Command Palette
Search for a command to run...
Ovis-U1-3B: Multimodal Understanding and Generation Model
Date
Size
1.19 GB
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

Ovis-U1-3B is a multimodal unified model released by the Alibaba Group's Ovis team on June 29, 2025. The model integrates three core capabilities: multimodal understanding, text-to-image generation, and image editing. Based on an advanced architecture and a collaborative unified training method, it achieves high-fidelity image synthesis and efficient text-visual interaction. In multiple academic benchmark tests, including multimodal understanding, generation, and editing, Ovis-U1 has achieved leading results, demonstrating strong generalization ability and excellent performance. Related research papers are available. Ovis-U1 Technical Report .
This tutorial uses a single RTX 4090 graphics card. It provides three examples for testing: Image + Text → Image, Text → Image, and Image → Text.
2. Project Examples

3. Operation steps
1. After starting the container, click the API address to enter the Web interface
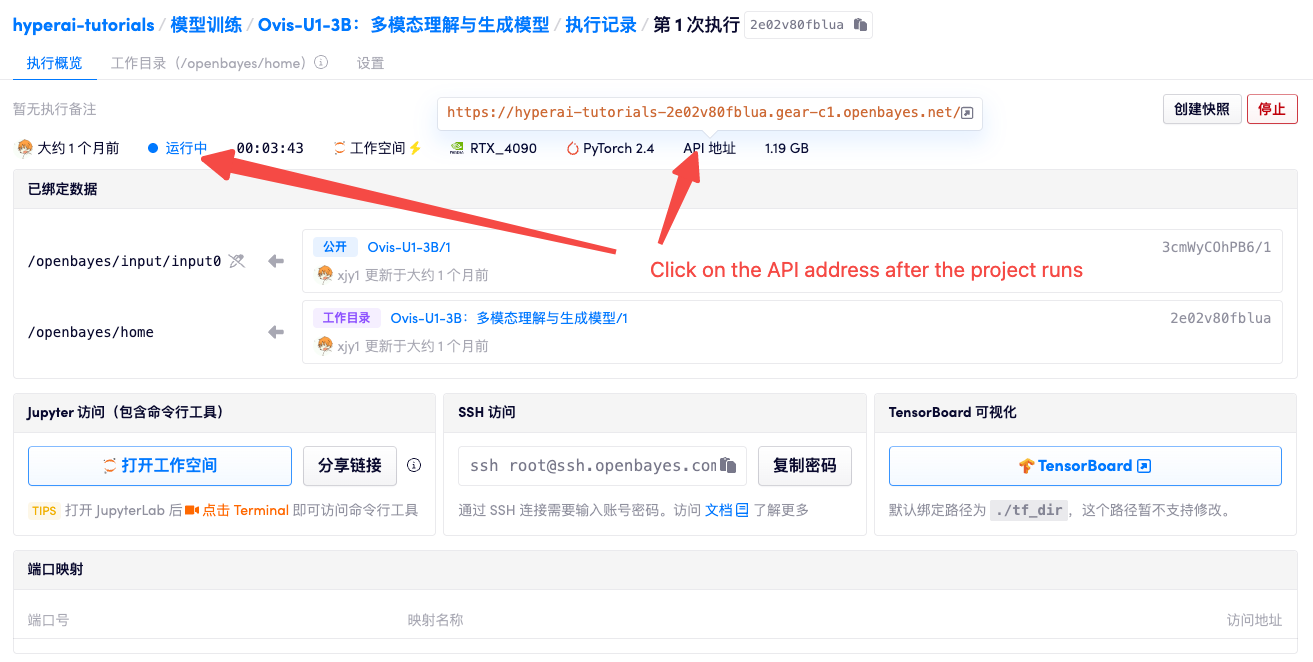
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
2.1 Image + Text → Image
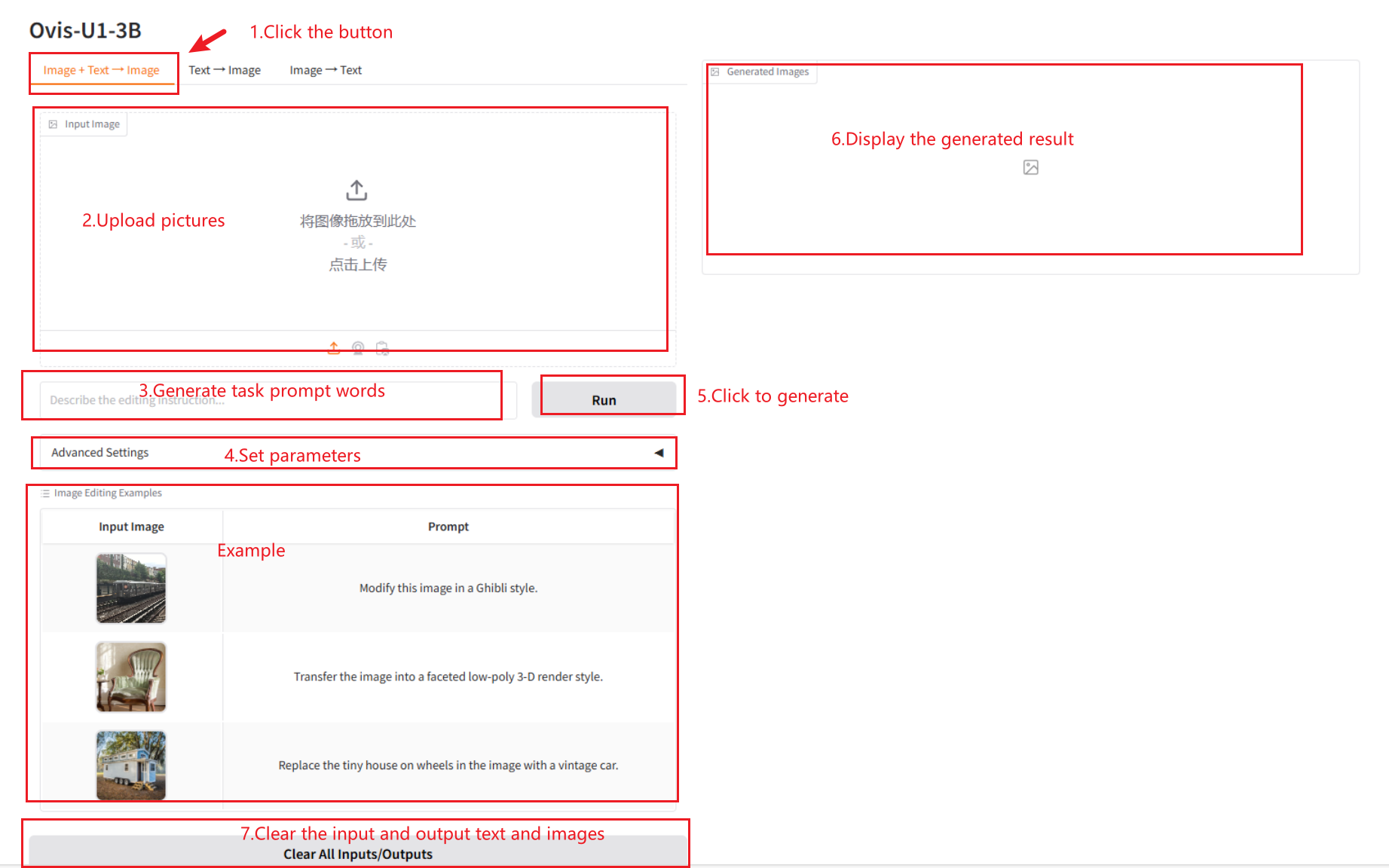
Parameter Description
- Advanced Settings
- Image Guidance Scale: Controls the strength of the influence of textual cues on generated images.
- Text Guidance Scale: Controls the influence of the input image on the generated image.
- Steps: The number of iterations for image generation.
- Seed: Random seed for repeatability of the image generation process.
- Randomize seed: Randomize the seed. A new seed will be randomly generated each time an image is generated.
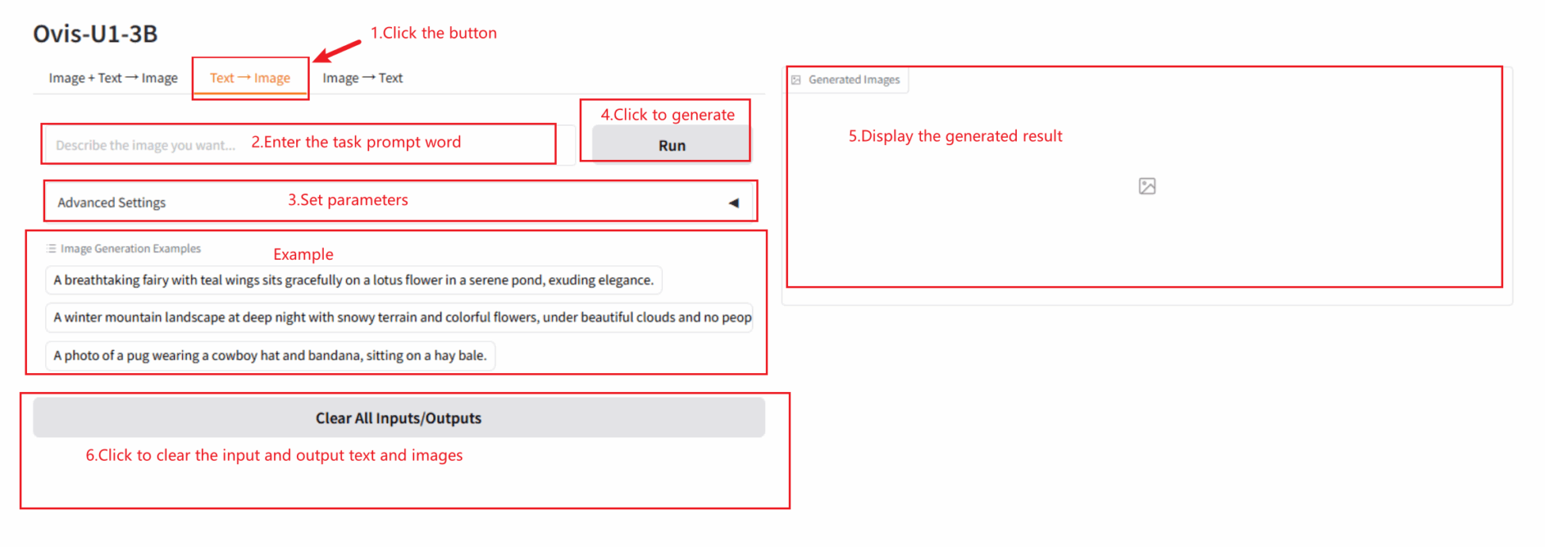
2.2 Text → Image
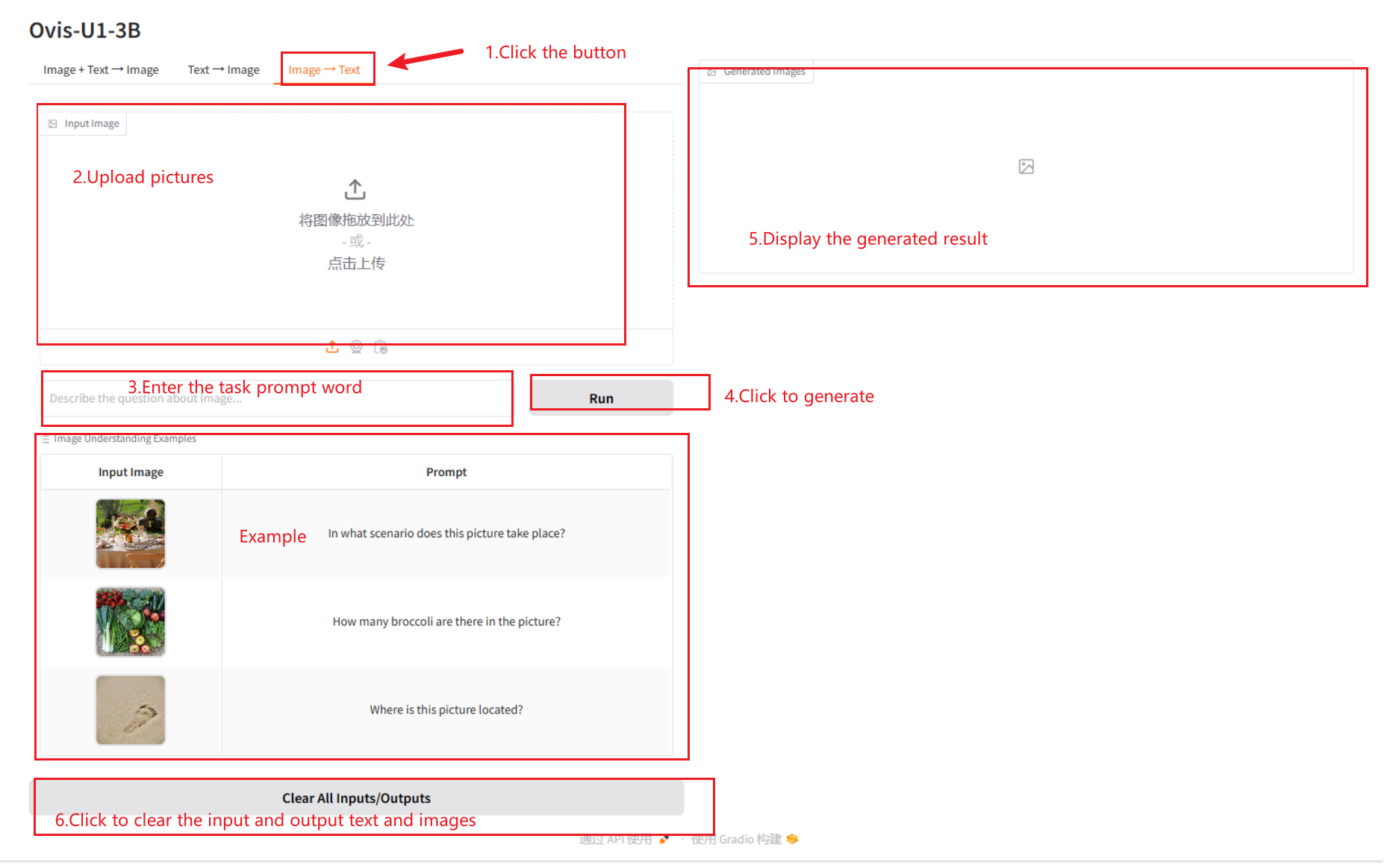
2.3 Image → Text
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@article{wang2025ovisu1,
title={Ovis-U1 Technical Report},
author={Wang, Guo-Hua and Zhao, Shanshan and Zhang, Xinjie and Cao, Liangfu and Zhan, Pengxin and Duan, Lunhao and Lu, Shiyin and Fu, Minghao and Zhao, Jianshan and Li, Yang and Chen, Qing-Guo},
journal={arXiv preprint arXiv:2506.23044},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.