Command Palette
Search for a command to run...
Il Reste 6 Jours Pour Soumettre Les Candidatures Au VLDB '25, Un Aperçu Des 58 Meilleures Conférences ; L'ensemble De Données De Segmentation Des Villes ISPRS Est En Ligne

💥La section « Top Conférences » est désormais disponible sur le site officiel de hyper.ai ! Cette section fournit les informations les plus récentes et les plus complètes sur les principales conférences informatiques de classe A du CCF, y compris l'introduction de la conférence, le compte à rebours des délais, les liens de soumission, etc.
Vous êtes déjà inscrit à une conférence de premier plan, mais vous ne savez pas exactement quand la date limite est fixée et vous soumettez toujours votre article à la hâte lorsque la date limite approche ? Ou bien n’avez-vous pas encore décidé à quelle conférence vous souhaitez assister et êtes-vous dans une situation d’attente ? Alors vous êtes au bon endroit en venant chez hyper.ai ! Faites défiler jusqu'à la fin de cet article.Les choix hebdomadaires de l'éditeur fournissent également des informations sur les dates limites des principales conférences du mois dernier.N'oubliez pas de faire attention~
Consultez immédiatement les principales informations de la conférence :https://hyper.ai/events
Du 20 au 26 mai, le site officiel de hyper.ai est mis à jour :
- Ensembles de données publiques de haute qualité : 10
- Sélection de tutoriels de haute qualité : 3
- Sélection d'articles communautaires : 5 articles
- Entrées d'encyclopédie populaires : 5
- Principales conférences avec date limite en juin : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de segmentation des villes ISPRS
L'ensemble de données contient des segmentations sémantiques 2D de zones urbaines telles que Vaihinge, Potsdam et Toronto, chacune classée manuellement dans les 6 classes de couverture terrestre les plus courantes.
Utilisation directe :https://go.hyper.ai/lSWQY
Cet ensemble de données contient 5 329 émoticônes et utilise le projet step-free-api pour compléter l'annotation visuelle via le modèle multimodal step-free-api, fournissant des ressources précieuses pour l'intelligence artificielle dans les domaines de la compréhension des émotions, de l'apprentissage multimodal et de l'interaction intelligente.
Utilisation directe :https://go.hyper.ai/5Yka5
3. Ensemble de données de classification des genres musicaux GTZAN
L'ensemble de données GTZAN contient 1 000 échantillons de musique de 10 genres différents, avec 100 échantillons dans chaque genre. Cet ensemble de données a été créé à l'origine par le Marsyas Music Information Retrieval Toolkit et est largement utilisé pour évaluer les performances des algorithmes de classification musicale.
Utilisation directe :https://go.hyper.ai/u5vWE
4. Ensemble de données sur les plats alimentaires ISIA Food-200
L'ensemble de données comprend 197 323 aliments, chacun comprenant le nom de l'aliment, l'image de l'aliment et les principaux ingrédients. 200 catégories de plats et 398 types d'ingrédients.
Utilisation directe :https://go.hyper.ai/yL8wN
5. Ensemble de données de recettes Yummly-66K
L'ensemble de données contient 66 615 éléments de recettes de Yummly. Chaque élément de recette comprend le nom de la recette, les lignes d'ingrédients prétraités, l'image de la recette, les informations sur les attributs du plat et du cours, etc. Il y a un total de 10 cuisines, 14 plats et 2 416 ingrédients dans l'ensemble de données.
Utilisation directe :https://go.hyper.ai/Me7ef
6. Ensemble de données de recettes Yummly-28K
L'ensemble de données a été extrait du site Web de partage de recettes Yummly. Il contient un total de 27 638 recettes. Chaque recette contient une image de recette, des ingrédients, une portion et des informations sur le plat.
Utilisation directe :https://go.hyper.ai/Cd38b
7. Ensemble de données de réponses aux questions de compréhension de vidéos longues CinePile
CinePile est un ensemble de données de questions-réponses conçu pour la compréhension de longues vidéos. L’équipe de recherche a utilisé un LLM avancé et une interaction homme-machine et s’est appuyée sur des données originales générées par l’homme. L'ensemble de données complet contient 305 000 questions à choix multiples (QCM) couvrant divers aspects visuels et multimodaux, notamment la compréhension temporelle, la compréhension des interactions homme-objet et le raisonnement sur des événements ou des actions au sein d'une scène.
Utilisation directe :https://go.hyper.ai/gqRqK
8. Ensemble de données de détection d'objets LEGO B200
Cet ensemble de données est un ensemble de données de détection d'objets de haute qualité et de haute densité contenant les 200 pièces LEGO les plus populaires, chacune avec 4 000 instances d'objets, qui peuvent être utilisées pour la détection de pièces LEGO à grande échelle.
Utilisation directe :https://go.hyper.ai/aWyz5
9. 50 œuvres d'art Ensemble de données d'œuvres d'art
Cet ensemble de données rassemble les œuvres d'art des 50 artistes les plus influents de tous les temps et contient des informations de base récupérées sur Wikipédia.
Utilisation directe :https://go.hyper.ai/gHpMh
10. Images d'art - Ensemble de données d'images d'art de 9 000
L'ensemble de données contient environ 9 000 images d'art de 5 types d'art. Les données sont divisées en un ensemble d’entraînement et un ensemble de test. Les types d'art comprennent : l'aquarelle, la peinture, la sculpture, l'art graphique, l'iconographie (art russe ancien).
Utilisation directe :https://go.hyper.ai/ALXc1
Pour plus d'ensembles de données publics, veuillez visiter:
Tutoriels publics sélectionnés
Le flux de travail ComfyUI InstantID peut transformer des photos de portrait ordinaires en œuvres d'art avec un style hautement personnalisé. Au cours du processus de transfert de style, l'algorithme combine le contenu d'une image avec le style d'une autre image pour générer une nouvelle image qui conserve le contenu de l'image d'origine et possède le style artistique de l'autre image. Cette technologie est largement utilisée dans des domaines tels que la création artistique, le traitement d’images et les effets visuels.
Exécutez en ligne :https://go.hyper.ai/HSPr7
2. POPE : Estimation de la pose d'un objet à 6 degrés de liberté
Ce tutoriel est une implémentation non officielle du document « POPE : estimation de pose à 6 degrés de liberté de n'importe quel objet, dans n'importe quelle scène, avec une référence ». Cette étude a proposé une méthode d'estimation de la pose d'objet appelée POPE, qui réalise une estimation de la pose d'objet 6DoF dans un environnement à échantillon nul. Il peut non seulement effectuer des tâches à double vue, mais peut également être utilisé pour l'estimation de pose 6DoF multi-vues et montre une robustesse inégalée dans les expériences.
Exécutez en ligne :https://go.hyper.ai/6RriI
3. Tutoriel de reconnaissance vocale : Reconnaître les nombres de 0 à 9 avec TensorFlow
Ce tutoriel utilise l'apprentissage en profondeur pour traduire des fichiers audio en données textuelles et détecter la prononciation des chiffres de 0 à 9. Par exemple, il traduit la prononciation du mot anglais « three » dans le texte « three ».
Exécutez en ligne :https://go.hyper.ai/9Teed
Articles de la communauté
Afin d'aider les chercheurs scientifiques à suivre les informations sur les principales conférences plus facilement et plus rapidement, le site Web officiel hyper.ai a lancé la section « Top Conference ». Cette section résume 58 réunions de catégorie A du CCF et fournit un compte à rebours DDL précis à la seconde près. Afin de garantir que chacun puisse obtenir les informations les plus récentes et les plus complètes sur la conférence en temps opportun, la section principale de la conférence du site Web officiel hyper.ai est toujours en cours de mise à jour !
Obtenez des informations détaillées :https://go.hyper.ai/5jfoy
awesome-ai4s est open source et a compilé plus de 100 articles académiques AI4S, couvrant la biomédecine, les soins de santé, la chimie des matériaux, les sciences animales et végétales, la recherche météorologique, l'énergie et l'environnement, les catastrophes naturelles et d'autres sous-domaines. Dans le même temps, les ensembles de données de haute qualité et les ressources d’outils utilisés dans les articles ont été lancés sur le site Web officiel.
Bienvenue à tous sur Star ou contribuez à des articles de haute qualité :
https://github.com/hyperai/awesome-ai4s
Du 31 mai au 1er juin, la cérémonie d'inauguration de l'Institut d'intelligence artificielle et de finance de Shanghai de l'Université normale de Chine de l'Est et la première conférence académique annuelle du SAIFS se tiendront à Shanghai. 18 universitaires et leaders de l'industrie de l'IA, de la finance et des domaines interdisciplinaires, dont le professeur du MIT Max Tegmark, partageront en profondeur des sujets tels que les grands modèles financiers et l'éthique de l'IA. Pour plus d’informations sur la conférence et les méthodes d’inscription, veuillez consulter cet article.
Obtenez plus d'informations sur la conférence :https://go.hyper.ai/zz1gg
La faculté de médecine de l’université de Stanford est réputée pour ses recherches innovantes dans le domaine biomédical. Après être entrée dans l’ère de l’IA, elle a également réalisé de nombreuses innovations révolutionnaires sous la direction de Lloyd Minor. Parallèlement, elle a également travaillé en étroite collaboration avec des géants de la technologie tels que Google, Apple et NVIDIA pour tirer davantage parti des avantages de toutes les parties et explorer les mystères des sciences de la vie. Cet article retrace l’histoire du développement et les réalisations importantes de cette institution centenaire.
Voir le rapport complet :https://go.hyper.ai/hQS3H
Des chercheurs du Centre national de mathématiques appliquées de Shanghai ont développé un système d'apprentissage profond capable de prédire les informations sur le microenvironnement tumoral à partir d'images histopathologiques pour les patients atteints de cancer sans données de transcriptome spatial, permettant ainsi d'obtenir un pronostic précis du cancer. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/ezwtu
Articles populaires de l'encyclopédie
1. Taux de rappel
2. Champ de rayonnement neuronal (NeRF)
3. Loi d'échelle
4. Opérations sur les grands modèles de langage (LLMOps)
5. Réseaux de Kolmogorov-Arnold
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Aperçu de la diffusion en direct de la station B
Apple organisera la WWDC 2024 du 10 au 14 juin. Pour vous aider à en savoir plus sur Apple,La salle de diffusion en direct de la station Super Neuro B continuera de diffuser la vidéo « Apple Special ».Comprend : les conférences WWDC passées, les entretiens avec les dirigeants, les documentaires connexes et d'autres contenus riches.
Le tableau suivant est un aperçu du contenu sélectionné par l'éditeur↓↓↓
| date | temps | contenu |
| 27 mai Lundi | 18:00 | Steve Jobs |
| Mardi 28 mai | 18:00 | Collection d'entretiens d'embauche 1990 |
| Mercredi 29 mai | 18:00 | Entretien avec Steve Jobs contre Bill Gates |
| Jeudi 30 mai | 18:00 | Première sortie de l'iPhone |
| Vendredi 31 mai | 18:00 | Histoire de Steve Jobs |
| Samedi 1er juin | 18:00 | Comment Apple a survécu à la quasi-faillite |
| Dimanche 2 juin | 18:00 | L'histoire de Tim Cook |
Super Neuro TV diffuse en direct 24h/24 et 7j/7. Cliquez pour obtenir les « cornichons électroniques » dans le domaine de l'IA :
http://live.bilibili.com/26483094
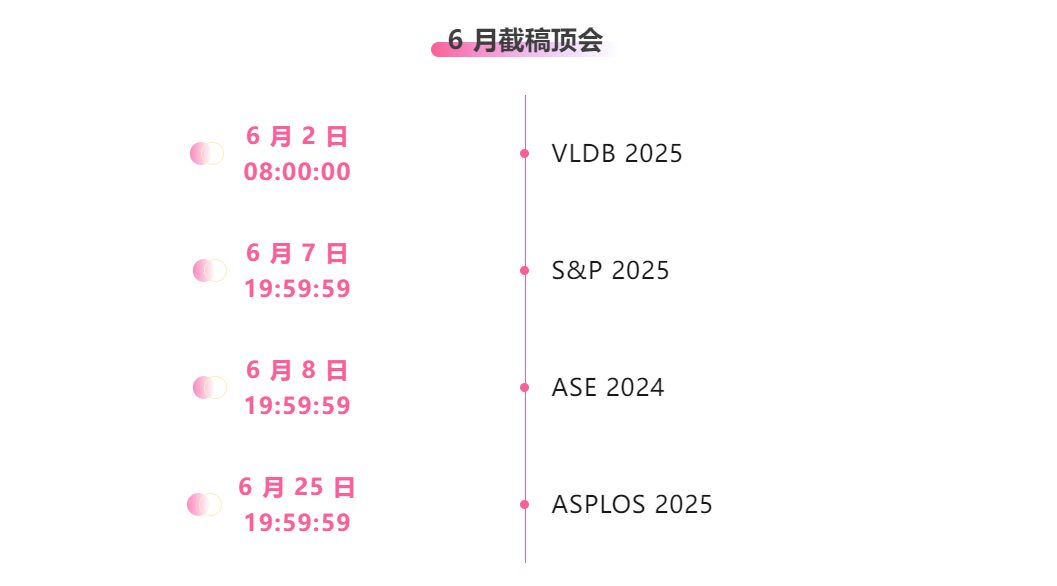
Suivi unique des principales conférences universitaires sur l'IA :https://hyper.ai/events
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
- Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 200 ensembles de données publiques
- Contient plus de 300 tutoriels en ligne classiques et populaires
- Interprétation de plus de 100 cas d'articles AI4Science
- Prend en charge la recherche de plus de 500 termes associés
- Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








