Command Palette
Search for a command to run...
MathNet: A Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
MathNet: A Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
Shaden Alshammari Kevin Wen Abrar Zainal Mark Hamilton Navid Safaei Sultan Albarakati William T. Freeman Antonio Torralba
Abstract
Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce MATHNET, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models and mathematical retrieval in embedding-based systems. MATHNET spans 47 countries, 17 languages, and two decades of competitions, comprising 30,676 expert-authored problems with solutions across diverse domains. In addition to the core dataset, we construct a retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts. MATHNET supports three tasks: (i) Problem Solving, (ii), Math-Aware Retrieval, and (iii) Retrieval-Augmented Problem Solving. Experimental results show that even state-of-the-art reasoning models (78.4% for Gemini-3.1-Pro and 69.3% for GPT-5) remain challenged, while embedding models struggle to retrieve equivalent problems. We further show that RAG performance is highly sensitive to retrieval quality; for example, DeepSeek-V3.2-Speciale achieves gains of up to 12%, obtaining the highest scores on the benchmark.
One-sentence Summary
Researchers introduce MathNet, a large-scale multimodal and multilingual benchmark comprising 30,676 expert-authored Olympiad-level math problems across 17 languages that evaluates mathematical reasoning in generative models, math-aware retrieval in embedding-based systems, and retrieval-augmented problem solving.
Key Contributions
- The paper introduces MATHNET, a large-scale, multimodal, and multilingual dataset comprising 30,676 expert-authored Olympiad-level math problems and solutions spanning 47 countries and 17 languages.
- This work establishes a specialized retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts to evaluate embedding-based systems.
- Experimental results demonstrate the benchmark's utility across three tasks, showing that even state-of-the-art reasoning models struggle with the difficulty and that RAG performance is highly sensitive to retrieval quality.
Introduction
Mathematical problem solving serves as a fundamental benchmark for evaluating the reasoning capabilities of artificial intelligence. While existing datasets cover various domains, they often suffer from limited scale, a lack of multilingual and multimodal content, or insufficient expert-validated solutions for high-difficulty Olympiad level problems. Furthermore, prior retrieval systems frequently struggle to bridge the gap between symbolic equivalence and semantic similarity. The authors address these gaps by introducing MathNet, a large-scale multilingual and multimodal dataset featuring expert-validated problem pairs. By incorporating a fine-grained taxonomy of mathematical similarity, the authors enable more rigorous research into analogical reasoning, retrieval quality, and retrieval-augmented generation across different languages and modalities.
Dataset
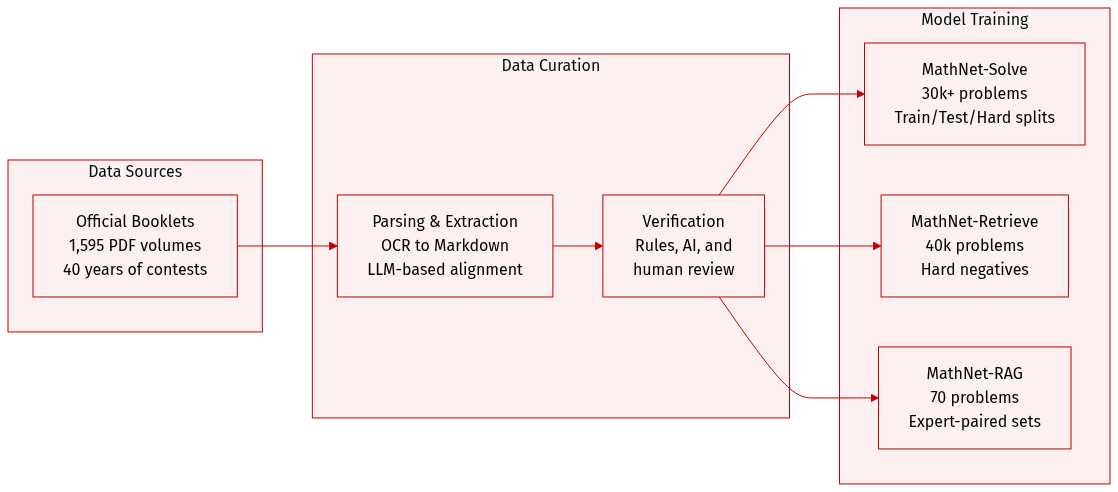
Dataset Overview: MathNet
The authors introduce MathNet, a large scale multimodal and multilingual dataset designed to evaluate mathematical reasoning and retrieval. Unlike existing benchmarks that rely on community platforms, MathNet is built exclusively from official national competition booklets spanning 40 years (1985 to 2025).
Dataset Composition and Subsets
The corpus is divided into three specialized datasets:
- MathNet-Solve: The core collection containing 30,676 expert authored Olympiad problems and solutions. It covers 143 competitions across 47 countries and 17 languages. The subset is organized into three splits:
- MathNet-Solve-train: 23,776 samples.
- MathNet-Solve-test: 6,400 samples.
- MathNet-Solve-test-hard: 500 samples.
- MathNet-Retrieve: A retrieval evaluation dataset consisting of 40,000 problems. It is constructed by taking 10,000 anchor problems from MathNet-Solve and generating one mathematically equivalent positive variant and three adversarial "hard negative" variants for each.
- MathNet-RAG: A non synthetic evaluation set for retrieval augmented generation. It consists of 70 total problems: 35 anchors paired with 35 expert curated real problems drawn from MathNet-Solve.
Processing and Extraction Pipeline
The authors employed a sophisticated multi stage pipeline to convert heterogeneous PDF volumes into a uniform format:
- Document Parsing: The team used the dots-ocr framework to convert 1,595 PDF volumes (over 25,000 pages) into Markdown, handling both digital typeset and scanned documents.
- Problem-Solution Alignment: To manage inconsistent numbering and interleaved layouts, the authors used a three stage LLM based pipeline. Gemini-2.5-Flash was used for document segmentation, and GPT-4.1 was used to extract problems and solutions into LaTeX friendly formats.
- Verification: Extracted pairs underwent a rigorous three tier validation process involving a rule based analytical checker, GPT-4.1 visual inspection of source screenshots, and manual human review. A pair was only retained if all three mechanisms reached a unanimous agreement.
- Metadata Construction: The pipeline captures detailed provenance for each entry, including country, competition name, year, and author notes.
Usage and Evaluation Tasks
The authors use the data to benchmark models across three distinct mathematical tasks:
- Problem Solving: Evaluating generative models by comparing their generated solutions against the expert reference solutions in MathNet-Solve.
- Math-Aware Retrieval: Testing embedding based systems on their ability to identify mathematically equivalent problems in MathNet-Retrieve, moving beyond simple lexical overlap.
- Retrieval-Augmented Problem Solving (RAG): Assessing how retrieval quality impacts reasoning performance using the expert paired problems in MathNet-RAG.
Method
The authors propose a comprehensive pipeline designed to transform raw mathematical documents into high-quality, structured datasets suitable for training and evaluating large language models. The overall workflow begins with the ingestion of diverse source materials, which include over 30,000 Olympiad-level problems spanning more than 40 countries and four decades of mathematical history.
As shown in the figure below:
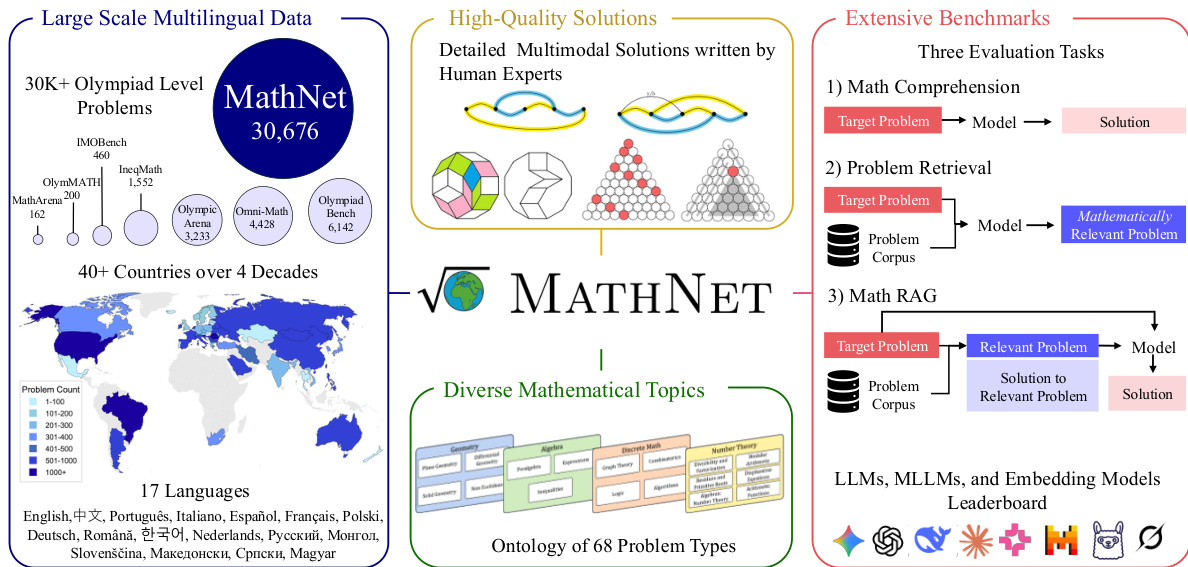
The system processes input booklets through a multi-stage extraction and segmentation pipeline. Initially, PDF files undergo text extraction using DotsOCR, while page screenshots are captured to preserve visual information. These components are then converted into Markdown format. The core of the processing engine involves document segmentation, where the text is partitioned into discrete problem and solution blocks. This segmentation is supported by a specialized module that performs structural parsing, boundary detection, and problem-solution alignment to ensure that each mathematical challenge is correctly paired with its corresponding rigorous proof or answer.
Following segmentation, the system employs GPT-4.1 for format normalization, ensuring that the extracted content adheres to a consistent structure. This is followed by a semantic metadata extraction phase, which categorizes problems by topic, difficulty, and type. To maintain the highest possible data integrity, the pipeline incorporates a human verification step. The final stage involves a rule-based source consistency check and a cross-verification and deduplication process, resulting in a curated dataset of high-quality, human-verified mathematical problem-solution pairs.
The resulting dataset supports three primary evaluation tasks: math comprehension, problem retrieval, and Math RAG (Retrieval-Augmented Generation). This structured approach allows for the rigorous benchmarking of LLMs, MLLMs, and embedding models against complex mathematical reasoning tasks.
Experiment
The MATHNET evaluation assesses model capabilities across three distinct tasks: direct problem solving, math-aware retrieval of equivalent problems, and retrieval-augmented problem solving. While frontier reasoning models demonstrate impressive performance in solving complex mathematical problems, current embedding models struggle significantly with math-aware retrieval due to a reliance on superficial lexical overlap rather than deep structural understanding. Consequently, retrieval-augmented generation only provides consistent improvements when the retrieved context is mathematically and structurally aligned with the target problem.
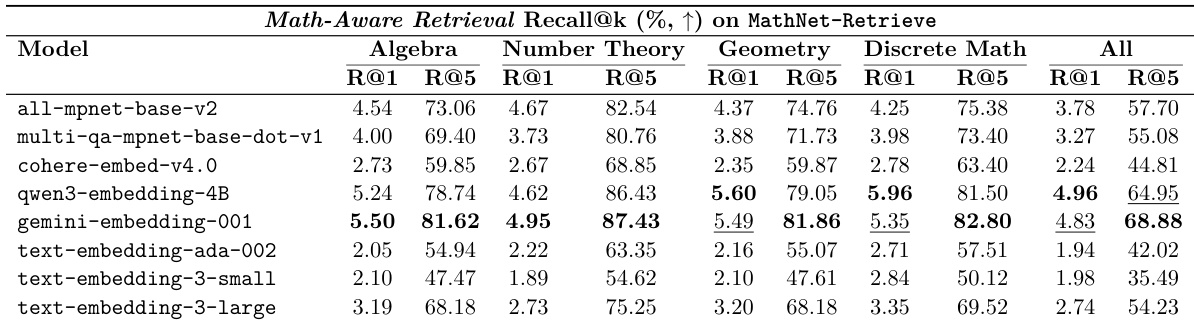
The authors evaluate various embedding models on the MathNet-Retrieve benchmark to assess their ability to perform math-aware retrieval across different mathematical domains. Results show that while retrieval accuracy is generally low at the top-1 level, performance improves significantly as the number of retrieved candidates increases. Gemini-embedding-001 achieves the highest overall performance for both Recall@1 and Recall@5 across all domains. Retrieval accuracy is consistently higher at the Recall@5 level compared to the Recall@1 level across all tested models and subjects. Legacy text embedding models generally demonstrate lower retrieval performance compared to newer specialized or larger embedding models.
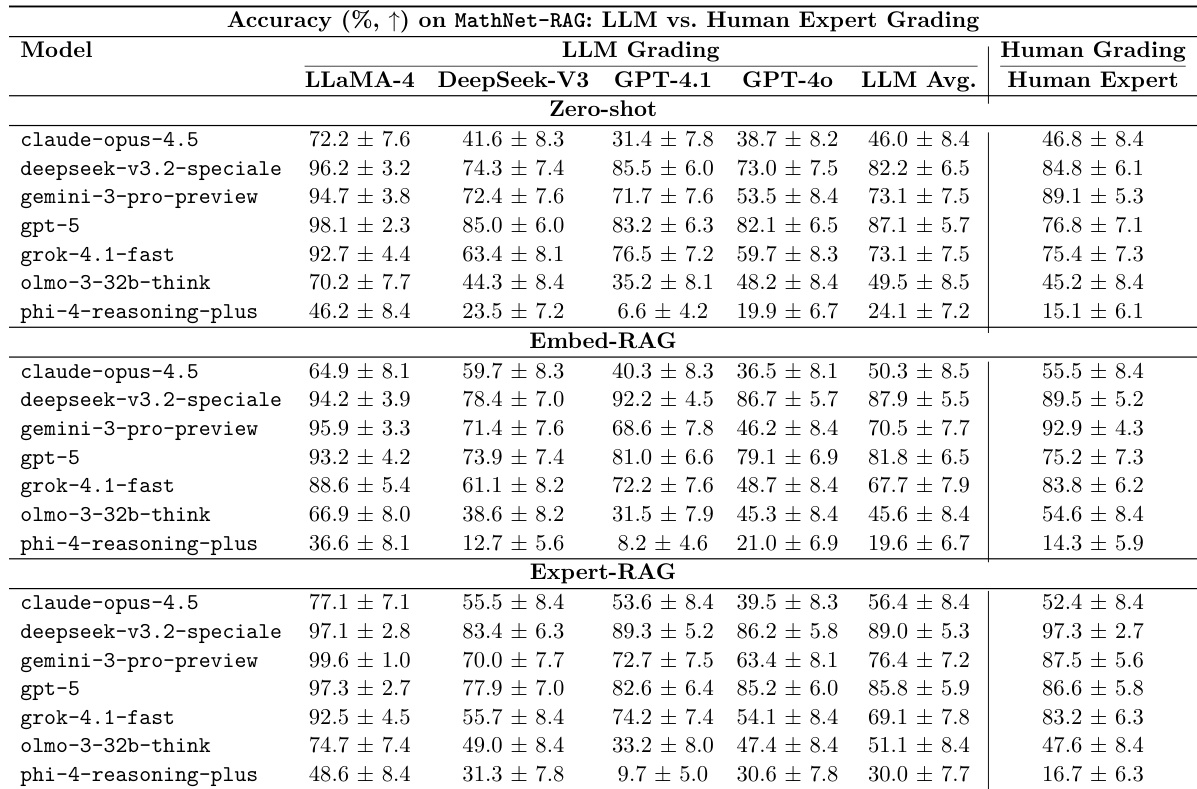
The authors evaluate the impact of retrieval-augmented generation on mathematical problem solving using both human and LLM grading. Results show that providing expert-curated, structurally similar problems as context generally improves performance compared to zero-shot settings. Expert-RAG consistently yields the highest accuracy under human grading across most evaluated models Retrieval-based augmentation provides significant performance gains for mid-tier models compared to zero-shot baselines LLM grading results broadly align with human expert assessments regarding model performance trends
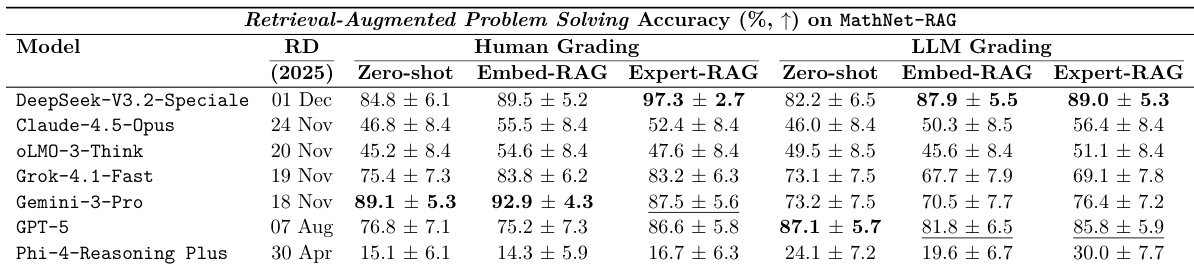
The authors evaluate the impact of retrieval-augmented generation on mathematical problem solving using human and LLM grading. Results show that providing ground-truth related problems through expert-RAG consistently improves performance compared to zero-shot settings. Expert-RAG provides the most significant and consistent performance gains across most models Embedding-based retrieval results show high variance and can sometimes lead to performance degradation The performance boost from retrieval is particularly notable for lower and mid-tier solvers
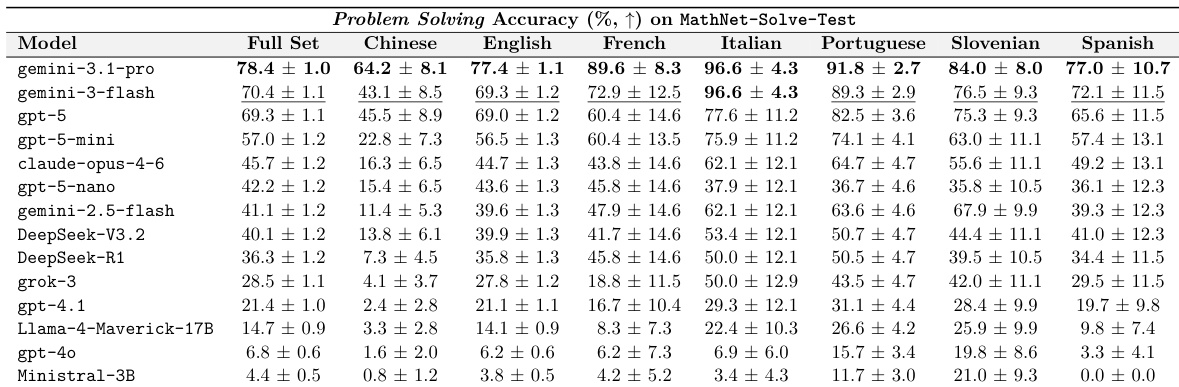
The authors evaluate the problem solving accuracy of various models on the MathNet-Solve-Test dataset across multiple languages. Results show that frontier reasoning models achieve the highest overall performance, while performance varies significantly depending on the specific language used. Frontier models like gemini-3.1-pro demonstrate the highest overall accuracy compared to other tested systems Model performance is notably higher on certain languages such as Italian and Portuguese compared to others like Chinese There is a substantial performance gap between state of the art reasoning models and smaller or earlier generation models
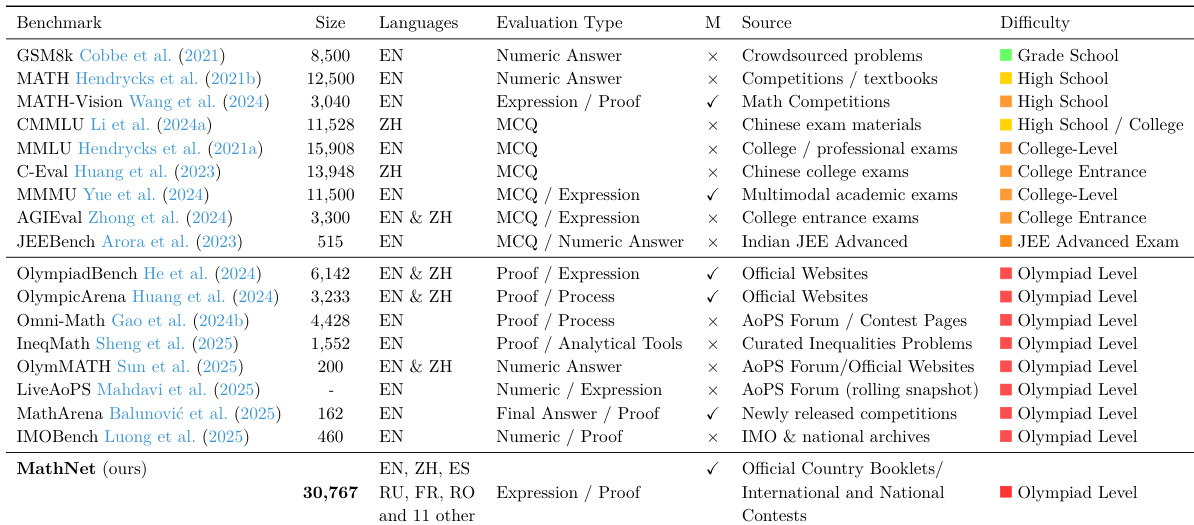
The authors compare MathNet against several existing mathematical reasoning benchmarks across various dimensions including size, language coverage, and difficulty. MathNet distinguishes itself by offering a larger scale and broader multilingual support compared to the surveyed datasets. MathNet provides significantly larger scale and more extensive language support than existing benchmarks While most existing benchmarks focus on grade school or high school levels, MathNet focuses on Olympiad level difficulty MathNet utilizes expression and proof based evaluation types to assess mathematical reasoning
The authors evaluate the MathNet benchmark by assessing embedding model retrieval capabilities, the effectiveness of retrieval-augmented generation (RAG) on problem-solving accuracy, and the performance of various reasoning models across multiple languages. The results demonstrate that specialized embedding models and expert-curated RAG significantly enhance mathematical reasoning, particularly for mid-tier models, while frontier reasoning models maintain a substantial performance lead across diverse linguistic contexts. Ultimately, MathNet distinguishes itself from existing benchmarks by providing a larger scale, broader multilingual support, and higher difficulty levels focused on Olympiad-level mathematical reasoning.