HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Rethinking Cross-lingual Gaps from a Statistical Viewpoint

Unleashing Scientific Reasoning for Bio-experimental Protocol Generation via Structured Component-based Reward Mechanism


























Rethinking Cross-lingual Gaps from a Statistical Viewpoint
Unleashing Scientific Reasoning for Bio-experimental Protocol Generation via Structured Component-based Reward Mechanism
Skyfall-GS: Synthesizing Immersive 3D Urban Scenes from Satellite Imagery
Emergent Misalignment via In-Context Learning: Narrow in-context examples can produce broadly misaligned LLMs
NANO3D: A Training-Free Approach for Efficient 3D Editing Without Masks
Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset
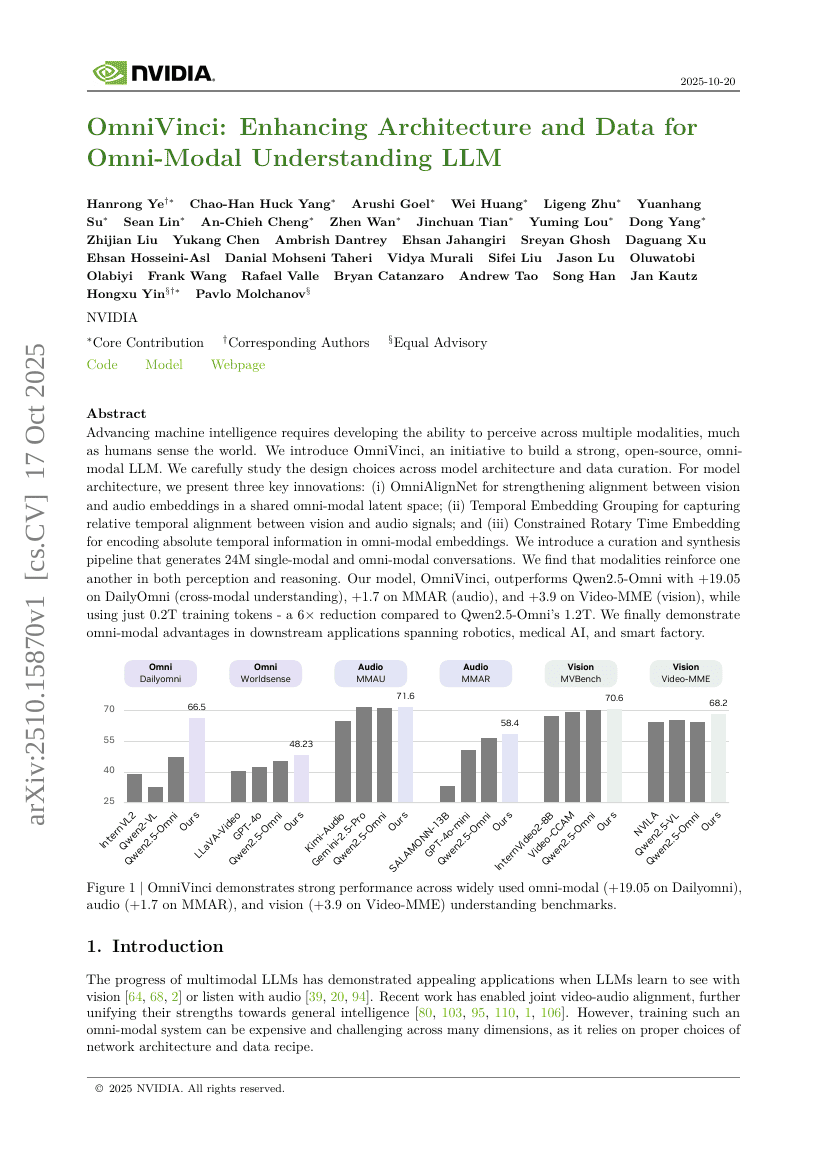
OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
A Theoretical Study on Bridging Internal Probability and Self-Consistency for LLM Reasoning
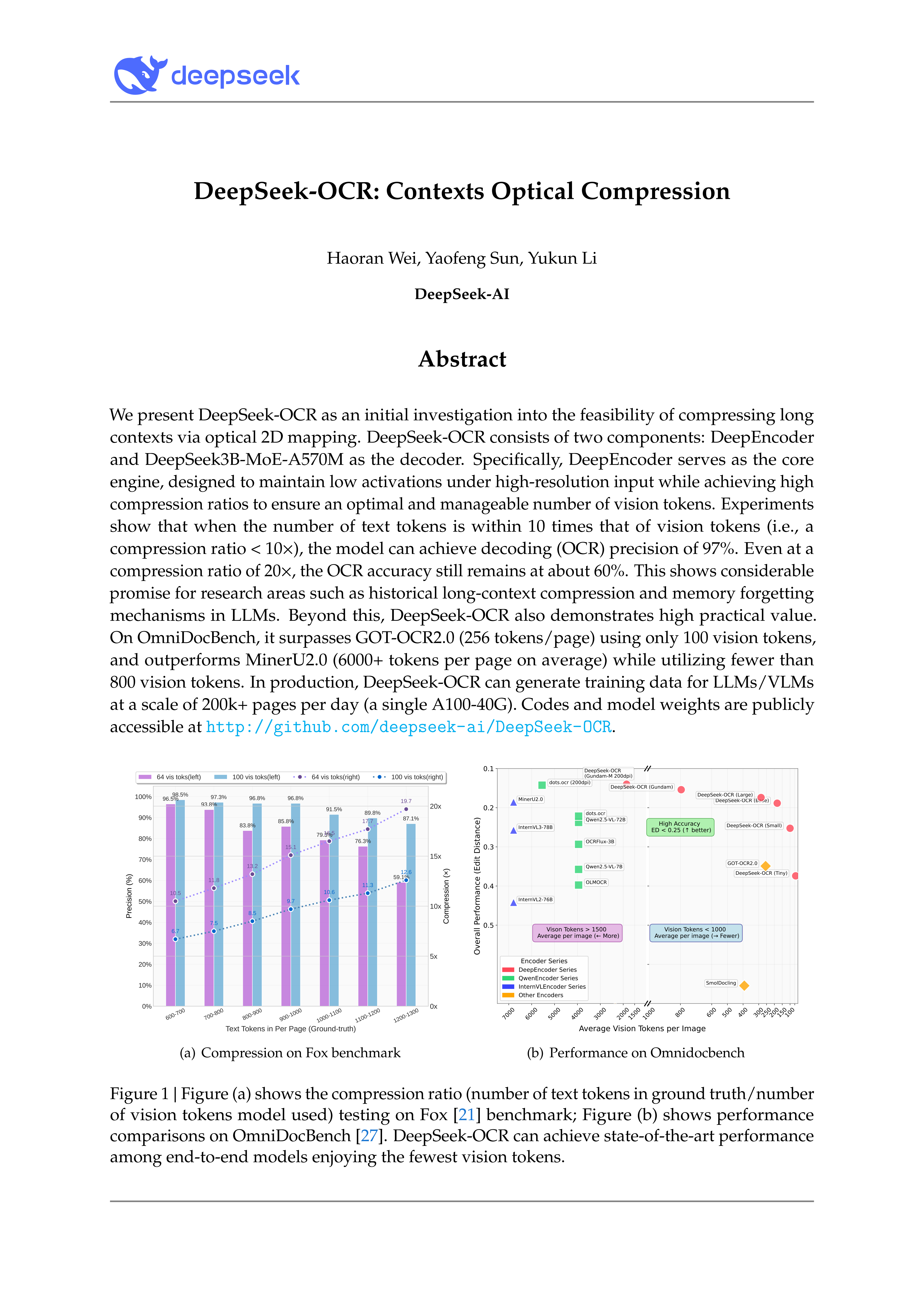
DeepSeek-OCR: Contexts Optical Compression
Direct Preference Optimization with Unobserved Preference Heterogeneity: The Necessity of Ternary Preferences
Elucidated Rolling Diffusion Models for Probabilistic Weather Forecasting
ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints
From Pixels to Words -- Towards Native Vision-Language Primitives at Scale
AI for Service: Proactive Assistance with AI Glasses
WithAnyone: Towards Controllable and ID Consistent Image Generation
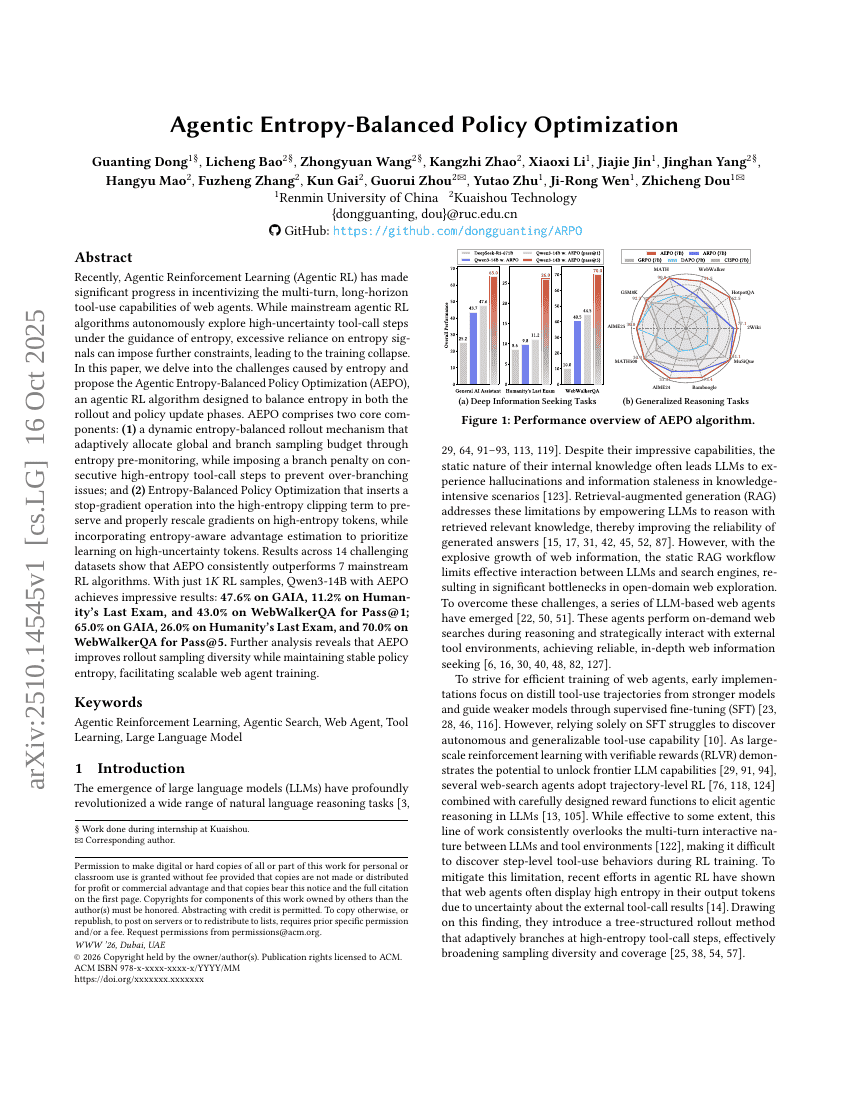
Agentic Entropy-Balanced Policy Optimization
When Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA
Predicting sequence-specific amplification efficiency in multi-template PCR with deep learning
The Genome Analysis Toolkit: A MapReduce framework for analyzing next-generation DNA sequencing data
LAMMPS - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Scaling Large Language Models for Next-Generation Single-Cell Analysis
A Survey of Vibe Coding with Large Language Models
Detect Anything via Next Point Prediction
Scaling Language-Centric Omnimodal Representation Learning
DITING: A Multi-Agent Evaluation Framework for Benchmarking Web Novel Translation
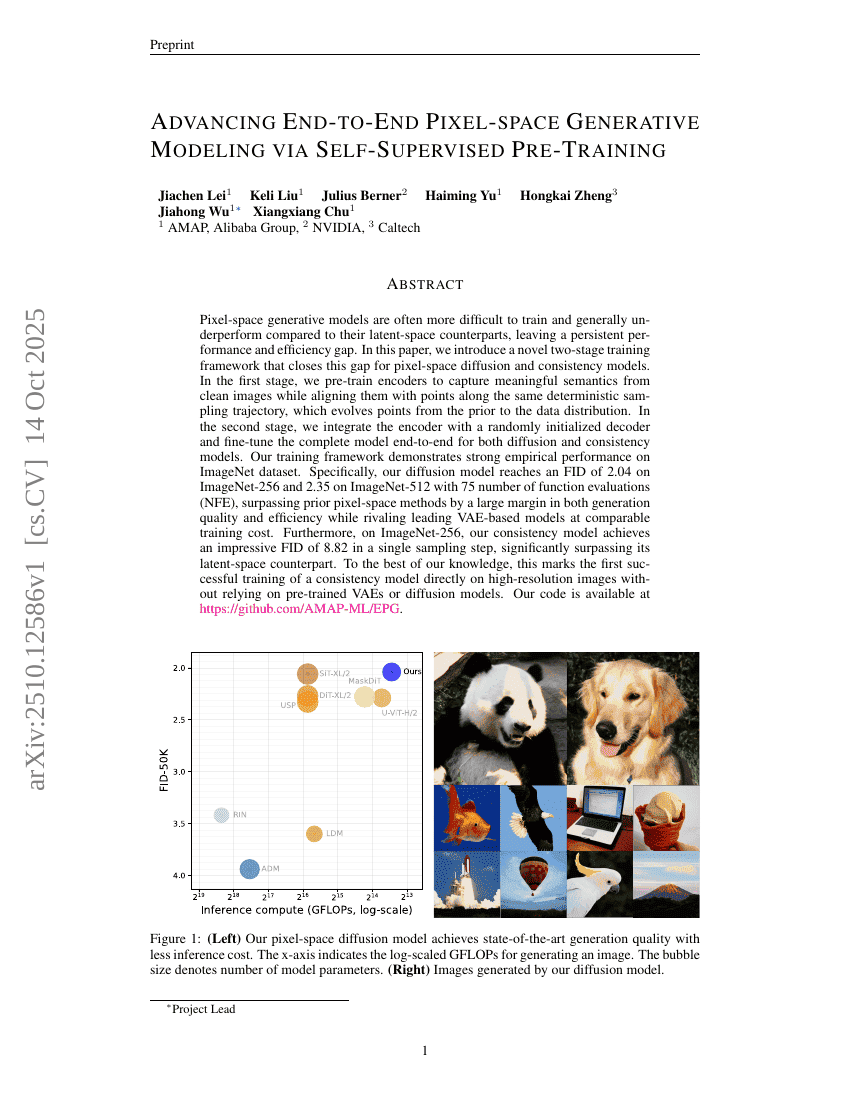
Advancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
Spatial Forcing: Implicit Spatial Representation Alignment for Vision-language-action Model
Asking Clarifying Questions for Preference Elicitation With Large Language Models
CTRL-Rec: Controlling Recommender Systems With Natural Language
Skyfall-GS: Synthesizing Immersive 3D Urban Scenes from Satellite Imagery
Emergent Misalignment via In-Context Learning: Narrow in-context examples can produce broadly misaligned LLMs
NANO3D: A Training-Free Approach for Efficient 3D Editing Without Masks
Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset
OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
A Theoretical Study on Bridging Internal Probability and Self-Consistency for LLM Reasoning
DeepSeek-OCR: Contexts Optical Compression
Direct Preference Optimization with Unobserved Preference Heterogeneity: The Necessity of Ternary Preferences
Elucidated Rolling Diffusion Models for Probabilistic Weather Forecasting
ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints
From Pixels to Words -- Towards Native Vision-Language Primitives at Scale
AI for Service: Proactive Assistance with AI Glasses
WithAnyone: Towards Controllable and ID Consistent Image Generation
Agentic Entropy-Balanced Policy Optimization
When Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA
Predicting sequence-specific amplification efficiency in multi-template PCR with deep learning
The Genome Analysis Toolkit: A MapReduce framework for analyzing next-generation DNA sequencing data
LAMMPS - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Scaling Large Language Models for Next-Generation Single-Cell Analysis
A Survey of Vibe Coding with Large Language Models
Detect Anything via Next Point Prediction
Scaling Language-Centric Omnimodal Representation Learning
DITING: A Multi-Agent Evaluation Framework for Benchmarking Web Novel Translation
Advancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
Spatial Forcing: Implicit Spatial Representation Alignment for Vision-language-action Model
Asking Clarifying Questions for Preference Elicitation With Large Language Models
CTRL-Rec: Controlling Recommender Systems With Natural Language