Command Palette
Search for a command to run...
Ensemble De Données De Référence Pour La Récupération De Texte BRIGHT
Date
Taille
URL de publication
URL du document
* Cet ensemble de données prend en charge l'utilisation en ligne.Cliquez ici pour sauter.
Cet ensemble de données est un nouveau benchmark de récupération de texte lancé en 2024 par l'Université de Hong Kong, l'Université de Princeton, l'Université de Washington et Google Cloud AI Research.BRIGHT : une référence réaliste et stimulante pour la récupération intensive de raisonnement".
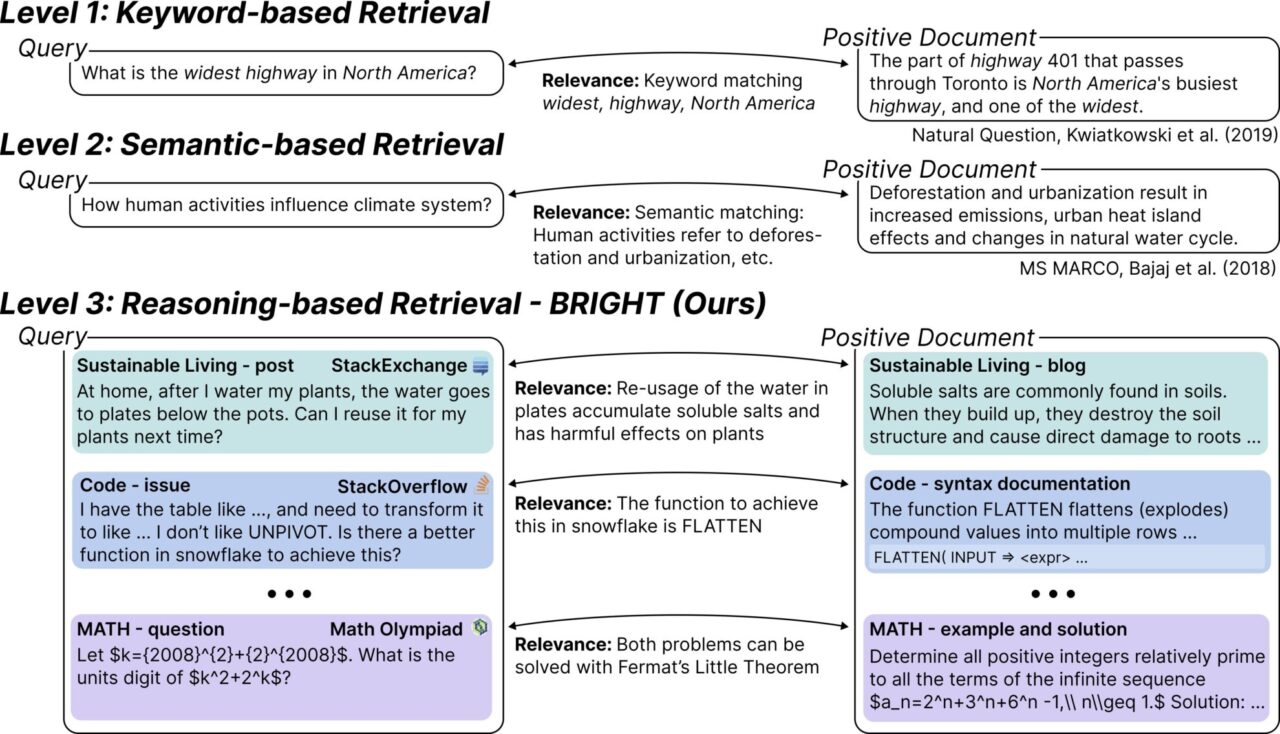
BRIGHT est le premier benchmark de recherche de texte qui nécessite un raisonnement approfondi pour récupérer les documents pertinents. L'équipe de recherche a collecté 1 385 requêtes réelles provenant de différents domaines (StackExchange, LeetCode et concours de mathématiques), toutes issues de données artificielles réelles. L'équipe a associé ces requêtes à des pages Web liées à des réponses StackExchange et à des théorèmes marqués dans les problèmes de l'Olympiade de mathématiques.
Il est spécifiquement conçu pour évaluer et tester les performances des systèmes de récupération lors du traitement de requêtes complexes. Ces requêtes nécessitent non seulement une correspondance de mots-clés, mais également des capacités de raisonnement approfondies pour identifier les documents pertinents. En termes simples, BRIGHT teste si le système de récupération peut « comprendre » la logique et le contexte derrière la requête, pas seulement le texte de surface. Par exemple, un économiste souhaite trouver des documents sur la manière dont les activités humaines affectent le système climatique. Ce problème ne se limite pas à la recherche de mots-clés, mais nécessite de comprendre la relation entre les activités humaines (telles que la déforestation et l’urbanisation) et le changement climatique.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.