HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Learning to Trust: Bayesian Adaptation to Varying Suggester Reliability in Sequential Decision Making

GroupRank: A Groupwise Reranking Paradigm Driven by Reinforcement Learning























Learning to Trust: Bayesian Adaptation to Varying Suggester Reliability in Sequential Decision Making
GroupRank: A Groupwise Reranking Paradigm Driven by Reinforcement Learning
MMaDA-Parallel: Multimodal Large Diffusion Language Models for Thinking-Aware Editing and Generation
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Part-X-MLLM: Part-aware 3D Multimodal Large Language Model
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
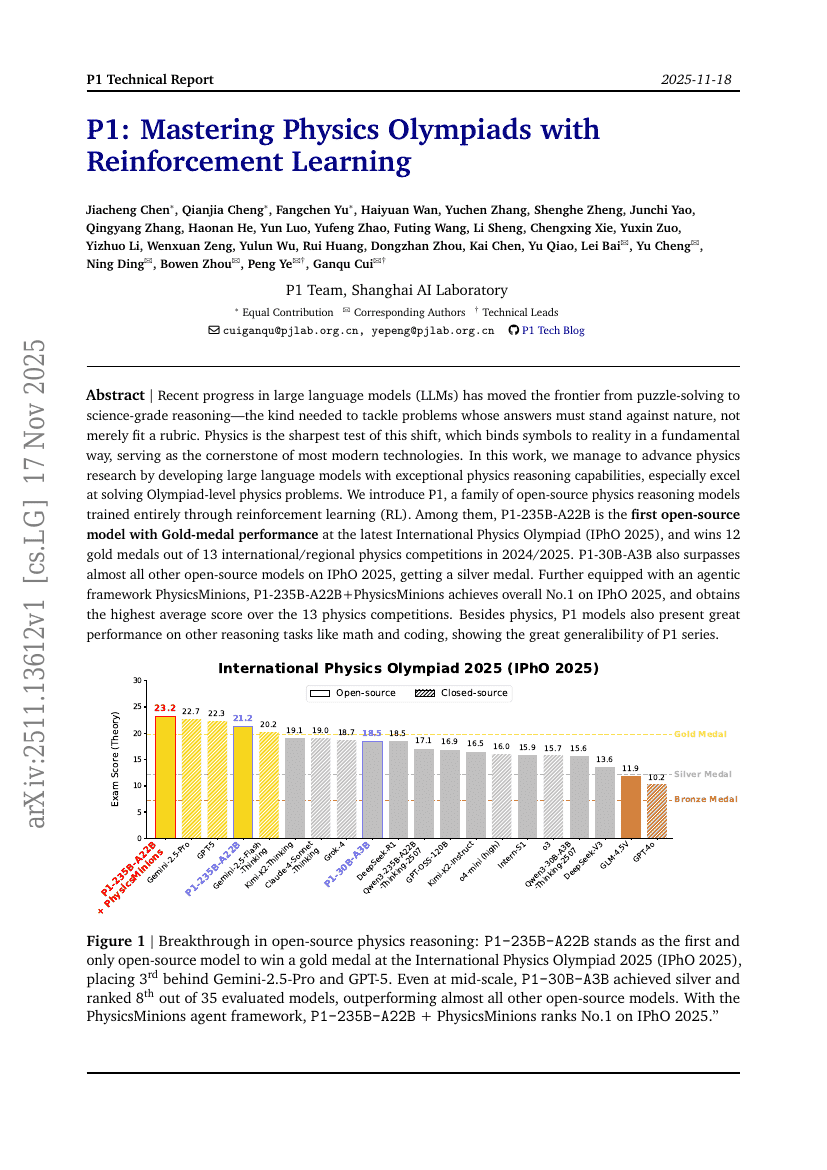
P1: Mastering Physics Olympiads with Reinforcement Learning
Lancelot: Towards Efficient and Privacy-Preserving Byzantine-Robust Federated Learning within Fully Homomorphic Encryption
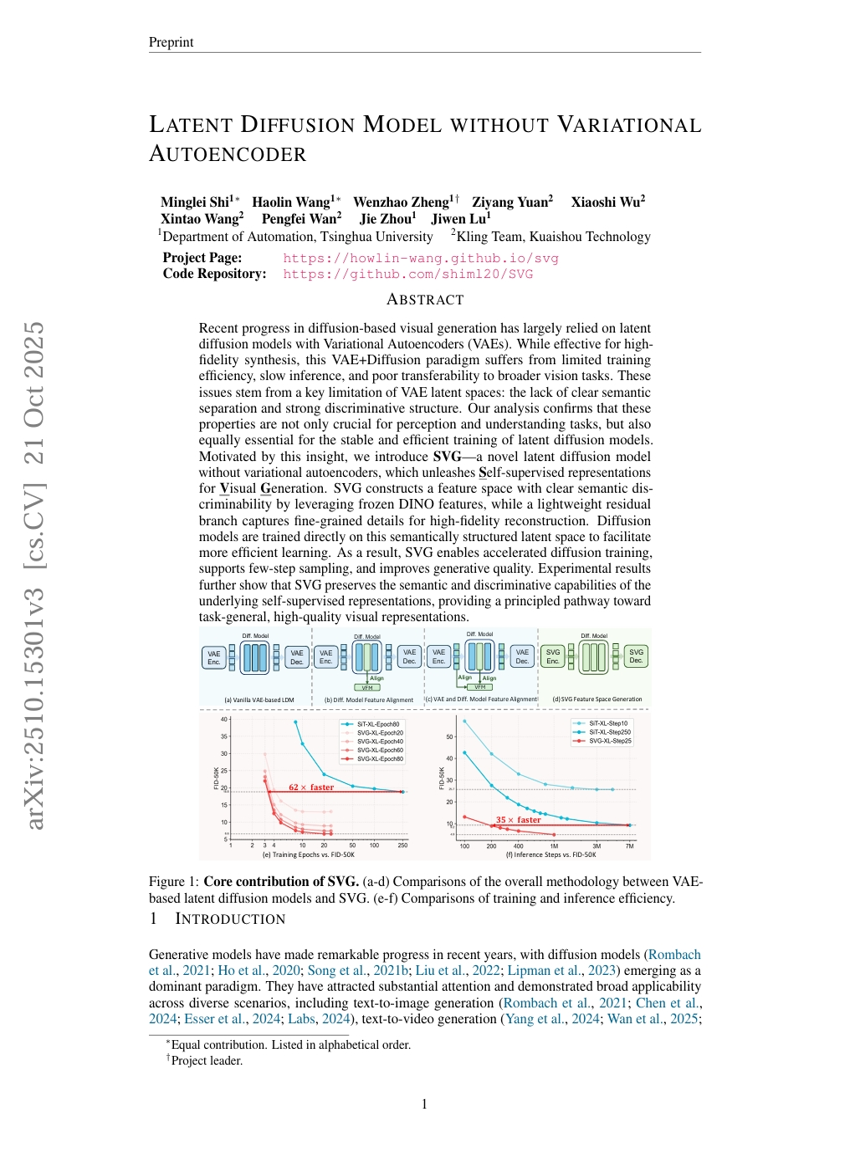
Latent Diffusion Model without Variational Autoencoder
RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
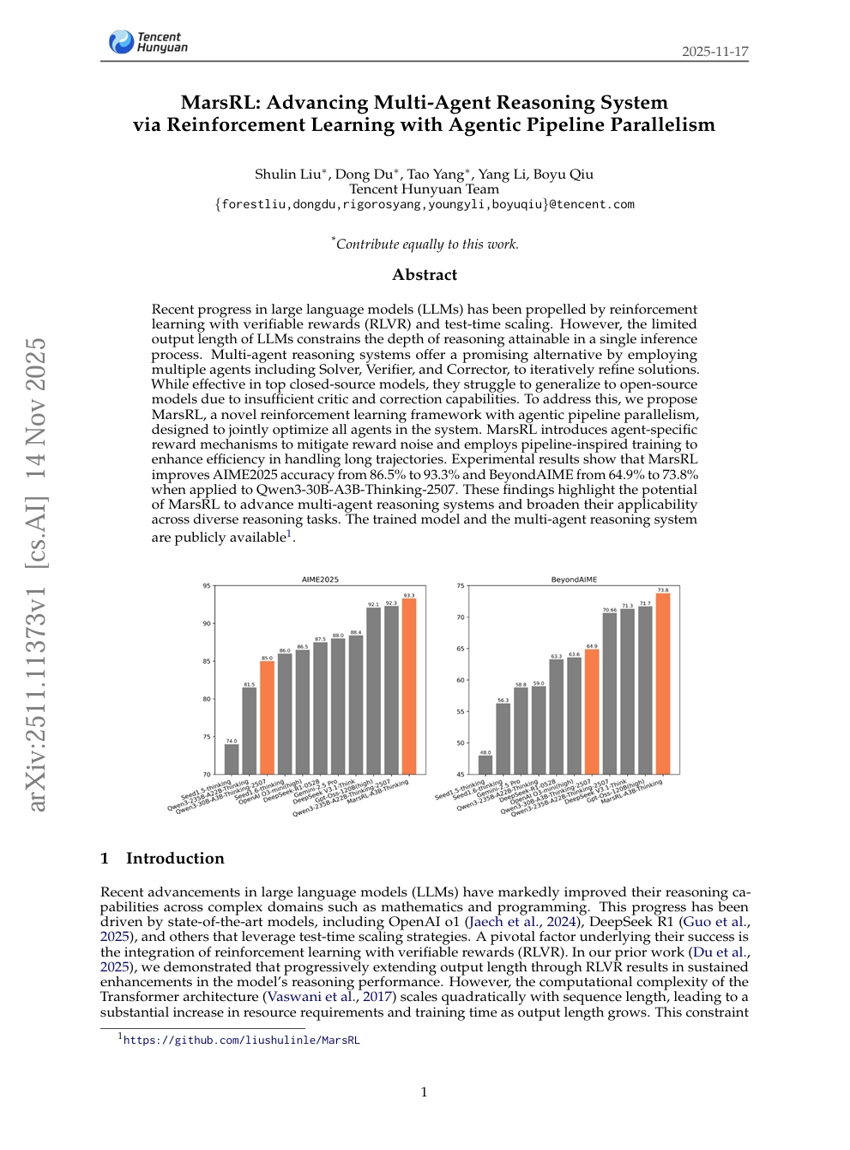
MarsRL: Advancing Multi-Agent Reasoning System via Reinforcement Learning with Agentic Pipeline Parallelism
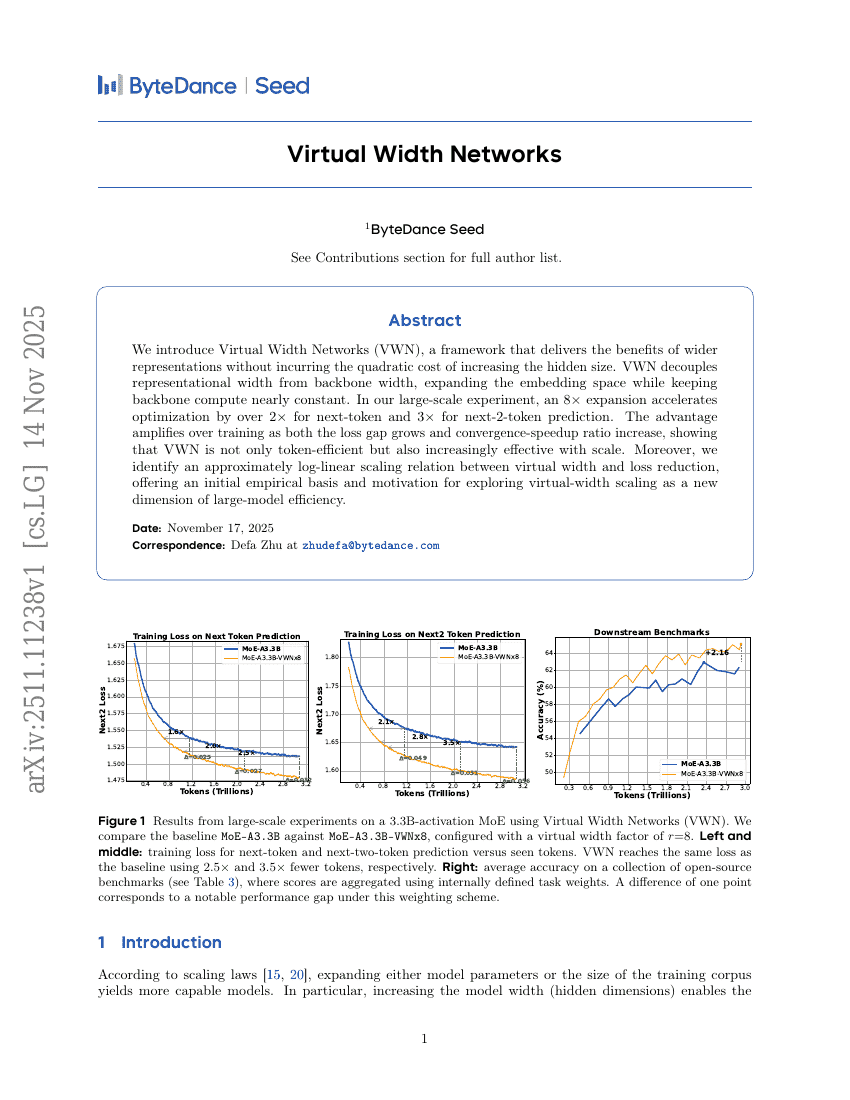
Virtual Width Networks
AIonopedia: an LLM agent orchestrating multimodal learning for ionic liquid discovery
UI2CodeN: A Visual Language Model for Test-Time Scalable Interactive UI-to-Code Generation
GGBench: A Geometric Generative Reasoning Benchmark for Unified Multimodal Models
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
DoPE: Denoising Rotary Position Embedding
BRFL: A Blockchain-based Byzantine-Robust Federated Learning Model
Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
SAC Flow: Sample-Efficient Reinforcement Learning of Flow-Based Policies via Velocity-Reparameterized Sequential Modeling
Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO
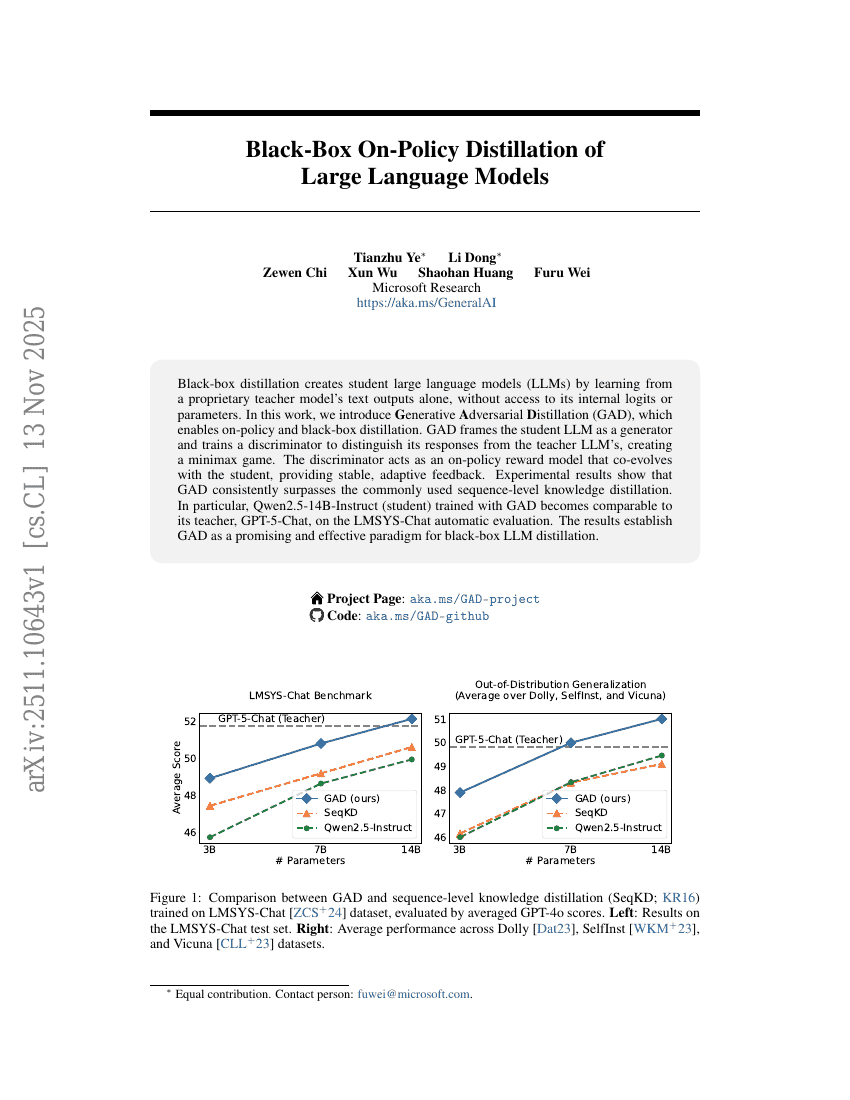
Black-Box On-Policy Distillation of Large Language Models
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models
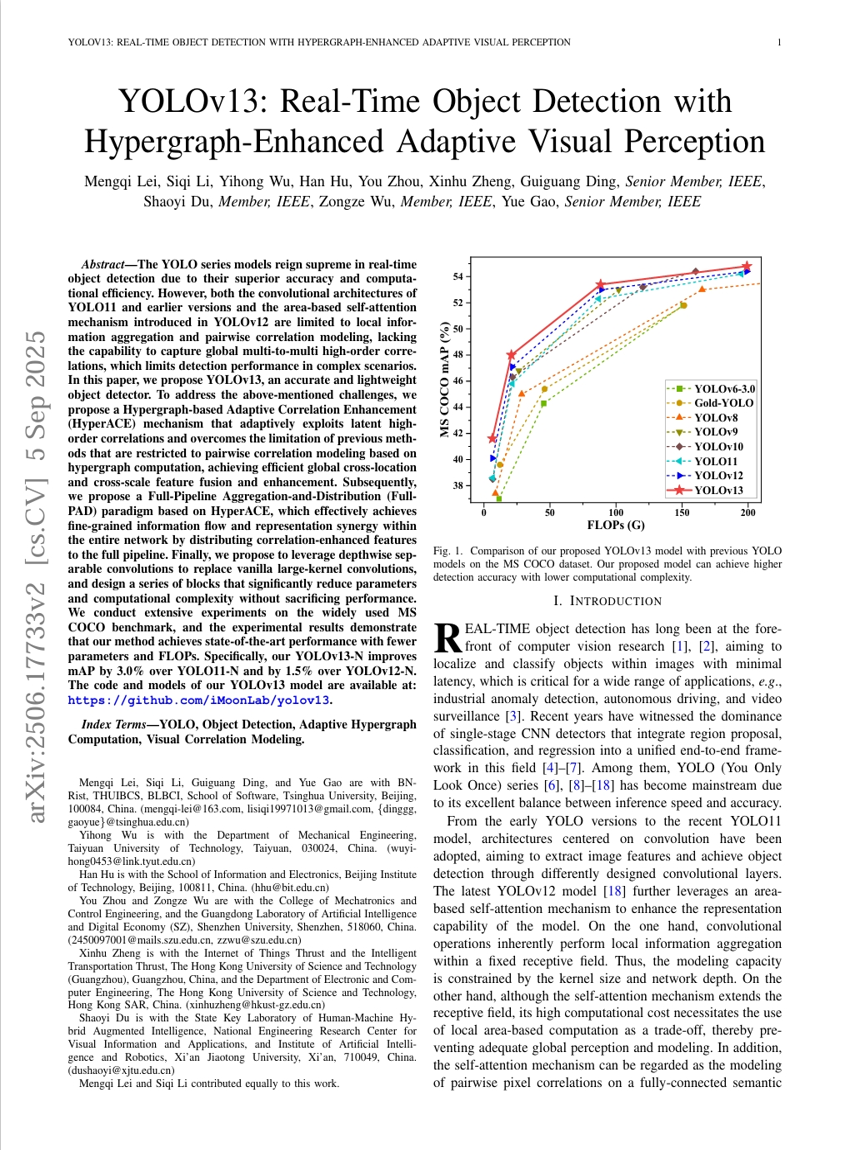
YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception
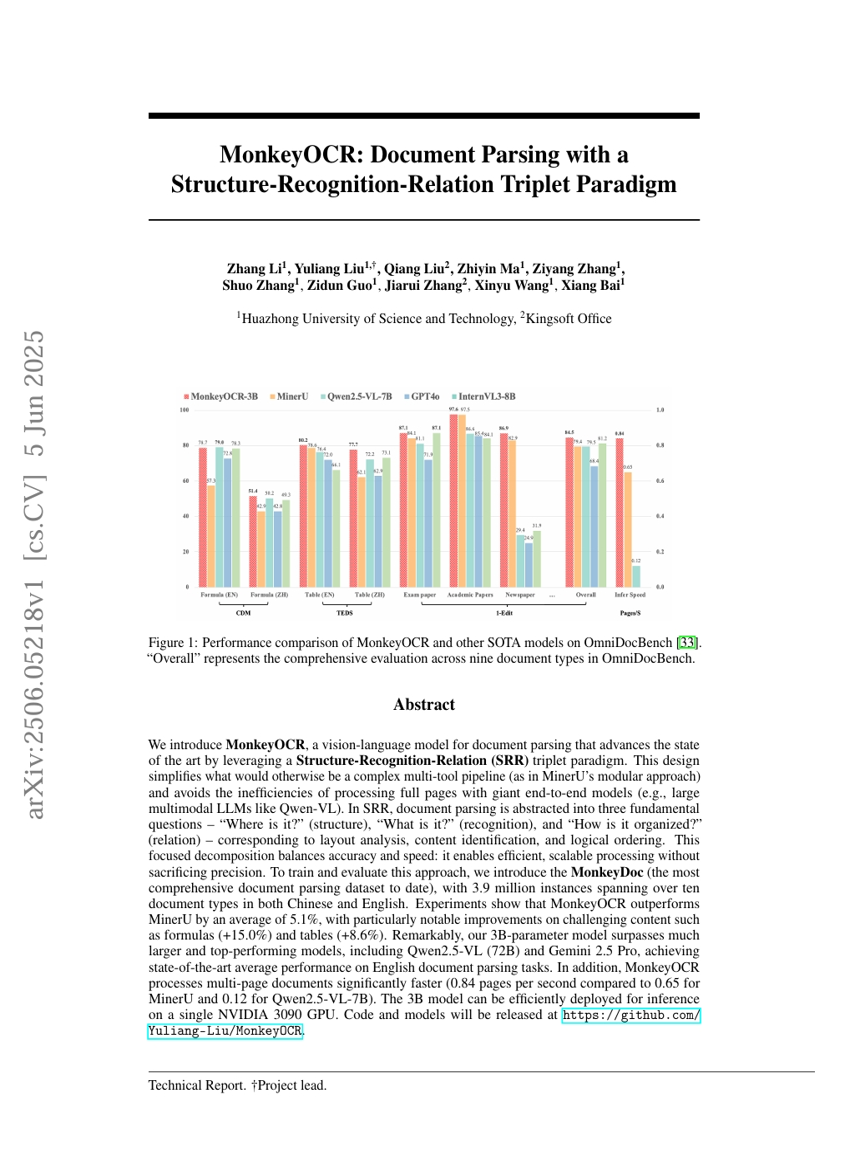
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Consensus Sampling for Safer Generative AI
Argus: Resilience-Oriented Safety Assurance Framework for End-to-End ADSs
MMaDA-Parallel: Multimodal Large Diffusion Language Models for Thinking-Aware Editing and Generation
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Part-X-MLLM: Part-aware 3D Multimodal Large Language Model
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
P1: Mastering Physics Olympiads with Reinforcement Learning
Lancelot: Towards Efficient and Privacy-Preserving Byzantine-Robust Federated Learning within Fully Homomorphic Encryption
Latent Diffusion Model without Variational Autoencoder
RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
MarsRL: Advancing Multi-Agent Reasoning System via Reinforcement Learning with Agentic Pipeline Parallelism
Virtual Width Networks
AIonopedia: an LLM agent orchestrating multimodal learning for ionic liquid discovery
UI2CodeN: A Visual Language Model for Test-Time Scalable Interactive UI-to-Code Generation
GGBench: A Geometric Generative Reasoning Benchmark for Unified Multimodal Models
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
DoPE: Denoising Rotary Position Embedding
BRFL: A Blockchain-based Byzantine-Robust Federated Learning Model
Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
SAC Flow: Sample-Efficient Reinforcement Learning of Flow-Based Policies via Velocity-Reparameterized Sequential Modeling
Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO
Black-Box On-Policy Distillation of Large Language Models
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models
YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Consensus Sampling for Safer Generative AI
Argus: Resilience-Oriented Safety Assurance Framework for End-to-End ADSs