Command Palette
Search for a command to run...
Compilation De Jeux De Données | Jeux De Données d'inférence Open Source Provenant De NVIDIA, OpenAI Et De Plusieurs Institutions De Recherche, Couvrant Les Mathématiques, l'espace Panoramique, La Réponse Aux Questions Wiki, Les Tâches De Recherche, Le Bon Sens Visuel, etc.

À mesure que les grands modèles évoluent, passant de la simple « capacité à parler et à écrire » à la « capacité à raisonner et à penser », l'importance des données est redéfinie.
Auparavant, de vastes corpus généralistes permettaient d'exploiter pleinement le potentiel expressif des modèles de langage ; aujourd'hui, le véritable obstacle limitant les performances de ces modèles réside progressivement dans l'utilisation de données de raisonnement dotées d'une structure claire, d'une logique rigoureuse et de processus de déduction complexes. Qu'il s'agisse de problèmes mathématiques complexes, de réponses à des questions interdisciplinaires ou de capacités de prise de décision et d'utilisation d'outils en plusieurs étapes, tous ces domaines reposent sur des ensembles de données de raisonnement de haute qualité.
Les jeux de données d'inférence peuvent se concentrer sur les mathématiques et la logique, ou construire des chaînes de raisonnement complexes par synthèse. Ils peuvent également servir à l'évaluation des aptitudes multitâches, ou encore à l'établissement de référentiels scientifiques et à l'optimisation des systèmes de questions-réponses. Cependant, ces ressources de données présentent une fragmentation importante, existant souvent dans différents formats, ce qui rend leur utilisation uniforme difficile. De ce fait, de nombreux développeurs et chercheurs consacrent un temps considérable à la simple recherche de données.
donc,HyperAI a compilé une collection d'ensembles de données d'inférence de haute qualité, couvrant l'inférence multi-domaines et multi-tâches, les données d'entraînement à l'inférence synthétique, les bancs d'essai de recherche scientifique et les données de questions-réponses à grande échelle.Il permet également de télécharger ou d'utiliser des ensembles de données en ligne, ce qui réduit les obstacles à l'utilisation des ensembles de données d'inférence.
Des ensembles de données de meilleure qualité :
Ensemble de données du problème d'inférence Open-RL
* Utilisation en ligne :
Open-RL est un ensemble de données de problèmes de raisonnement multi-domaines publié par Turing en 2026, contenant des problèmes de raisonnement STEM indépendants, vérifiables et explicites en physique, mathématiques, biologie et chimie.
Chaque problème requiert un raisonnement en plusieurs étapes, implique des opérations symboliques et/ou des calculs numériques, et possède une réponse finale objectivement vérifiable. Cet ensemble de données convient à l'ajustement fin de l'apprentissage par renforcement, à la modélisation des récompenses, à l'entraînement supervisé par les résultats et à l'évaluation comparative du raisonnement vérifiable.
Ensemble de données synthétiques d'inférence générale CHIMERA
* Utilisation en ligne :
CHIMERA est un ensemble de données de raisonnement synthétique conçu spécifiquement pour l'entraînement au raisonnement, couvrant un large éventail de sujets STEM et fournissant de longues trajectoires de chaîne de pensée (CoT).
Cet ensemble de données contient 9 225 questions réparties en 8 disciplines (mathématiques, informatique, chimie, physique, littérature, histoire, biologie et phonétique). Tous les exemples sont générés par un modèle de langage étendu (LLM) et validés automatiquement, sans annotation manuelle.
Répartition des sujets :
* Mathématiques : 4 452
*Informatique : 1 303
*Chimie : 1 102
*Physique : 742
*Littérature : 504
*Histoire : 422
*Biologie : 383
*Linguistique : 317
Ensemble de données d'inférence mathématique Nemotron-Math-v2
* Utilisation en ligne :
Nemotron-Math-v2 est un ensemble de données de raisonnement mathématique publié par NVIDIA Corporation. Il est principalement utilisé pour entraîner des modèles de langage (LLM) à effectuer un raisonnement mathématique structuré, étudier les différences entre le raisonnement assisté par outils et le raisonnement en langage naturel, et construire des systèmes de raisonnement à contexte long ou multivoies.
Cet ensemble de données contient environ 347 000 problèmes mathématiques de haute qualité et 7 millions de trajectoires d'inférence générées par des modèles. Chaque problème est résolu selon six configurations : profondeur d'inférence élevée, moyenne et faible, avec ou sans Python TIR. Les réponses sont validées par un pipeline utilisant un LLM comme arbitre.
Ensemble de données de référence de raisonnement spatial panoramique OmniSpatial
* Utilisation en ligne :
OmniSpatial est un jeu de données de référence pour le raisonnement spatial panoramique, publié en 2025 par l'Université Tsinghua en collaboration avec l'Institut d'études avancées en technologie spatiale de Shanghai, le Laboratoire d'intelligence artificielle de Shanghai et d'autres institutions. L'article associé, intitulé « OmniSpatial : Vers un banc d'essai complet pour le raisonnement spatial dans les modèles de langage visuel », vise à combler le manque d'évaluations concernant la compréhension spatiale de ces modèles.
Cet ensemble de données contient environ 1 533 exemples de questions-réponses à partir d'images, couvrant quatre grandes catégories de tâches de raisonnement spatial : raisonnement dynamique, logique spatiale complexe, interaction spatiale et prise de perspective, pour un total de 50 sous-tâches. Les sources de données sont diverses : images internet, tests psychologiques et questions d'examen de conduite. Les annotations ont fait l'objet de plusieurs phases de vérification afin d'en garantir la qualité et la diversité. Contrairement aux outils de référence traditionnels, OmniSpatial s'affranchit de la construction à partir de modèles préétablis, se rapprochant ainsi davantage des scénarios complexes du monde réel. Il teste non seulement les relations spatiales de base (comme avant/arrière, gauche/droite et distance), mais met également l'accent sur les interactions entre plusieurs objets, les changements de scène et le raisonnement multi-perspectives.
Cet ensemble de données est adapté à l'entraînement et à l'évaluation des capacités de raisonnement spatial de grands modèles multimodaux, notamment dans des applications telles que la navigation intelligente, la réalité augmentée/virtuelle et la compréhension de scènes complexes. Il s'agit d'un ensemble de données de référence standardisé, complet et exigeant.
Ensemble de données d'évaluation des tâches de recherche inférentielle de FrontierScience
* Utilisation en ligne :
FrontierScience est un ensemble de données destiné à évaluer les tâches de raisonnement et de recherche scientifique, publié par OpenAI en 2025. Il vise à évaluer systématiquement les capacités des grands modèles dans les sous-tâches de raisonnement scientifique et de recherche scientifique de niveau expert.
Cet ensemble de données utilise un mécanisme de conception de « création d'experts + structure de tâches à deux niveaux + mécanisme de notation automatique » et est divisé en deux sous-ensembles, correspondant à deux types de capacités : raisonnement précis fermé et raisonnement de recherche scientifique ouvert.
Ensemble de données des Olympiades
Conçues à l'origine par des médaillés et des entraîneurs d'équipes nationales des Olympiades internationales de physique, de chimie et de biologie, les questions présentent un niveau de difficulté comparable à celui des compétitions internationales de haut niveau telles que l'IPhO, l'IChO et l'IBO ; axées sur des tâches de raisonnement à réponse courte, le modèle doit produire une seule valeur numérique, une expression algébrique ou un terme biologique pouvant être associé de manière approximative, afin de garantir la vérifiabilité des résultats et la stabilité de l'évaluation automatique.
Ensemble de données de recherche
Rédigées par des doctorants, des postdoctorants et des professeurs, les questions simulent des sous-problèmes susceptibles d'être rencontrés dans la recherche scientifique réelle, couvrant les trois grands domaines que sont la physique, la chimie et la biologie. Chaque question est accompagnée d'un système de notation précis sur 10 points permettant d'évaluer la performance du modèle sur plusieurs aspects clés, au-delà de la simple exactitude de la réponse : la complétude des hypothèses de modélisation, le raisonnement et les conclusions intermédiaires.
Ensemble de données de réponses aux questions HotpotQA
* Utilisation en ligne :
Le jeu de données HotpotQA est un vaste ensemble de questions-réponses issues de Wikipédia en anglais, contenant 113 000 questions posées par les contributeurs. Pour répondre à ces questions, il faut se référer aux paragraphes introductifs de deux articles Wikipédia.
Chaque question comprend deux paragraphes principaux et une liste de phrases extraites de ces paragraphes, fournissant des éléments factuels jugés nécessaires pour y répondre. Cet ensemble de données présente les caractéristiques suivantes :
Répondre à cette question nécessite de rechercher et de raisonner à travers de multiples documents justificatifs ;
* Les problèmes sont divers et ne sont limités par aucune base de connaissances ou modèle de connaissances préexistant ;
Cet ensemble de données fournit les faits justificatifs au niveau de la phrase nécessaires au raisonnement, permettant aux systèmes de QA de raisonner et d'interpréter les prédictions sous une supervision forte ;
Cet ensemble de données présente un nouveau problème de comparaison de faits afin de tester la capacité d'un système de questions-réponses à extraire les faits pertinents et à effectuer les comparaisons nécessaires.
Ensemble de données de raisonnement de bon sens visuel VCR
* Utilisation en ligne :
VCR signifie Visual Commonsense Reasoning, qui est un ensemble de données à grande échelle pour le raisonnement visuel de bon sens. L'ensemble de données pose des questions difficiles sur les images, et la machine doit effectuer deux sous-tâches : répondre correctement à la question et fournir des raisons pour justifier sa réponse.
L'ensemble de données VCR contient un grand nombre de questions, dont 212 000 sont utilisées pour la formation, 26 000 pour la validation et 25 000 pour les tests. Les réponses et les raisons proviennent de plus de 110 000 scènes de films uniques.

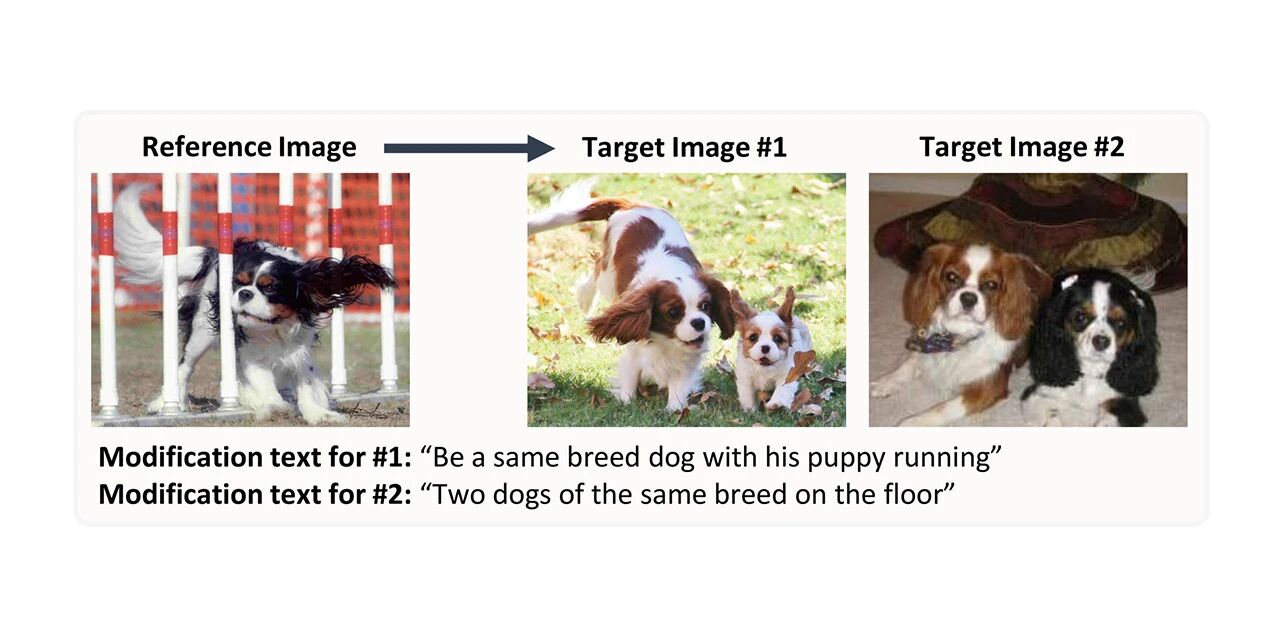
Ensemble de données CIRR pour la synthèse et la récupération d'images
* Utilisation en ligne :
CIRR signifie Compose Image Retrieval on Real-life images et contient plus de 36 000 paires d'images collaboratives, à domaine ouvert et de textes modifiés générés manuellement. Cet ensemble de données vise à faciliter les recherches futures sur le raisonnement subtil sur les concepts linguistiques visuels et la récupération itérative avec des dialogues, en comblant les lacunes des ensembles de données existants en mettant davantage l'accent sur la distinction d'images visuellement similaires en domaine ouvert.