Command Palette
Search for a command to run...
Long-VITA : Une Démonstration De Compréhension Multimodale Avec Des Millions De Jetons
Date
Organisation
Balises
URL du document
GitHub
1. Introduction au tutoriel

Long-VITA est un modèle multimodal à grande échelle, fruit d'une recherche menée conjointement par le laboratoire Tencent YouTu, l'université de Nanjing et l'université de Xiamen, et publié en février 2025. Ce modèle conserve une précision remarquable avec des contextes courts, tout en pouvant traiter jusqu'à un million de jetons, permettant ainsi un traitement efficace des entrées multimodales telles que le texte et les images. L'article associé est intitulé « … ».Long-VITA : passage à l’échelle de grands modèles multimodaux jusqu’à 1 million de jetons avec une précision de contexte court inégalée".
Ce tutoriel utilise une seule carte graphique RTX 4090 et déploie un modèle Long-VITA-16K_HF.
2. Exemples d'effets
Conversation textuelle
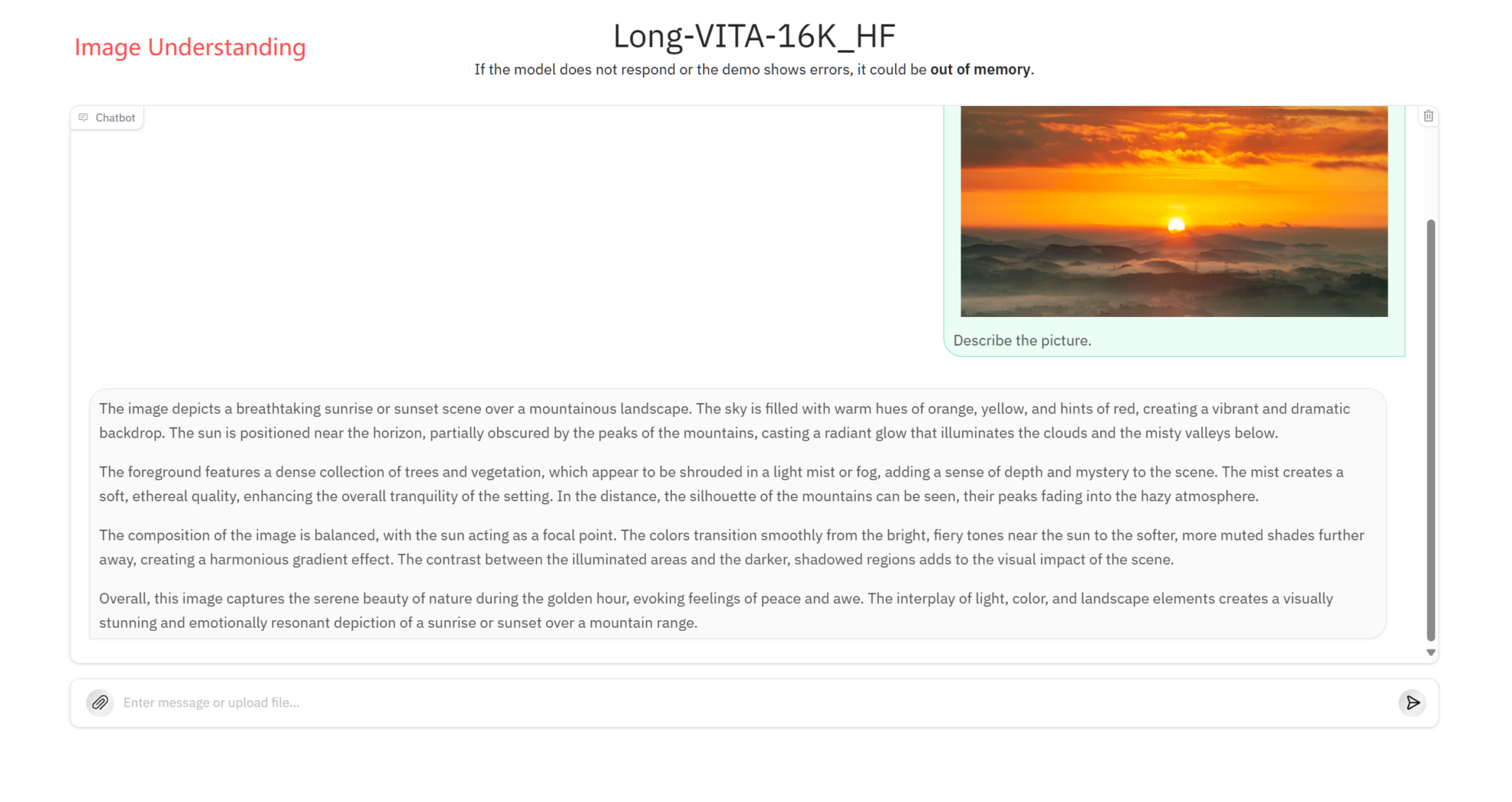
Compréhension de l'image
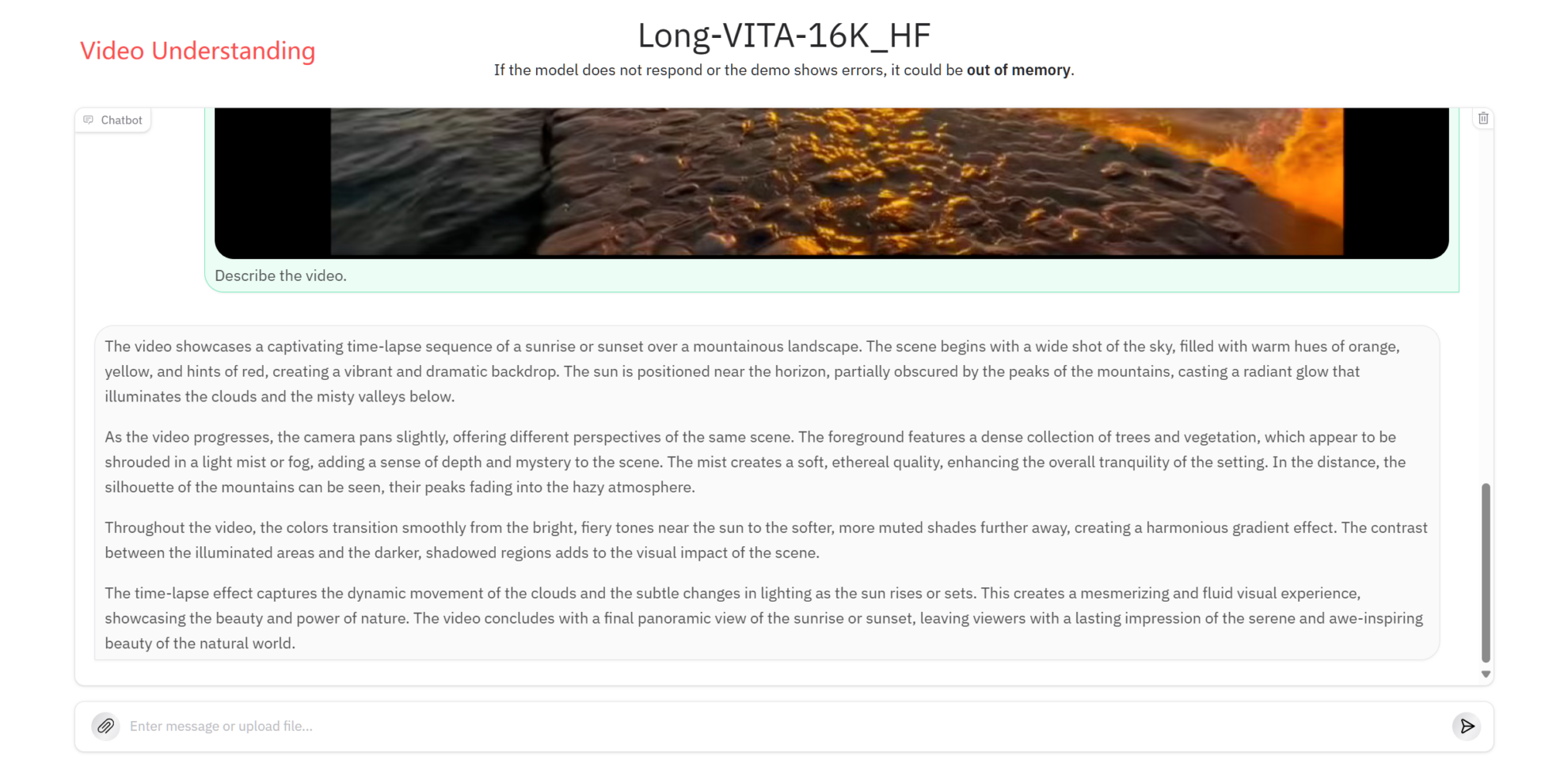
Compréhension de la vidéo
3. Étapes de l'opération
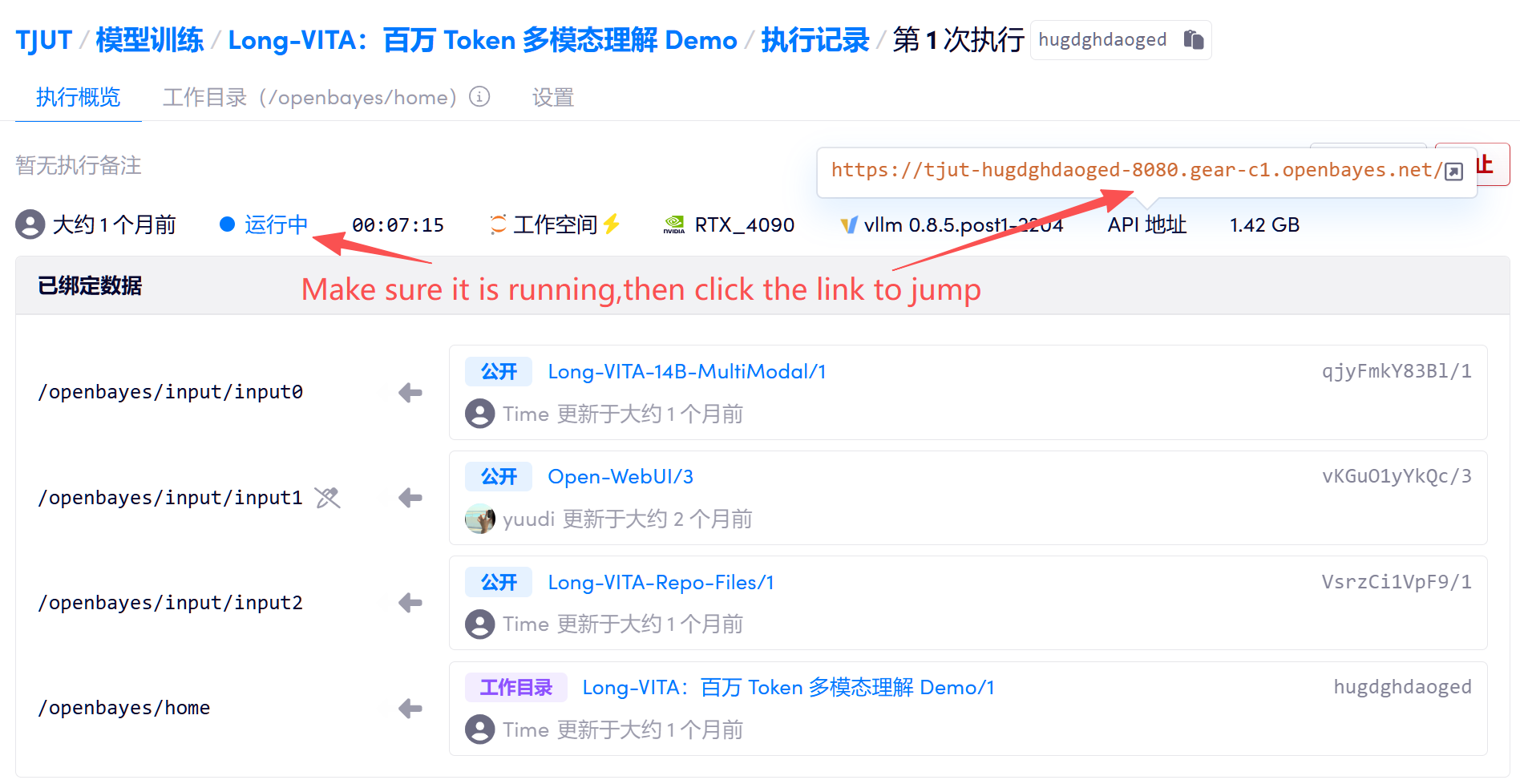
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface interactive Gradio
2. Une fois que vous entrez sur la page Web, vous pouvez utiliser le modèle
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
Précautions
- Pour les longs textes d'entrée, assurez-vous de disposer d'une mémoire vidéo suffisante ; il est recommandé de charger les textes très volumineux par lots.
- Il est recommandé que l'image d'entrée ait une longueur de côté ≤ 2048 pixels pour réduire la latence d'inférence.
- Si l'inférence échoue, veuillez vérifier le format d'entrée ou raccourcir la longueur de l'entrée et réessayer.
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{shen2025longvitascalinglargemultimodal,
title={Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy},
author={Yunhang Shen and Chaoyou Fu and Shaoqi Dong and Xiong Wang and Yi-Fan Zhang and Peixian Chen and Mengdan Zhang and Haoyu Cao and Ke Li and Xiawu Zheng and Yan Zhang and Yiyi Zhou and Ran He and Caifeng Shan and Rongrong Ji and Xing Sun},
year={2025},
eprint={2502.05177},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.05177},
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.