Command Palette
Search for a command to run...
Déploiement En Un Clic De VideoLLaMA3-7B
Date
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel


Ce tutoriel utilise une seule ressource de calcul RTX 4090, déploie le modèle VideoLLaMA3-7B-Image et fournit deux exemples de compréhension vidéo et d'image. Il propose également quatre tutoriels de scripts de notebook pour la compréhension d'une image unique, la compréhension d'images multiples, l'expression et le positionnement des références visuelles et la compréhension vidéo.
VideoLLaMA3 est un modèle multimodal fondamental, open source, développé par l'équipe de traitement automatique du langage naturel de l'Académie DAMO d'Alibaba (DAMO-NLP-SG) en février 2025. Il est dédié à la compréhension d'images et de vidéos. Grâce à une architecture centrée sur la vision et à une ingénierie des données de haute qualité, il améliore considérablement la précision et l'efficacité de la compréhension vidéo. Sa version allégée (2B) répond aux besoins de déploiement en périphérie, tandis que le modèle 7B offre des performances optimales pour les applications de recherche. Ce dernier atteint des performances de pointe dans trois tâches majeures : la compréhension vidéo générale, le raisonnement temporel et l'analyse de vidéos longues. Des articles de recherche associés sont disponibles. VideoLLaMA 3 : Modèles multimodaux de base pour la compréhension des images et des vidéos .
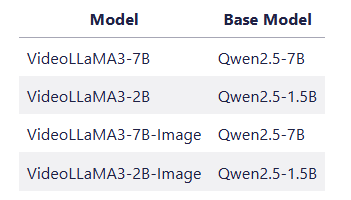
👉 Le projet propose 4 modèles de modèles :
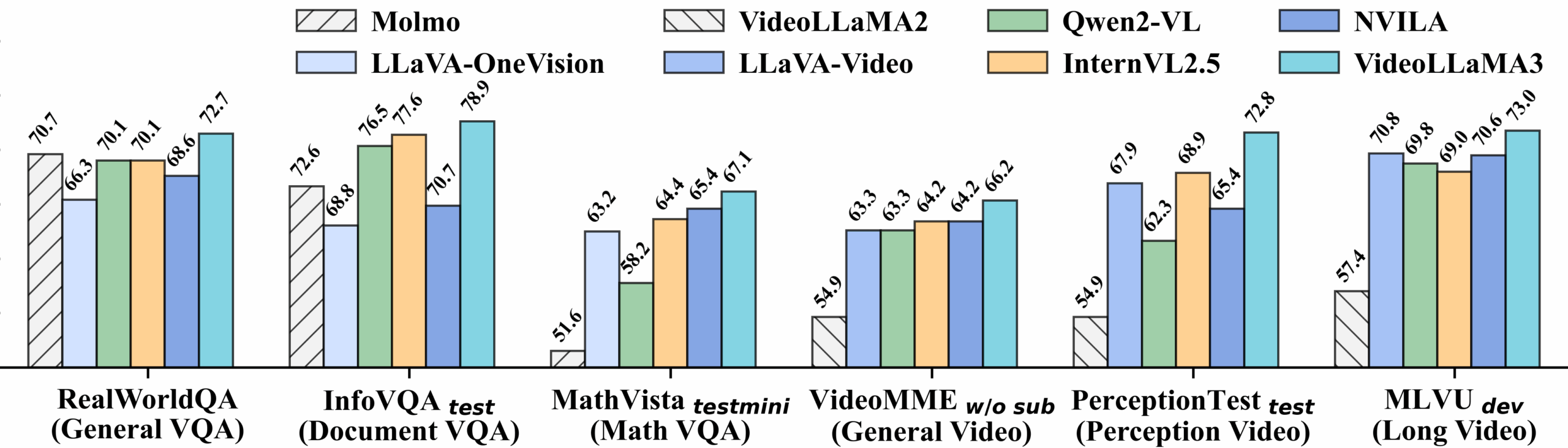
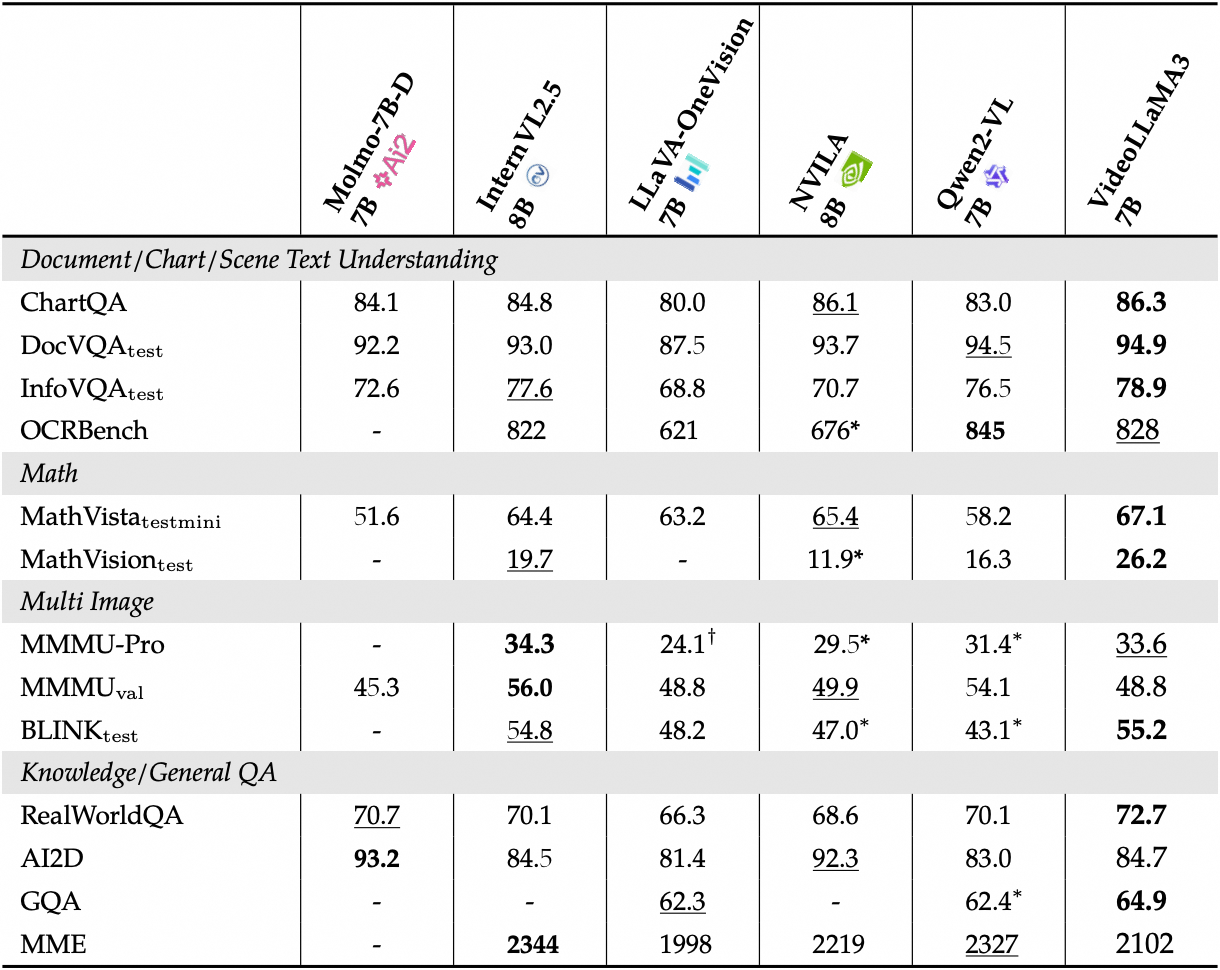
Performances détaillées du benchmark vidéo :
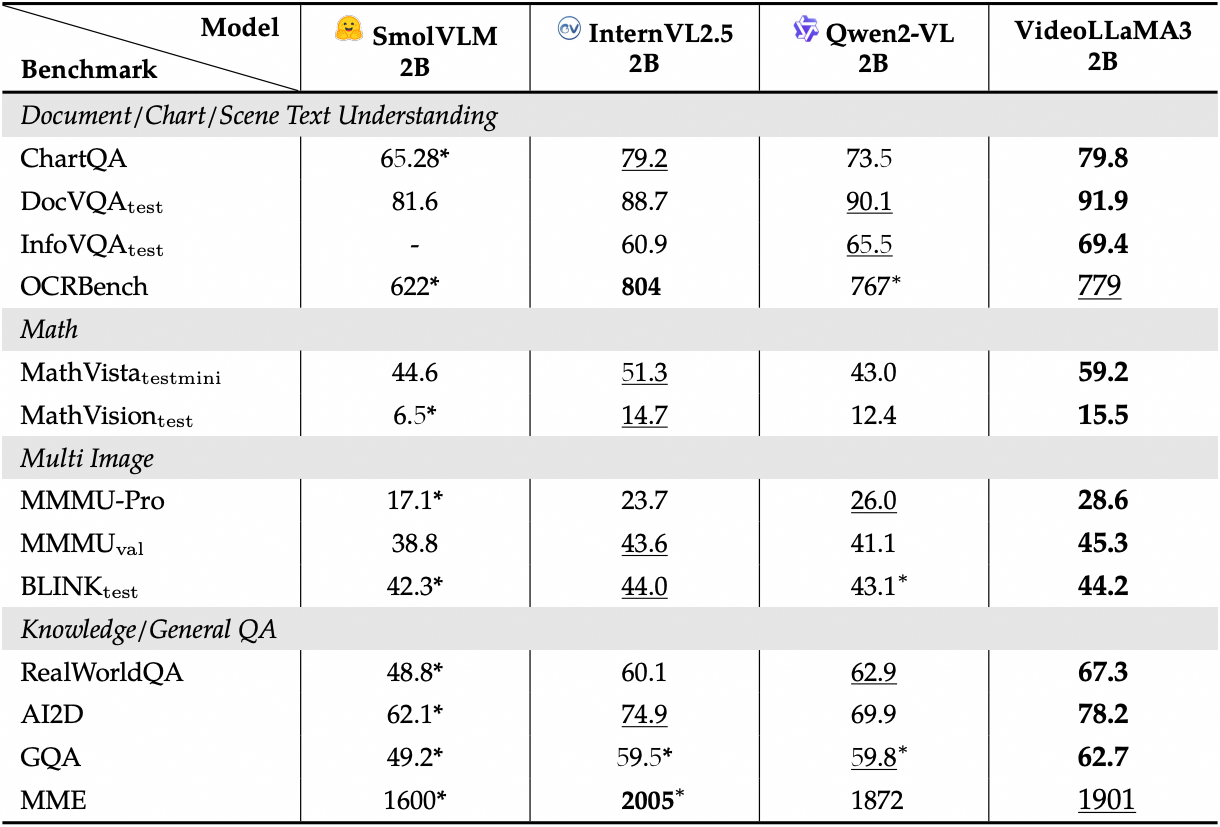
Afficher les performances détaillées des benchmarks d'images :
2. Étapes de l'opération
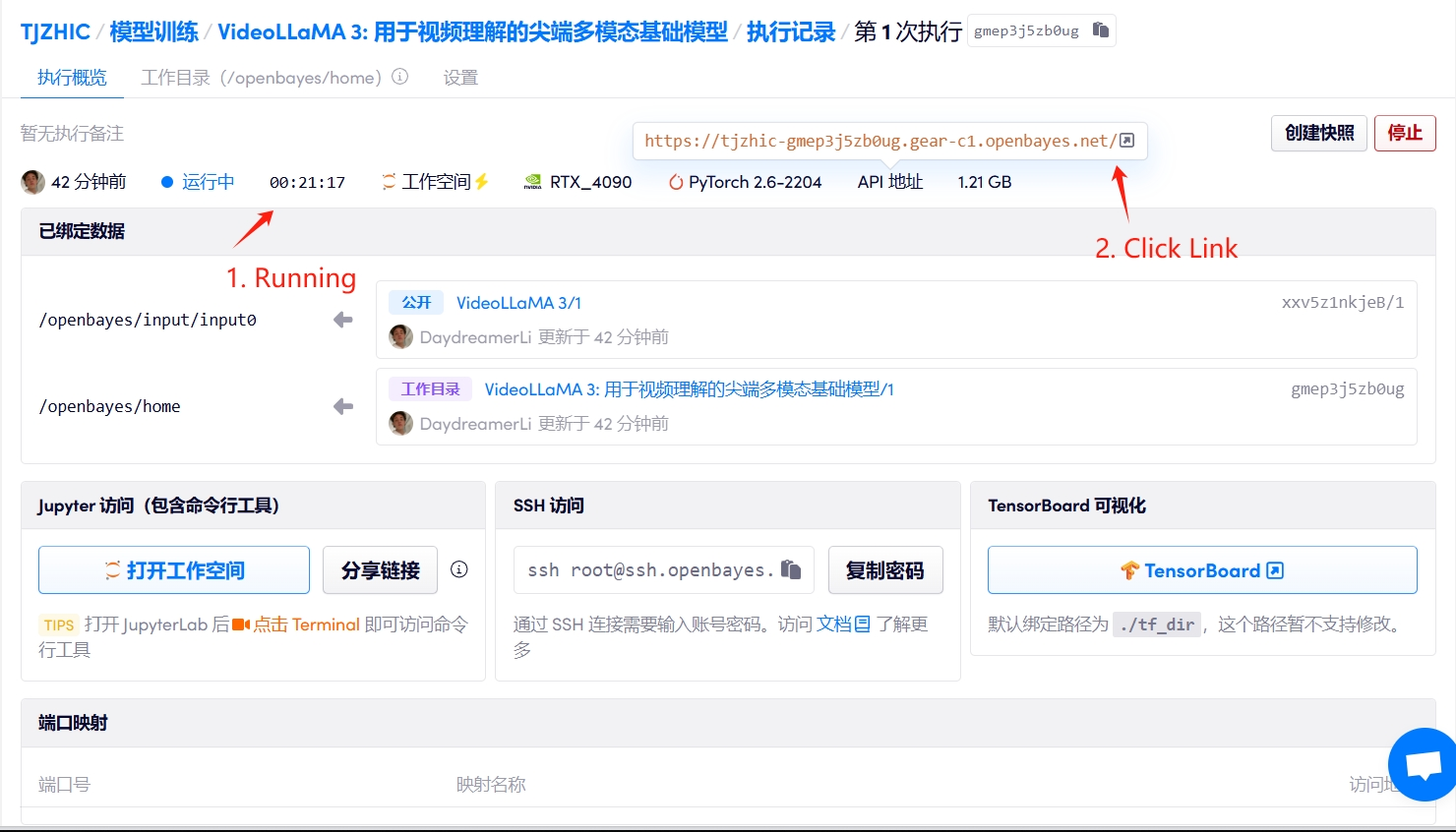
1. Démarrez le conteneur
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
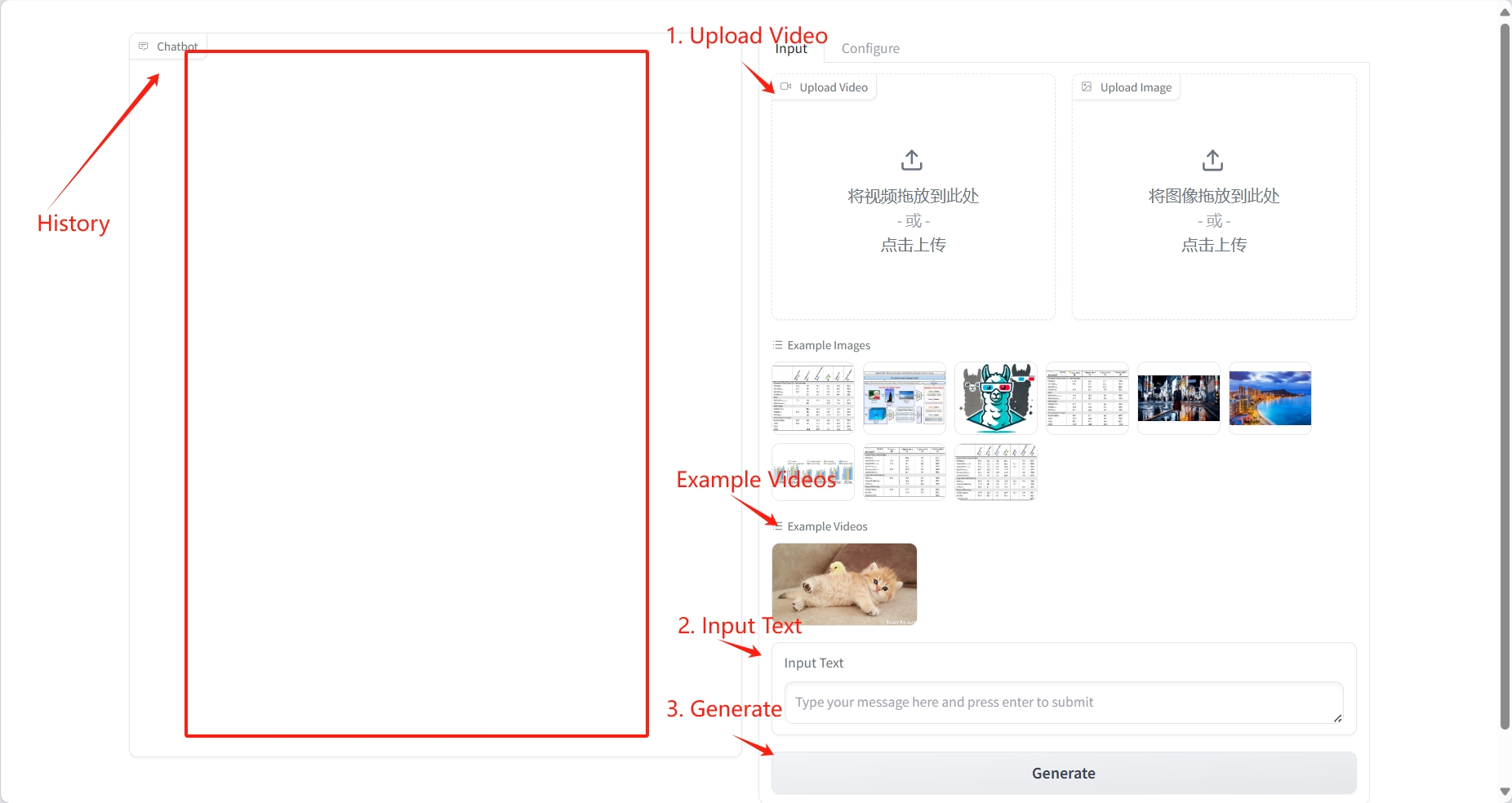
2. Étapes d'utilisation
Compréhension de la vidéo
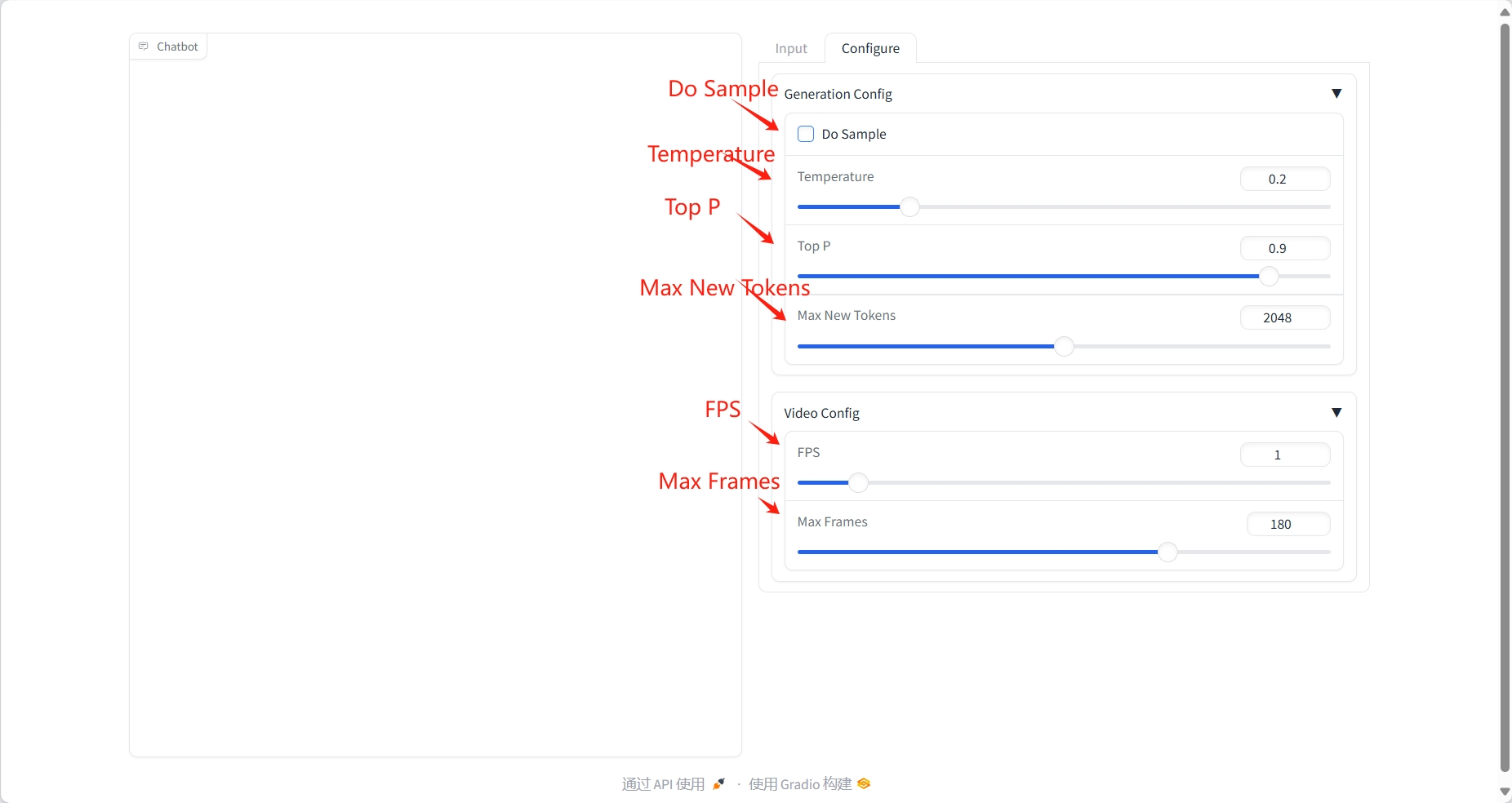
résultat
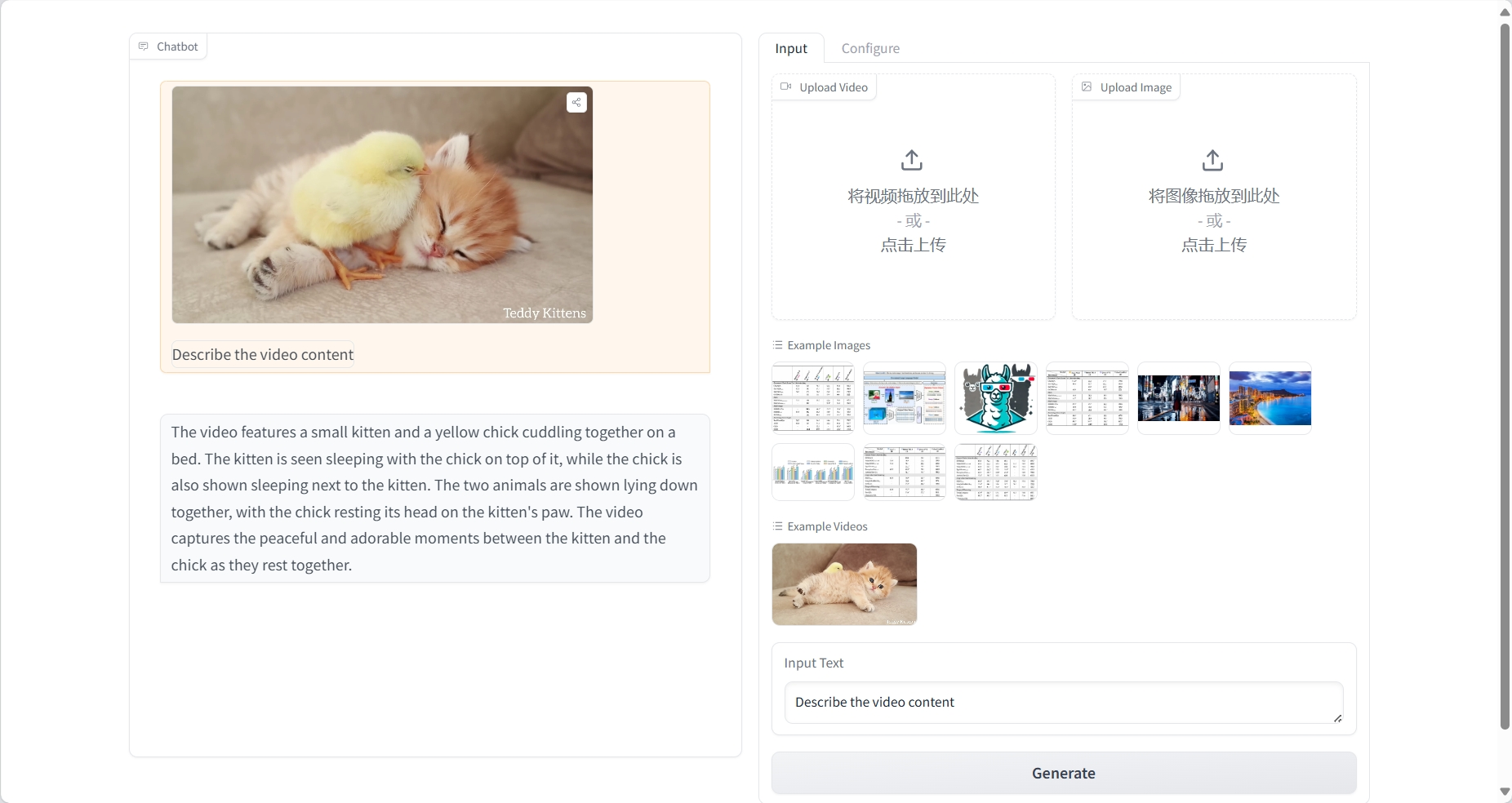
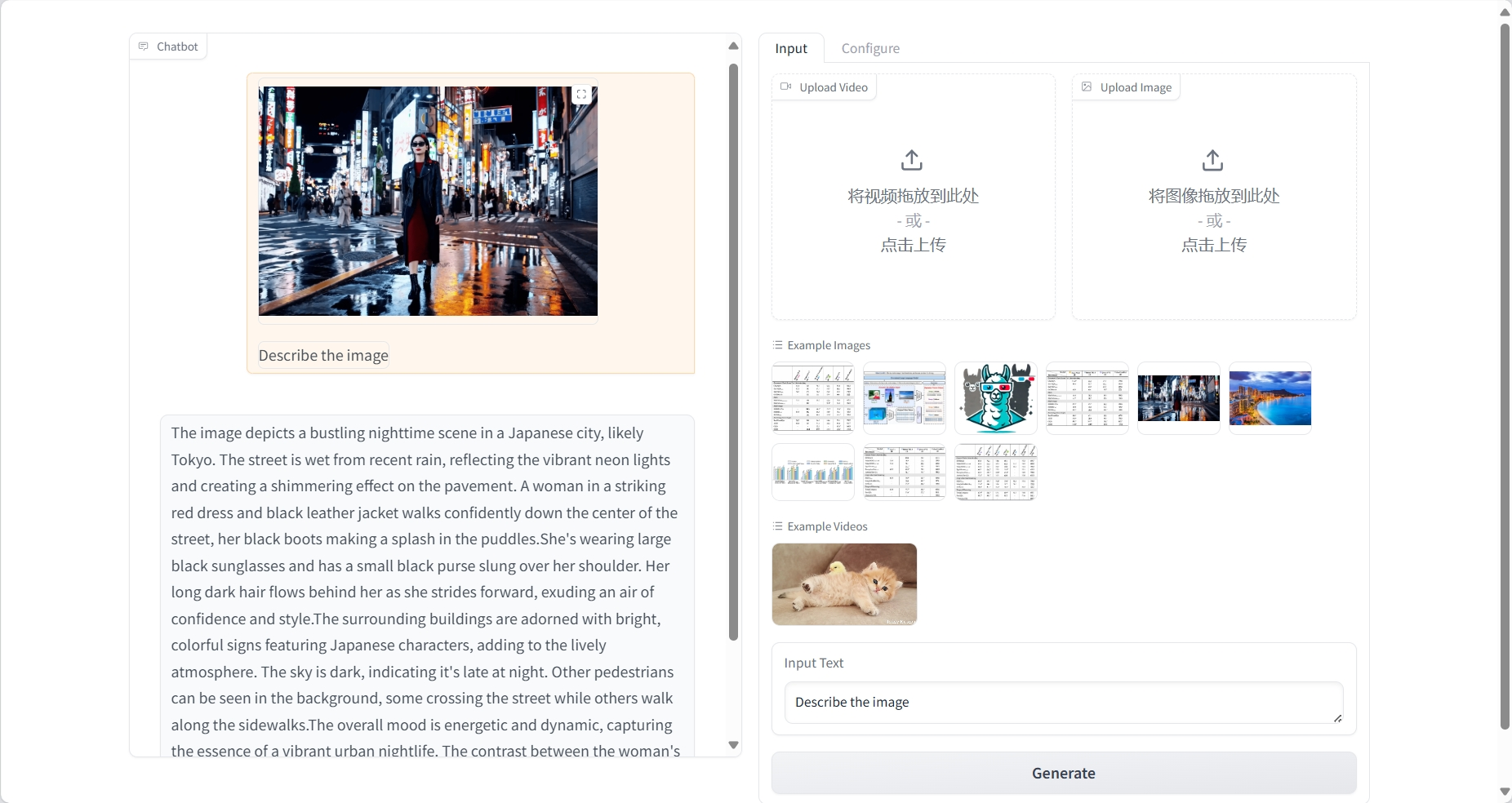
Compréhension de l'image
résultat
3. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{damonlpsg2025videollama3,
title={VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding},
author={Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao},
journal={arXiv preprint arXiv:2501.13106},
year={2025},
url = {https://arxiv.org/abs/2501.13106}
}
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.