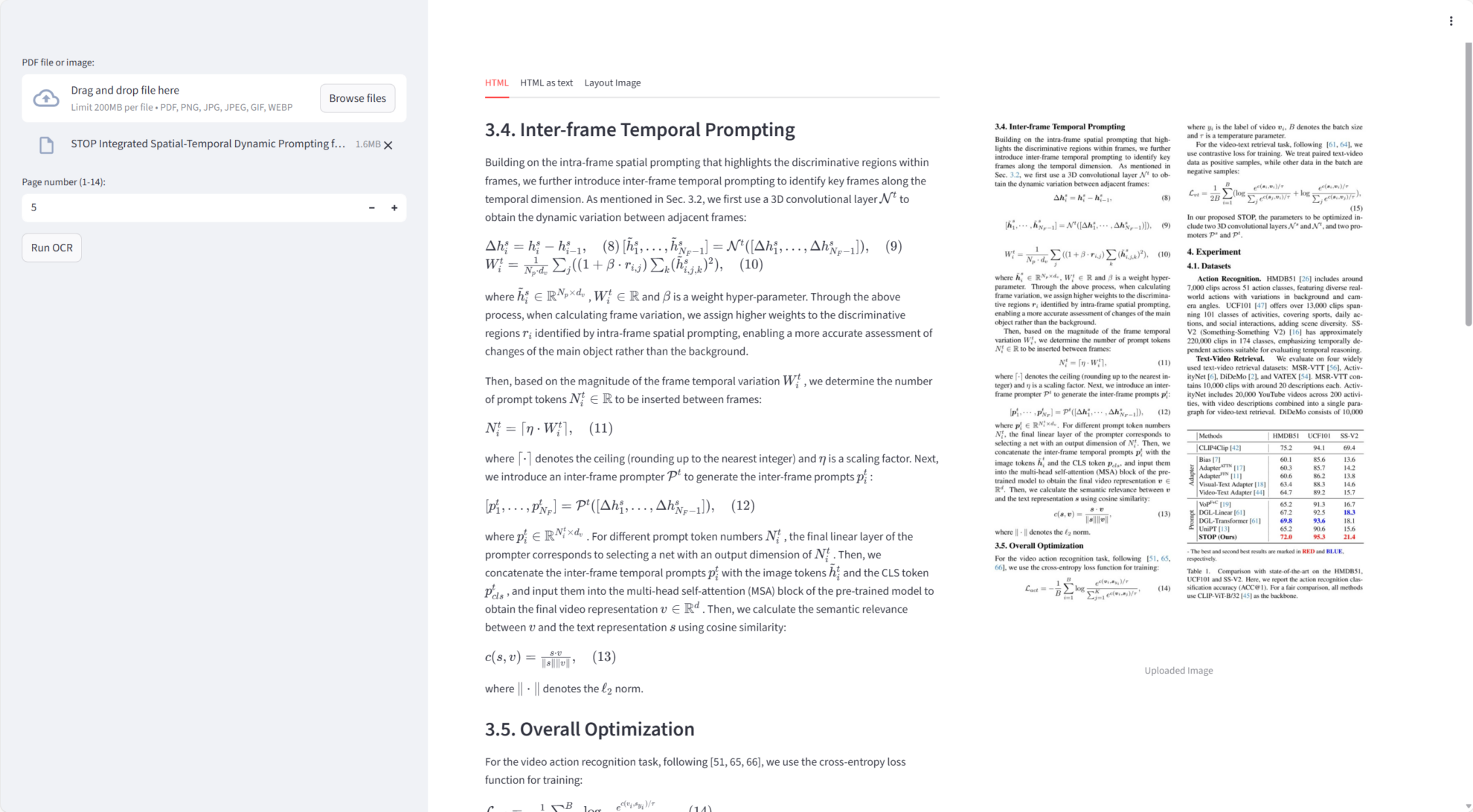
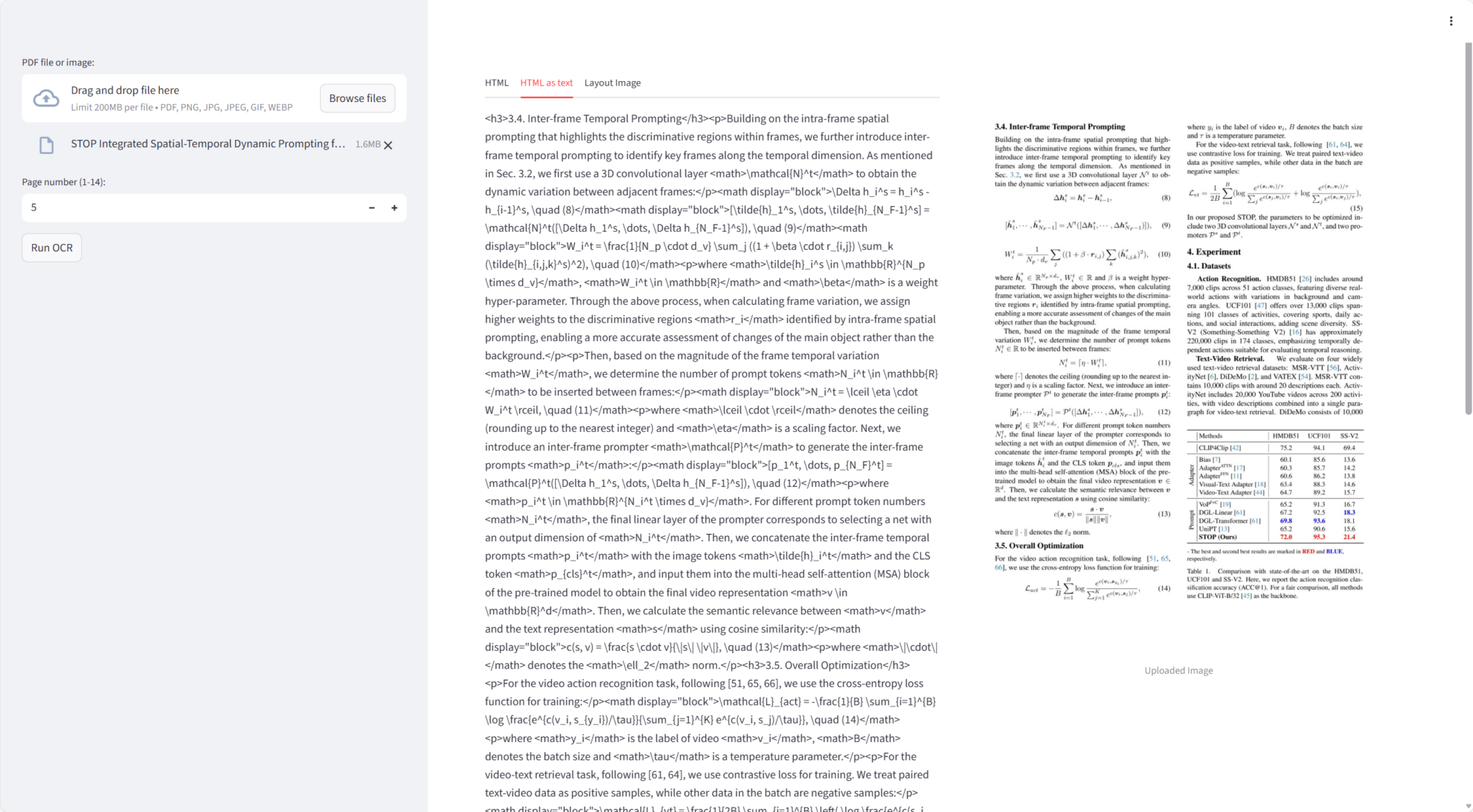

Chandra a accompli une performance exceptionnelle sur la mission principale :
- OCR de documents monopagesGénérez du texte et du Markdown de haute précision à partir de PDF ou d'images.
- Détection de la mise en pageIl identifie avec précision les zones telles que les blocs de texte, les tableaux et les images, et prend en charge la visualisation de la mise en page.
- Prise en charge des documents multipagesIl peut traiter les fichiers PDF par pages, la numérotation des pages commençant à 1 afin d'éviter les erreurs de dépassement de limites.
- Sortie Markdown et HTMLIntègre automatiquement les résultats de la reconnaissance optique de caractères (OCR) dans les formats Markdown ou HTML et prend en charge le téléchargement.
- Diagramme de disposition visuelleGénérer des images PIL des zones de texte annotées pour une vérification facile de la précision de la reconnaissance optique de caractères (OCR).
3. Étapes de l'opération
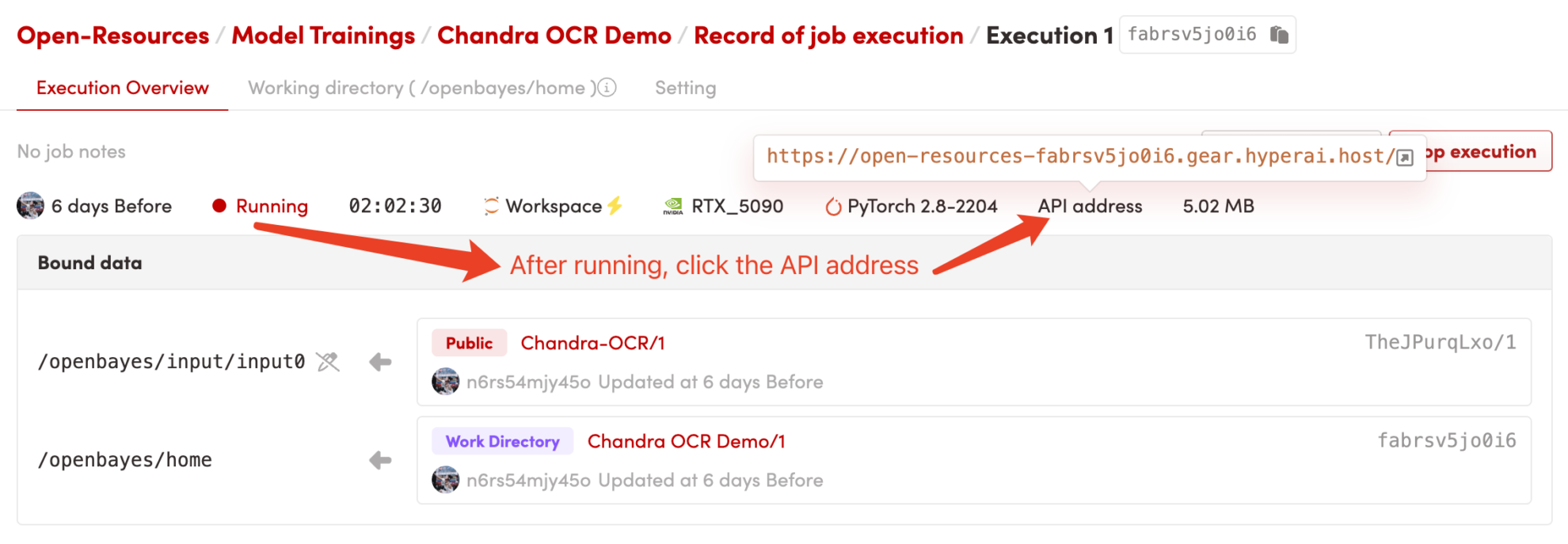
1. Démarrez le conteneur ou exécutez-le localement.
Après avoir démarré le conteneur, cliquez sur l'adresse de l'API pour accéder à l'interface web :
2. Guide de l'utilisateur
Si le message « Bad Gateway » s’affiche, cela signifie que le modèle est en cours d’initialisation. Veuillez patienter 1 à 2 minutes et actualiser la page.
indiceSi la page affiche « Exécution de load_model() », cela signifie que le modèle est en cours d'initialisation. Veuillez patienter 1 à 2 minutes, puis actualiser la page.


Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.