Command Palette
Search for a command to run...
Ensemble De Données De Détection Et De Segmentation Des Piétons Penn-Fudan
Date
Taille
URL de publication
L'ensemble de données de détection et de segmentation des piétons Penn-Fudan a été créé conjointement par des chercheurs de l'Université de Pennsylvanie et de l'Université Fudan, et est principalement utilisé pour les tâches de détection des piétons. Cet ensemble de données contient 170 images RVB haute résolution capturées à partir de séquences vidéo, et il y a 0 à 6 cibles piétonnes dans chaque image. La position de chaque piéton est marquée avec précision par une boîte rectangulaire (masque), fournissant des informations sur les coordonnées de la boîte englobante pour faciliter la formation et les tests de détection d'objets. La structure du fichier de l'ensemble de données est la suivante :
Annotation/:Contient les fichiers d'annotation pour chaque image.PedMasks/:Contient le masque de segmentation piéton correspondant à chaque image.PNGImages/:Contient toutes les images de l'ensemble de données. Les images sont collectées dans une variété d'environnements, tels que des campus, des rues, des passages piétons, etc., couvrant différentes conditions d'éclairage, postures de piétons et situations d'occlusion. Au total, 345 cas piétons sont annotés. Il y a au moins un piéton dans chaque image, et certaines images ont plusieurs piétons. Toutes les images sont annotées au format PASCAL VOC, y compris des cadres de délimitation précis et des masques de segmentation au niveau des pixels pour chaque piéton.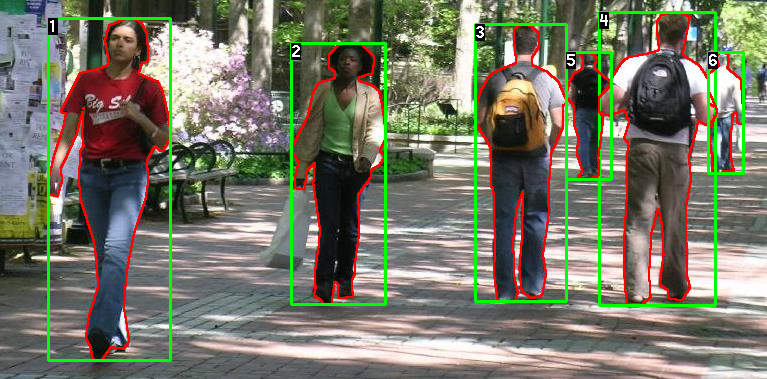
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.