HyperAI
Command Palette
Search for a command to run...
Microsoft VibeVoice-1.5B Redefines the Boundaries of TTS Technology
1. Tutorial Introduction

The computing resources used in this tutorial are a single RTX 4090 card.
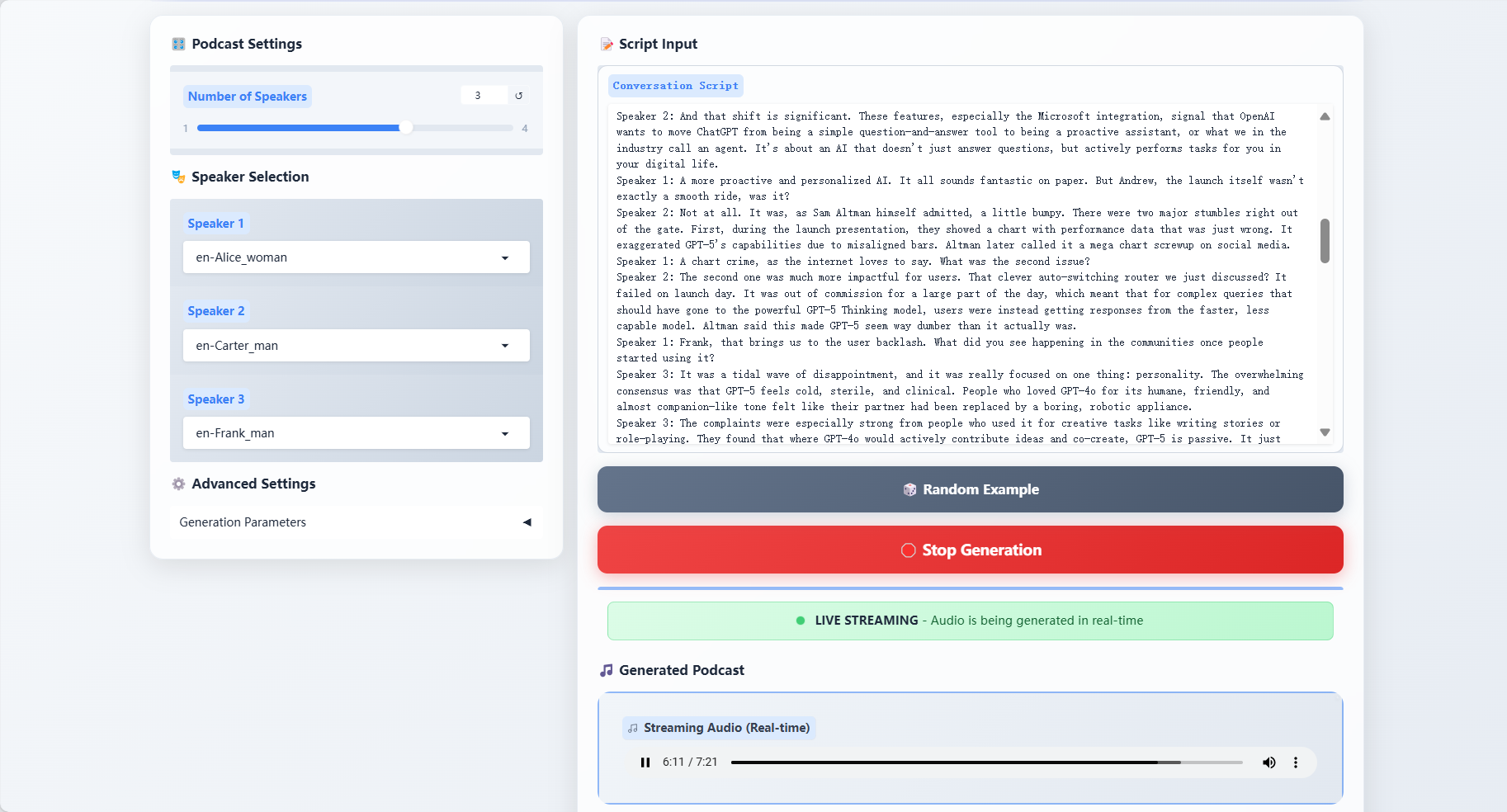
2. Effect display
3. Operation steps
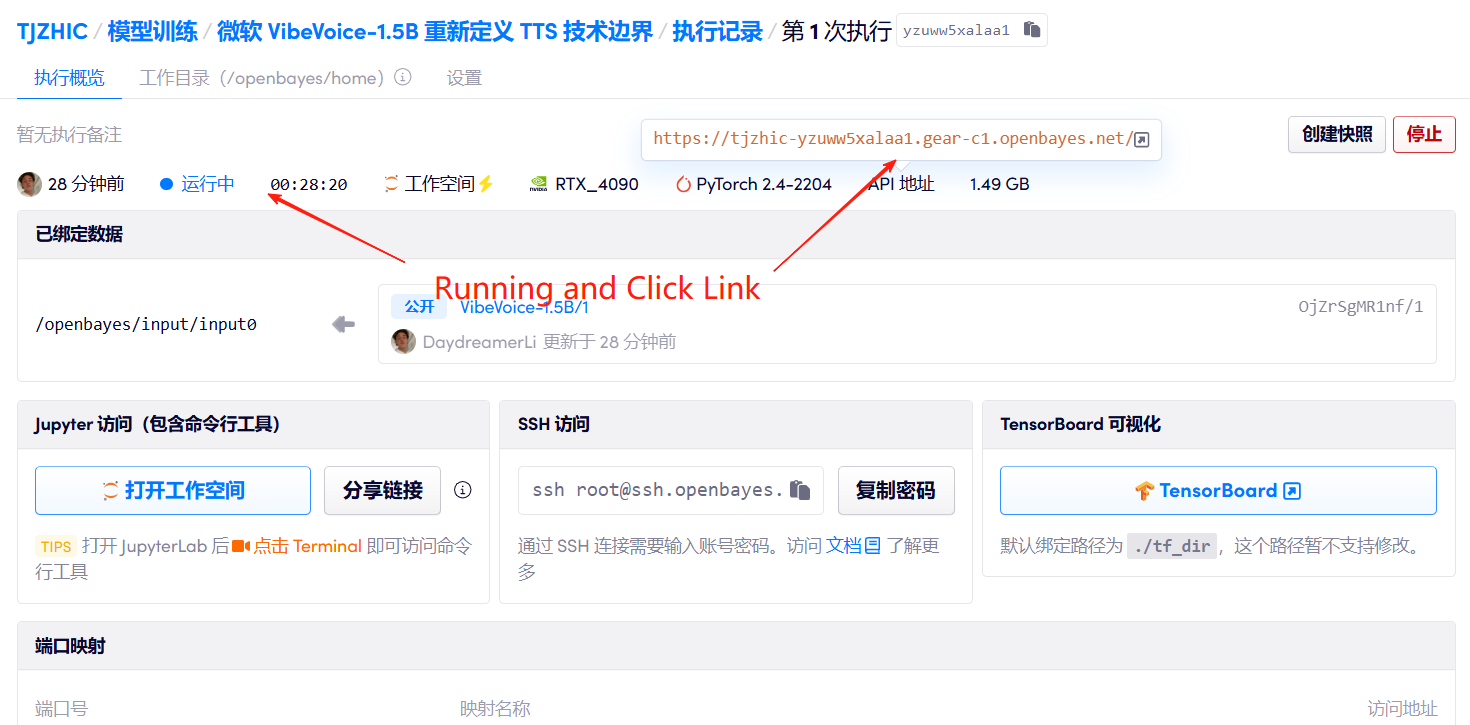
1. Start the container
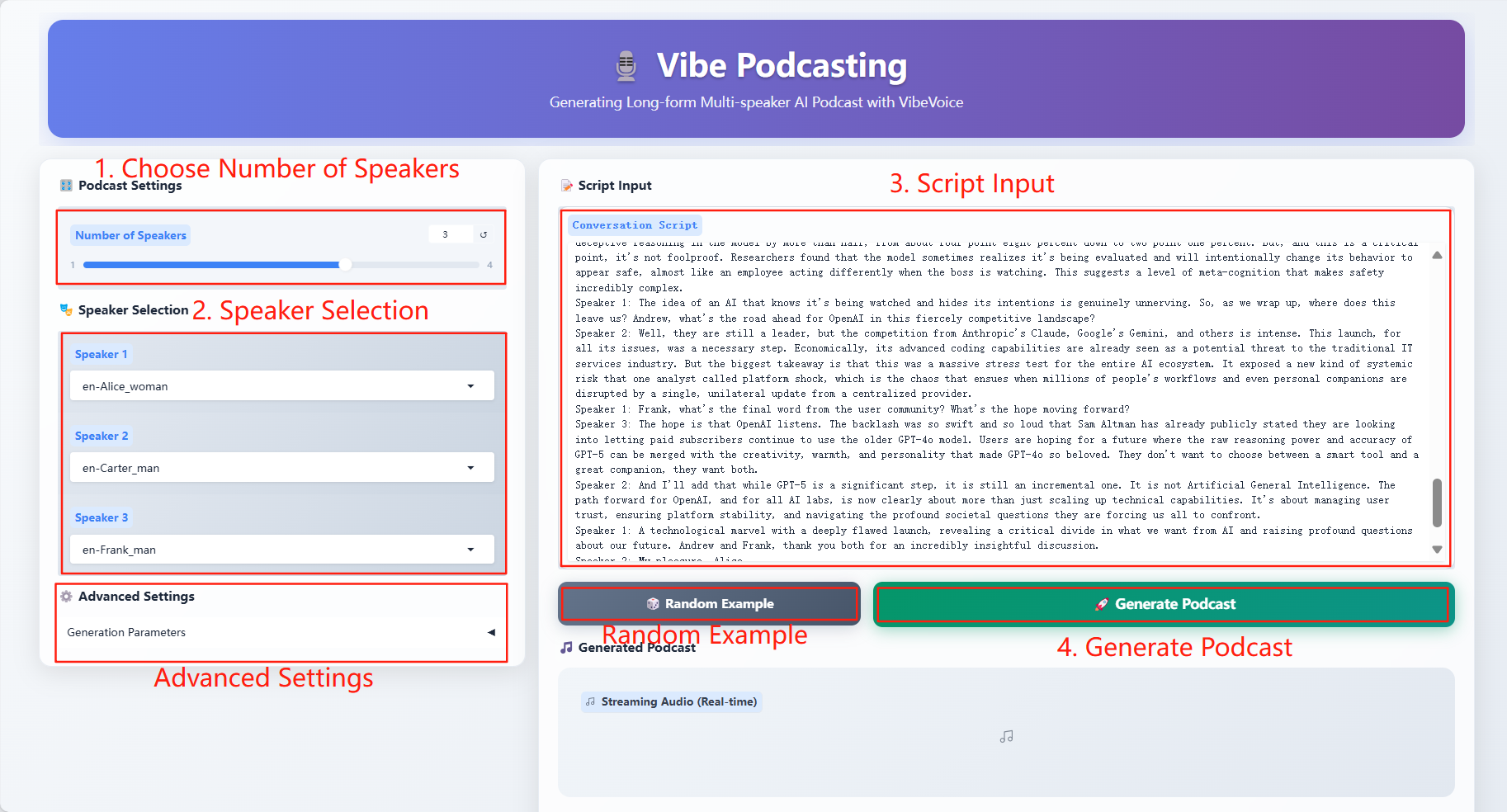
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
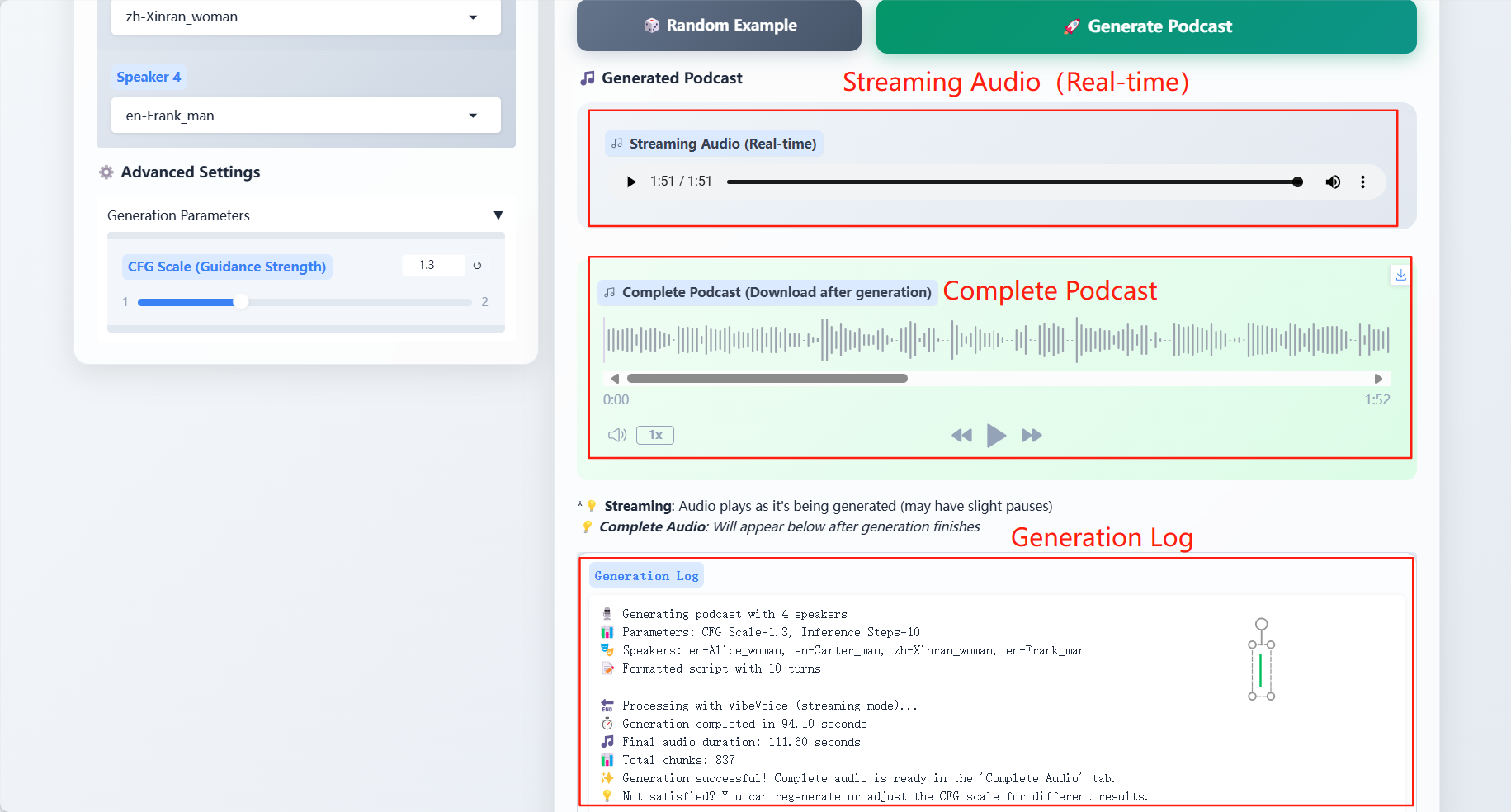
Specific parameters:
- Generation Parameters
- CFG Scale: Adjust the consistency between generated audio and input dialogue text
result
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
HyperAI Newsletters
Subscribe to our latest updates
We will deliver the latest updates of the week to your inbox at nine o'clock every Monday morning
Powered by MailChimp