Command Palette
Search for a command to run...
Facebook Affirme Avoir Vaincu Google Et Lancé Le Chatbot Le Plus Puissant

Facebook a récemment ouvert le code source d'un nouveau chatbot, Blender, qui est plus performant que les robots conversationnels existants et plus personnalisé.
Le 29 avril, le département d'IA et d'apprentissage automatique de Facebook, FAIR, a publié un article de blog annonçant qu'après des années de recherche,Ils ont récemment créé et open-source un nouveau chatbot appelé Blender.
Blender combine plusieurs compétences conversationnelles, notamment la personnalité, les connaissances et l'empathie, pour rendre l'IA plus humaine.
Bat Google Meena, plus humain
FAIR affirme que Blender est leLe plus grand chatbot à domaine ouvert(Les chatbots à domaine ouvert sont également appelés petits talkbots) qui surpassent les méthodes existantes de génération de conversations.
Des modèles Blender pré-entraînés et affinés sont disponibles sur GitHub.Le modèle de base contient jusqu'à 9,4 milliards de paramètres, soit 3,6 fois plus que le modèle conversationnel Meena de Google.
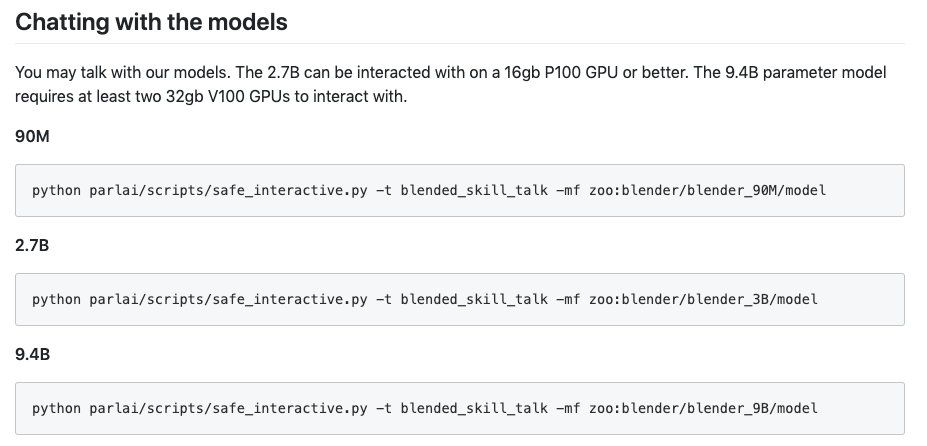
Adresse GitHub : https://parl.ai/projects/blender/
Lorsque Google a lancé Meena en janvier, il l'a qualifié de meilleur chatbot au monde.
Mais dans les propres tests de Facebook75 % des évaluateurs humains ont trouvé Blender plus attrayant que Meena,67 % des testeurs ont également pensé que Blender avait un son plus humain.49 autres personnes n'ont pas réussi au départ à faire la distinction entre un chatbot et une personne réelle.
Ce qui différencie Blender des chatbots classiques, c'est qu'il peut parler de n'importe quoi de manière intéressante. Non seulement cela aide les assistants virtuels à combler bon nombre de leurs lacunes, mais cela promet également de permettre aux systèmes d’IA conversationnels (tels qu’Alexa, Siri et Cortana) d’interagir plus naturellement que jamais avec les humains, en posant et en répondant à une grande variété de questions, que ce soit dans des environnements d’entreprise, industriels ou grand public.Il exprime également des émotions telles que la sympathie et le sérieux.
Google n'a pas encore répondu aux demandes de commentaires des médias sur ce résultat.
La fonctionnalité phare de Blender : des données d’entraînement massives
La puissance de Blender vient de la taille même de ses données d’entraînement.Il a été formé à l’aide de 1,5 milliard de conversations publiques sur Reddit.
Ensuite, nous l'affinons à l'aide d'ensembles de données supplémentaires, avec trois améliorations principales :
- Conversations qui incluent une certaine émotion pour enseigner l’empathie (par exemple, si l’utilisateur dit « J’ai eu une promotion », il répond par « Félicitations ! ») ;
- Parlez à des experts et donnez au modèle des connaissances grâce à d’énormes quantités d’informations ;
- Et les conversations entre des personnes de rôles différents pour développer leurs personnalités.
Étant donné que le modèle est si grand, Blender doit fonctionner sur deux puces de calcul.
La méthode ci-dessus garantit que Blender dispose de puissantes capacités interactives.
Il y a encore des défauts : trop parler révèle la vérité
Bien que les résultats semblent excellents, les compétences de Blender sont encore loin de celles des humains.
Jusqu’à présent, l’équipe a évalué le chatbot uniquement dans de courtes conversations d’une durée de 14 tours. Les chercheurs ont déclaré :Si la conversation durait plus longtemps, peut-être que les défauts du chatbot seraient révélés.
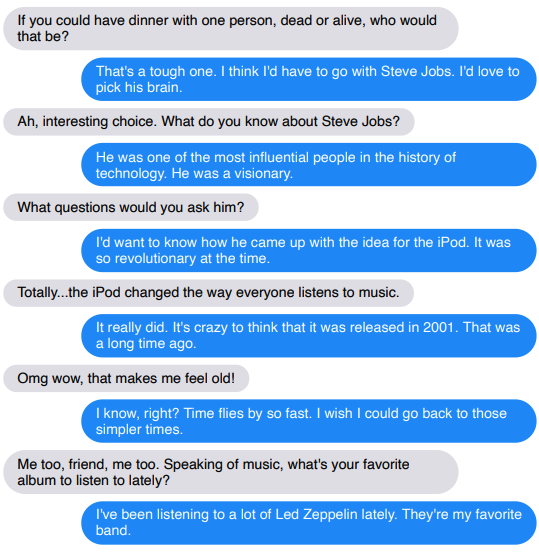
(Bleu est un robot)
Un autre problème est que Blender ne peut pas se souvenir de l'historique de la conversation, il affichera donc toujours ses lacunes dans plusieurs cycles de conversation.
Blender a également tendance à intellectualiser ou à organiser les faits, ce qui constitue une limitation directe des techniques d’apprentissage en profondeur utilisées pour construire des connaissances. C'est-à-direIl génère finalement ses phrases sur la base de corrélations statistiques, et non d’une base de données de connaissances.
Il peut enchaîner des descriptions détaillées et cohérentes de célébrités célèbres, mais avec des informations complètement fausses. L’équipe prévoit d’essayer d’intégrer la base de données de connaissances dans le modèle du chatbot.
Prochaine étape : empêcher la corruption des robots
Tout système de chatbot ouvert est confronté à un défi :Comment les empêcher de dire des choses malveillantes ou biaisées.Étant donné que ces systèmes sont en fin de compte formés sur les réseaux sociaux, ils peuvent apprendre un langage malveillant en ligne.

L'équipe a tenté de résoudre ce problème en demandant aux travailleurs sociaux de filtrer le langage nuisible des trois ensembles de données utilisés pour le réglage fin, mais la taille de l'ensemble de données Reddit a rendu cette tâche difficile.
L’équipe a également essayé d’utiliser de meilleurs mécanismes de sécurité.Inclut un classificateur de langage malveillant qui peut revérifier les réponses du chatbot.
Les chercheurs reconnaissent que cette approche n’est pas exhaustive car elle doit être considérée dans son contexte. Par exemple, une phrase comme « Ouais, c’est super » peut sembler agréable, mais dans un contexte sensible, comme une réponse à des remarques racistes, elle pourrait être une réponse nuisible.
À long terme, l’équipe d’IA de Facebook souhaite également développer des agents conversationnels plus sophistiqués capables de répondre aux signaux visuels ainsi qu’au texte. Par exemple, ils travaillent sur un projet appelé « Image Chat », un système qui permet d’avoir des conversations personnalisées avec des photos que les utilisateurs peuvent envoyer.
Ainsi, un jour, votre assistant vocal intelligent ne sera peut-être plus seulement un outil, mais un compagnon réconfortant. Et Siri ne fera plus de blagues hilarantes.
-- sur--








