Command Palette
Search for a command to run...
IndexTTS-2 : Surmonter Les Obstacles Liés À La Durée Et Au Contrôle Des Émotions Des TTS Autorégressifs
Date
Balises
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

IndexTTS-2 est un modèle de synthèse vocale (TTS) novateur, mis à disposition en open source par l'équipe Bilibili Voice en juin 2025. Ce modèle représente une avancée majeure dans l'expression des émotions et le contrôle de la durée, et constitue le premier modèle TTS autorégressif à offrir un contrôle précis de la durée. Il prend en charge le clonage vocal à partir d'un seul échantillon, reproduisant fidèlement le timbre, le rythme et le style d'élocution à partir d'un fichier audio unique, et est compatible avec de nombreuses langues. IndexTTS-2 implémente un contrôle de séparation émotion-timbre, permettant aux utilisateurs de spécifier indépendamment les sources du timbre et de l'émotion. Le modèle offre des capacités de saisie multimodale des émotions, prenant en charge le contrôle des émotions via un enregistrement audio de référence, une description textuelle ou des vecteurs émotionnels. Des articles de recherche associés sont disponibles. IndexTTS2 : une avancée majeure dans la synthèse vocale auto-régressive à durée contrôlée et expressive des émotions .
Ce tutoriel utilise une seule carte graphique RTX 5090 comme ressource de calcul.
2. Affichage des effets
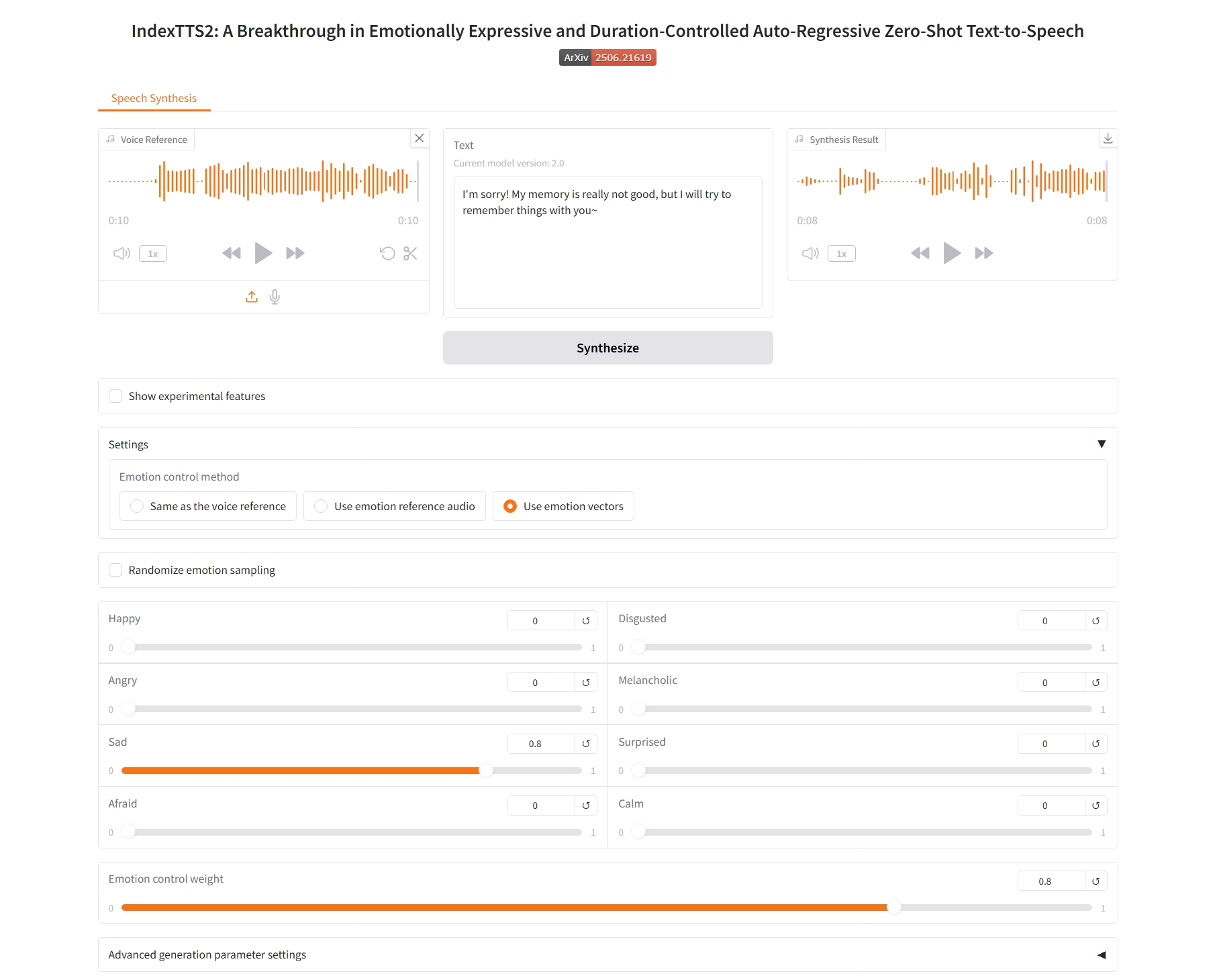
Identique à la référence vocale
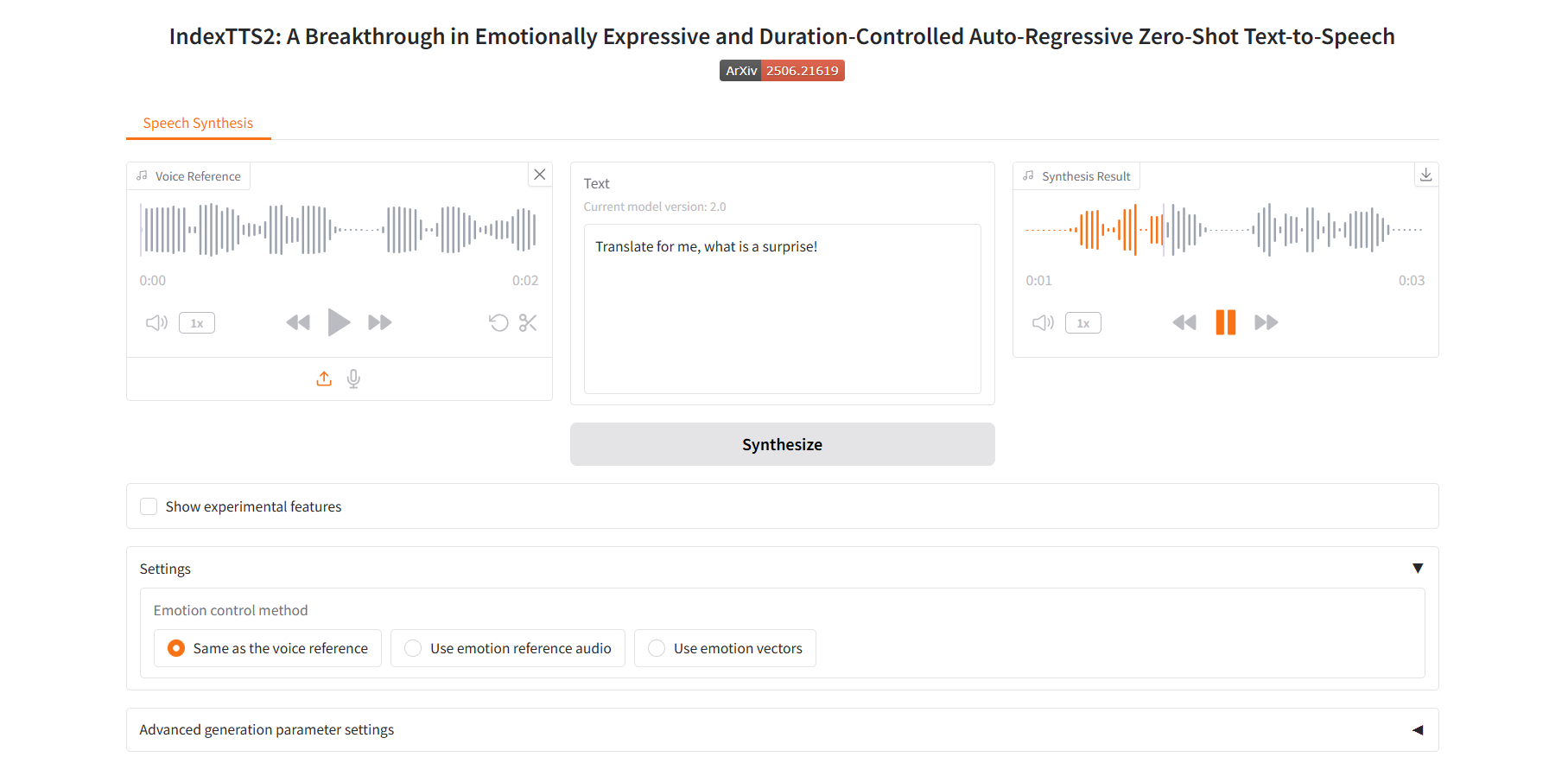
Utiliser un audio de référence émotionnelle
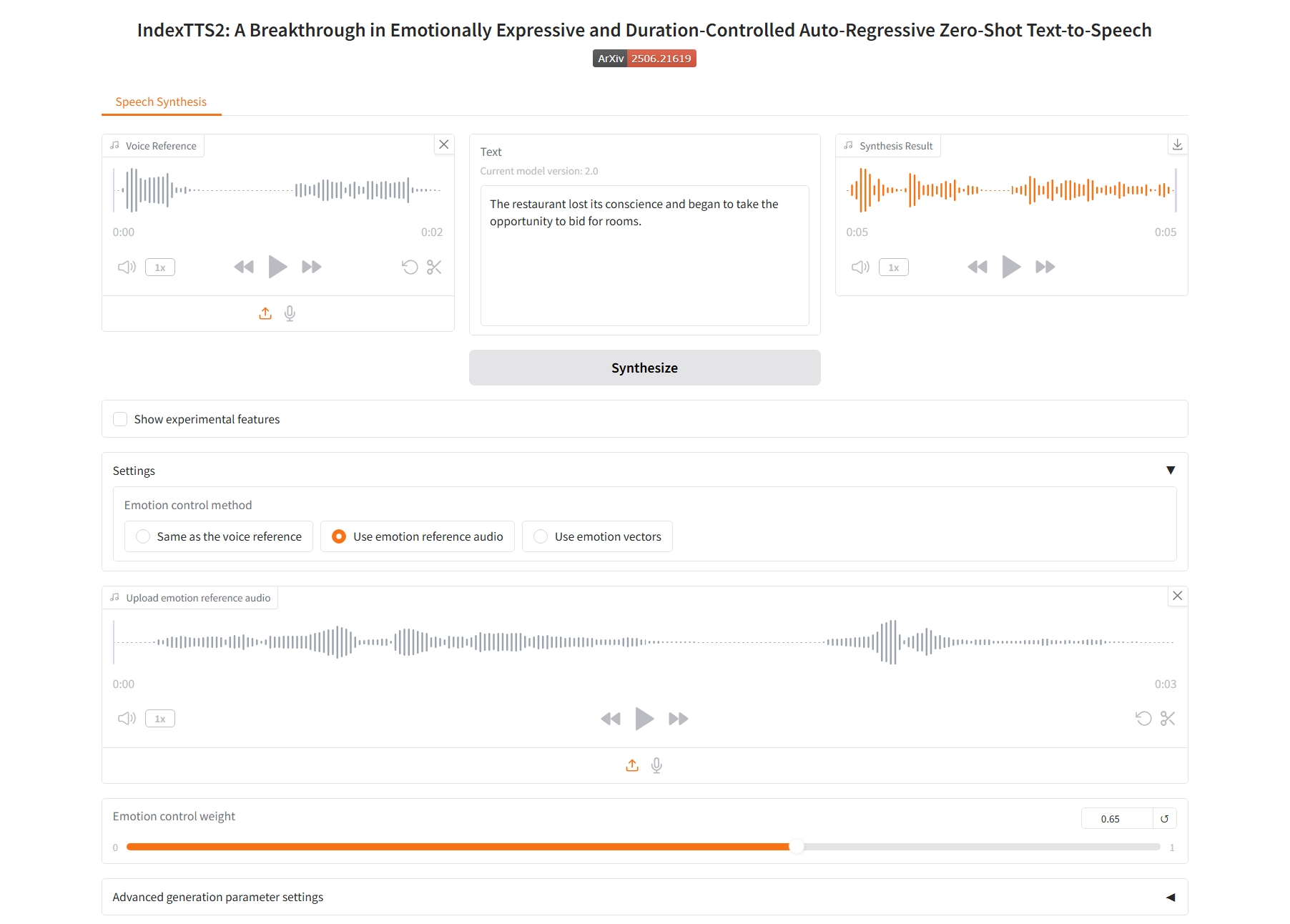
Utiliser des vecteurs d'émotion
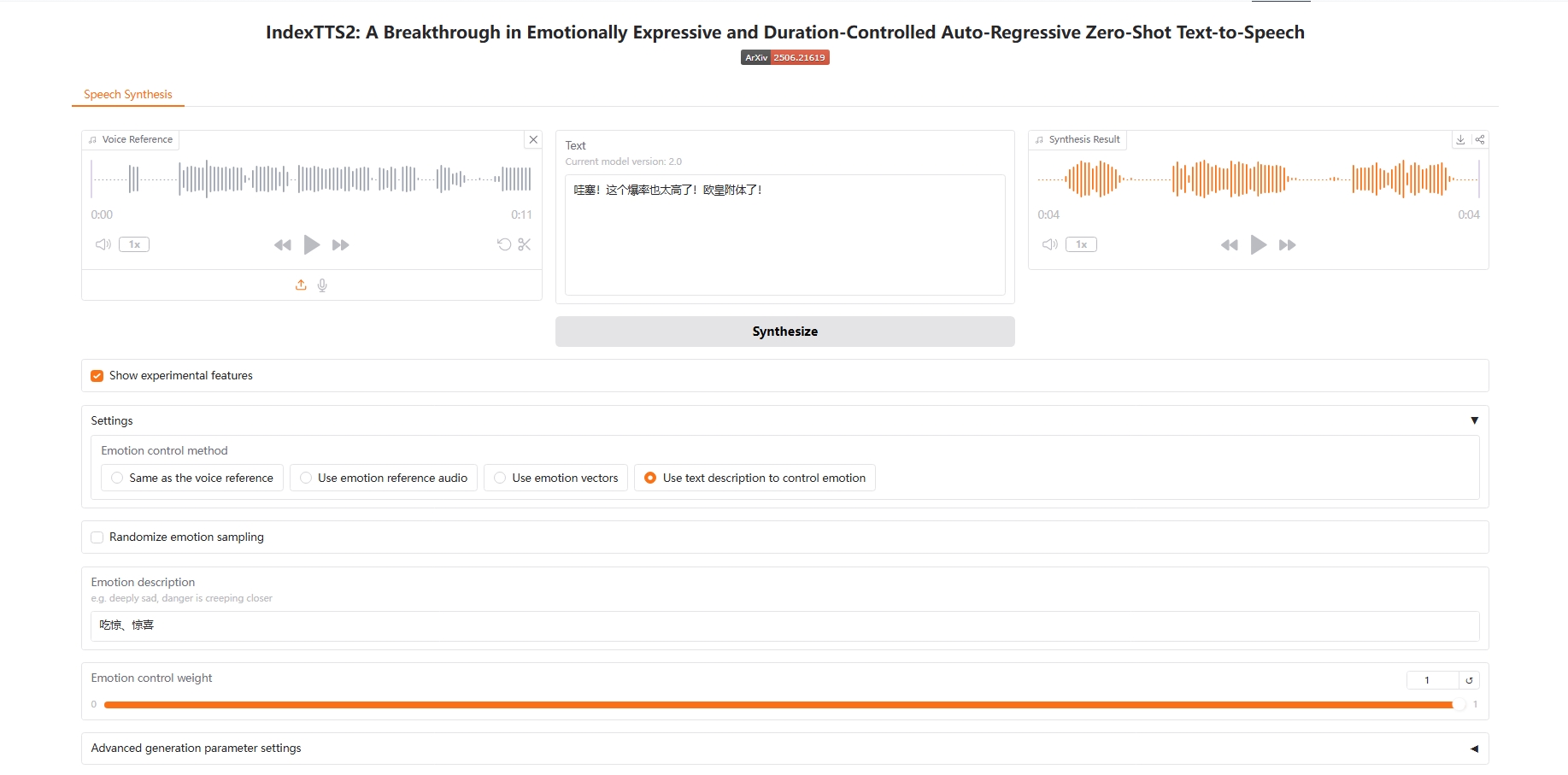
Utilisez la description textuelle pour contrôler les émotions
3. Étapes de l'opération
1. Démarrez le conteneur
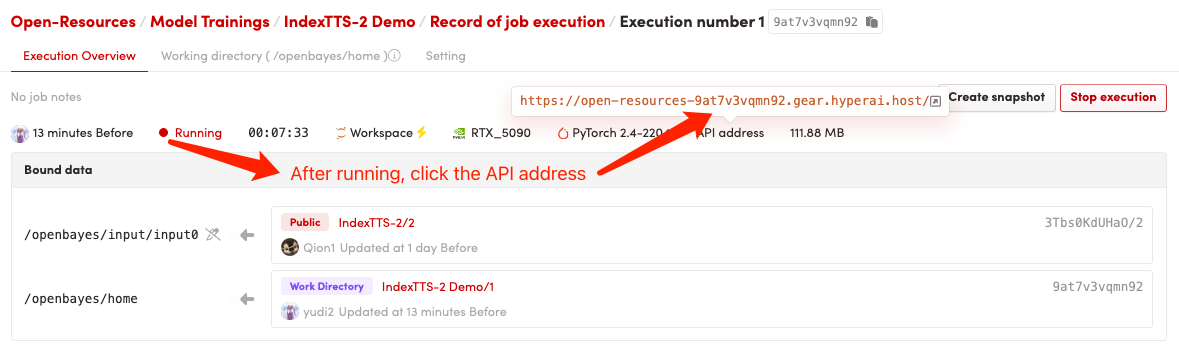
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
1. Identique à la référence vocale

Paramètres spécifiques :
- Paramètres avancés :
- do_sample : s'il faut effectuer un échantillonnage.
- Température : contrôle la régularité de la distribution de probabilité pendant l'échantillonnage.
- top_p : échantillonnage du noyau.
- top_k : À chaque étape de génération, seuls les K jetons avec la probabilité la plus élevée sont pris en compte.
- num_beams : largeur de recherche de faisceau.
- repetition_penalty : Pénalité de répétition, qui réduit la probabilité que le modèle génère le même jeton à plusieurs reprises.
- length_penalty : pénalité de longueur, qui incite ou décourage le modèle à générer des séquences plus ou moins longues. Ceci est particulièrement efficace lorsque num_beams > 1 est utilisé.
- max_mel_tokens : Le nombre maximal de jetons générés.
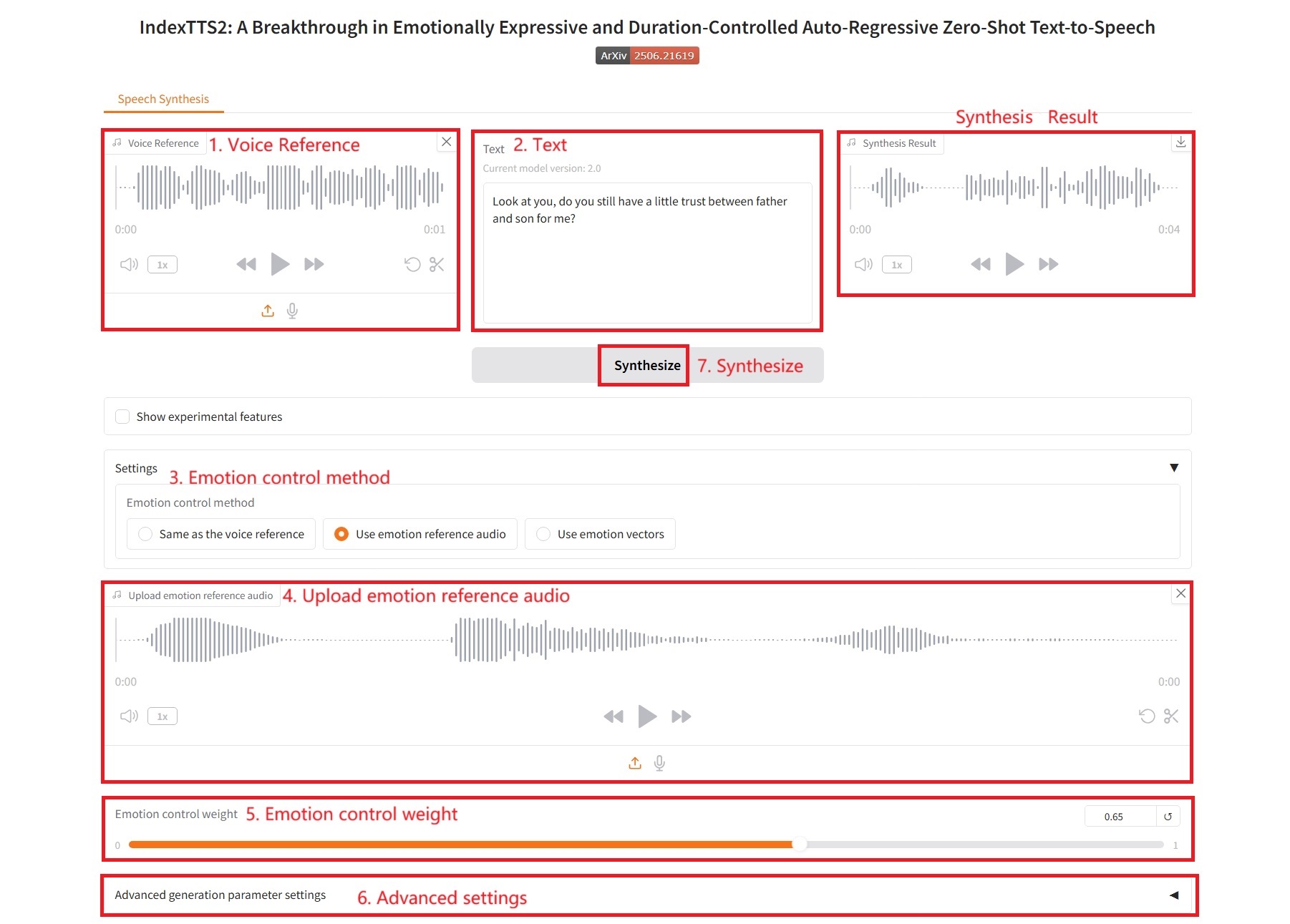
2. Utilisez des références audio émotionnelles
3. Utiliser des vecteurs d'émotion
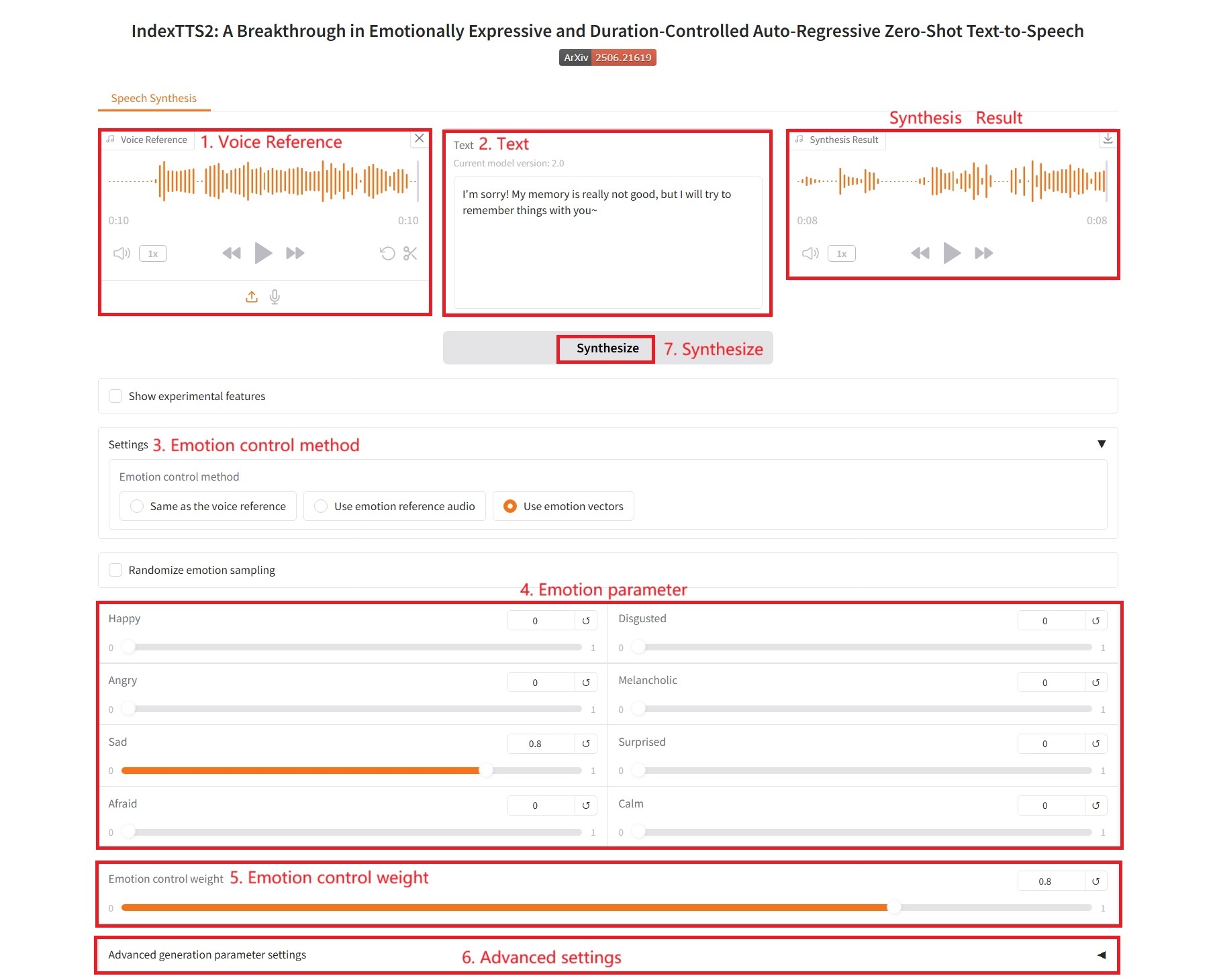
Paramètres de contrôle émotionnel :
- Heureux, Dégoûté, En colère, Mélancolique, Triste, Surpris, Effrayé, Calme : ces valeurs correspondent à huit dimensions émotionnelles fondamentales. La valeur de chaque curseur (généralement comprise entre 0,0 et 1,0) indique l'intensité de l'émotion que vous souhaitez refléter dans le discours final.
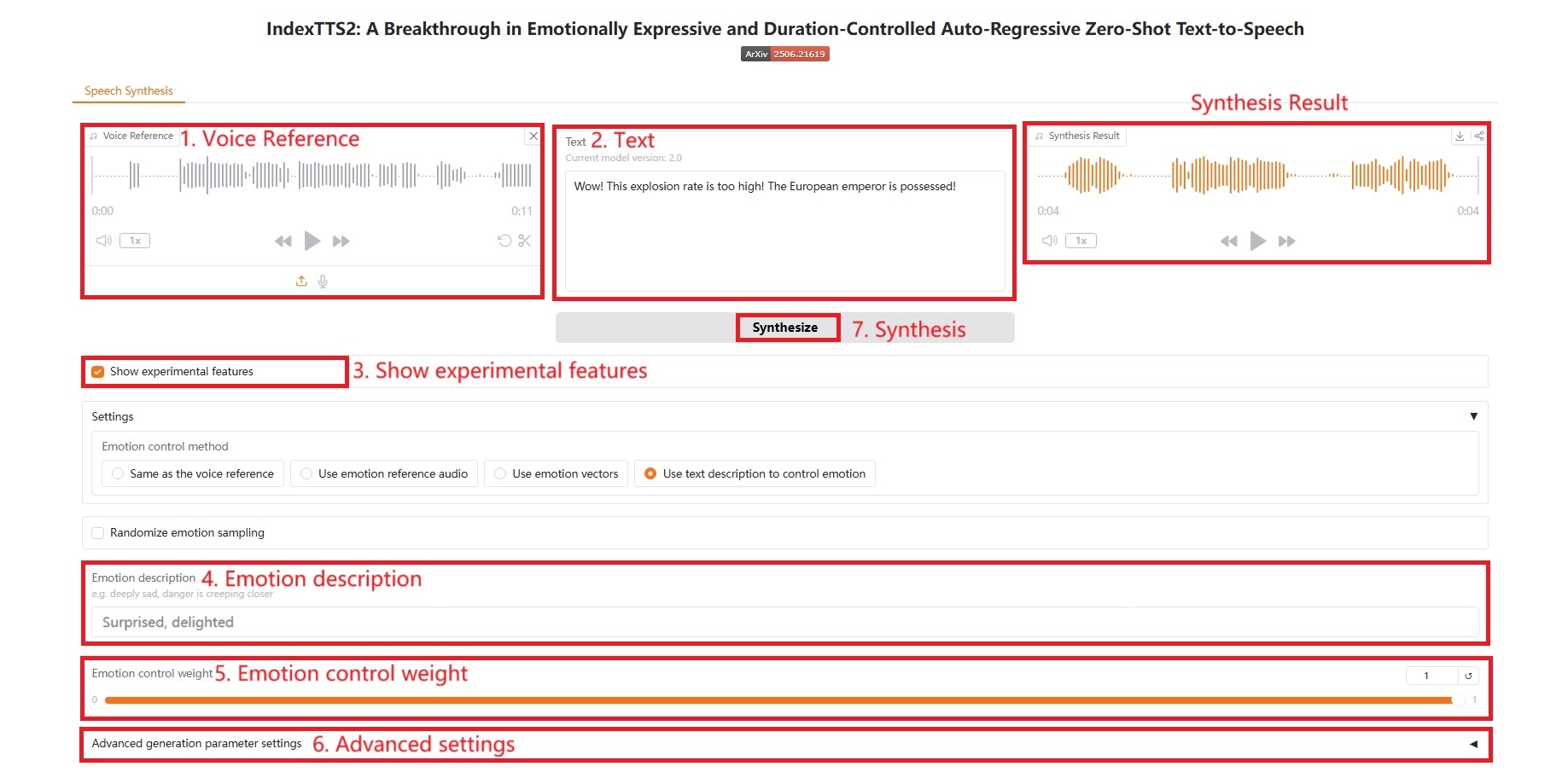
4. Utilisez la description textuelle pour contrôler les émotions
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{zhou2025indextts2,
title={IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv preprint arXiv:2506.21619},
year={2025}
}
@article{deng2025indextts,
title={IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv preprint arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}Vue d’ensemble de Notebook
Niveau
Rubrique
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.