Command Palette
Search for a command to run...
Autoreason: Self-Refinement That Knows When to Stop
Autoreason: Self-Refinement That Knows When to Stop
Abstract
Iterative self-refinement fails for three reasons: prompt bias, where adversarial critique prompts cause models to hallucinate problems that don't exist; scope creep, where each revision pass expands the document's scope unchecked; and lack of restraint: models almost never decline to make changes, even when the output is already good. Together these guarantee progressive degradation. We present autoreason, which addresses all three by structuring each iteration as a three-way choice: the unchanged incumbent (A), an adversarial revision (B), and a synthesis (AB). Fresh agents with no prompt history or session context judge the candidates via blind Borda count, ensuring that "do nothing" is always a first-class option, and the evaluators share none of the biases that produced the revisions. The method's value is greatest at mid-tier models, where the gap between generation capability and self-evaluation capability is widest. With Haiku 3.5 (∼10× cheaper than Sonnet 4), autoreason scored 42/42 Borda across three tasks, a perfect sweep, while standard refinement baselines degraded the same model's outputs below its unrefined single pass. Across five model tiers (Llama 8B, Gemini Flash, Haiku 3.5, Haiku 4.5, Sonnet 4), the advantage peaks at mid-tier and diminishes at both extremes: models too weak to generate diverse alternatives (Llama) or too strong to need external evaluation (Sonnet 4.6). Haiku 4.5 confirms the transition: at 60% private-test accuracy on code (matching Sonnet single-pass), autoreason's gains on held-out tests vanish entirely, despite a 4pp lift on visible tests.
One-sentence Summary
The authors propose Autoreason, a self-refinement framework that mitigates prompt bias, scope creep, and lack of restraint by structuring each iteration as a three-way choice between the unchanged incumbent, an adversarial revision, and a synthesis, evaluated via blind Borda count by independent agents to enable models to stop refining when outputs are optimal.
Key Contributions
- The paper introduces autoreason, a method that structures iterative refinement as a three-way choice between an unchanged incumbent, an adversarial revision, and a synthesis of both.
- This approach utilizes fresh agents with no prior prompt history or session context to judge candidates via a blind Borda count, which prevents the biases and scope creep common in standard self-refinement.
- Experimental results demonstrate that autoreason achieves a perfect Borda score of 42/42 on three tasks using Haiku 3.5, significantly outperforming standard refinement baselines that cause output degradation.
Introduction
Iterative self-refinement is a common technique used to improve large language model outputs, but it often suffers from progressive degradation due to prompt bias, uncontrolled scope creep, and a lack of restraint where models feel compelled to change even perfect outputs. Existing methods frequently fail because they rely on single-agent loops or lack mechanisms to allow a model to opt for no change at all. The authors leverage a structured three-way choice framework called autoreason to solve these issues. By presenting an unchanged incumbent, an adversarial revision, and a synthesis to independent judges using a blind Borda count, the method ensures that "doing nothing" remains a viable option. This approach is particularly effective for mid-tier models that possess the ability to generate diverse alternatives but lack the self-evaluation capability to select the best one.
Method
The authors leverage a structured iterative framework known as autoreason, which operates as a closed-loop system driven by three distinct agent roles: Critic, Author, and Synthesizer, all operating within an iteration loop. The process begins with a Task Prompt that initializes the incumbent document, denoted as A. At each pass, a fresh Critic agent evaluates the current incumbent A and generates a critique, identifying shortcomings without proposing solutions. This critique is then passed to a fresh Author agent, which revises the incumbent to produce a new adversarial revision, labeled B. Simultaneously, a fresh Synthesizer agent combines the original incumbent A and the adversarial revision B to create a synthesized candidate, AB, by integrating the strongest elements from both.
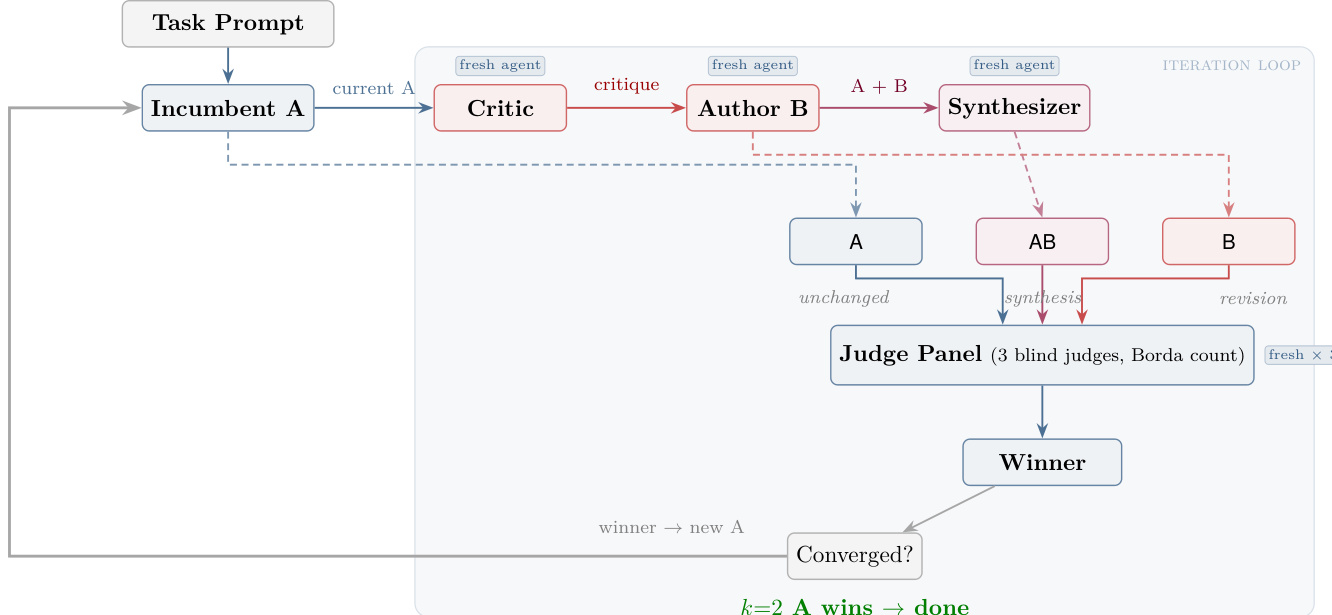
As shown in the figure below, the three candidates—A (unchanged incumbent), AB (synthesis), and B (revision)—are submitted to a Judge Panel composed of three blind judges. The judges rank the candidates using a Borda count system, assigning 3, 2, and 1 points for first, second, and third place, respectively, with ties broken in favor of the incumbent. The winner is selected based on the aggregated scores, and the process continues unless the incumbent A wins two consecutive passes, which triggers convergence.
The framework ensures that each agent role is a fresh, isolated instance with no shared context beyond the task prompt, promoting independence and reducing bias propagation. The iterative process is formally defined where dt represents the incumbent document at pass t, and each pass generates candidates {dt,B(dt),S(dt,B(dt))}, where B is the adversarial revision operator and S is the synthesis operator. The winner at each step is determined by maximizing the Borda aggregation score over n judges, expressed as:
dt+1=argc∈{A,B,AB}maxi=1∑n(3−ri(c))where ri(c) is the rank assigned to candidate c by judge i. The system converges when the incumbent wins k=2 consecutive passes, ensuring stability in the output.
Experiment
The experiments evaluate the autoreason method across subjective writing tasks, competitive programming, and various model tiers to determine when structured iterative refinement succeeds. The results demonstrate that autoreason effectively bridges the gap between a model's generation and evaluation capabilities, particularly for mid-tier models where traditional self-refinement often leads to quality degradation or unchecked verbosity. Ultimately, the study concludes that the method's effectiveness is maximized when tasks provide sufficient decision space and bounded scope, allowing a tournament structure to recover from initial failures through structured reasoning rather than mere reactive editing.
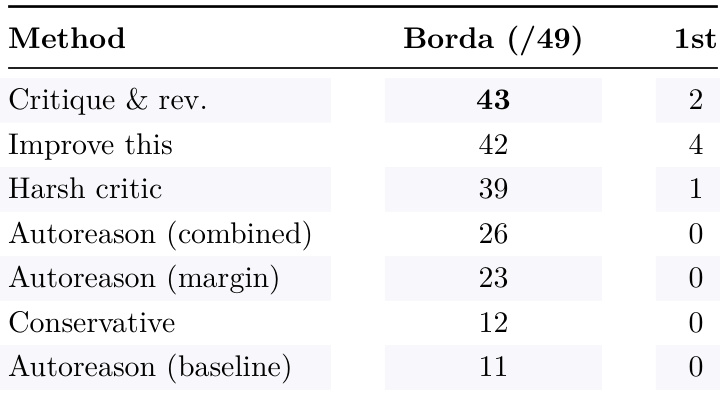
The authors compare autoreason variants against baseline methods, showing that autoreason with a margin requirement achieves higher Borda scores than other approaches. The critique-and-revise method leads in first-place rankings, but autoreason variants demonstrate improved overall performance through structured evaluation. Autoreason with a margin requirement achieves higher Borda scores than other methods Critique-and-revise leads in first-place rankings but autoreason variants show better overall performance Autoreason variants outperform conservative and baseline methods in Borda scoring
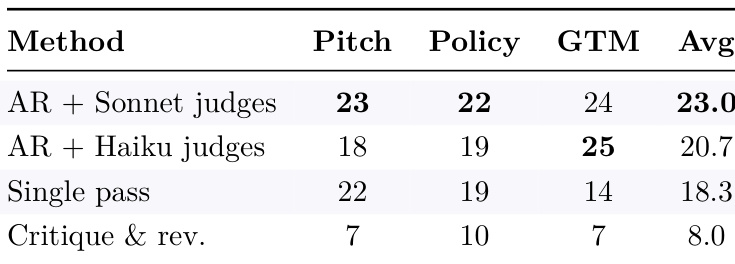
Autoreason achieves higher scores across multiple tasks compared to single-pass and critique-and-revise methods. The method's advantage is consistent, with significant gains in average performance over simpler iterative approaches. Autoreason outperforms single-pass and critique-and-revise baselines across all tasks The method achieves higher average scores compared to all other approaches Autoreason shows consistent superiority in both constrained and open-ended tasks
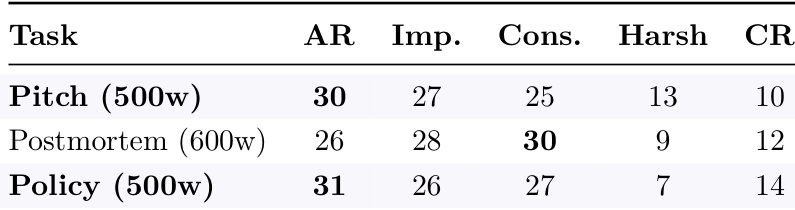
The the the table compares the performance of autoreason against baseline methods on constrained writing tasks. Autoreason achieves the highest scores on two out of three tasks, with the conservative baseline performing best on the postmortem task, indicating that task constraints influence which method is most effective. Autoreason outperforms baselines on two of three constrained tasks The conservative baseline wins on the postmortem task, suggesting task-specific effectiveness Performance differences highlight the impact of task constraints on method success
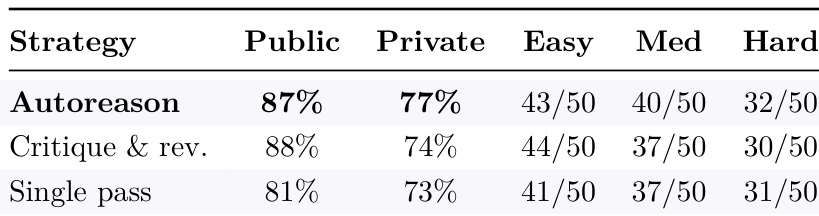
Autoreason achieves higher private-test pass rates and better performance on medium and hard problems compared to critique-and-revise and single-pass strategies. The method shows consistent gains across difficulty levels, particularly in constrained domains where iterative refinement without evaluation leads to degradation. Autoreason leads in private-test pass rates across all problem types The method outperforms critique-and-revise and single-pass strategies on medium and hard problems Autoreason maintains higher performance on difficult problems where baselines degrade
The the the table compares convergence speed across different judge variants for two tasks. Chain-of-thought judges converge significantly faster than baseline holistic judges, while decomposed specialists show intermediate performance on Task 1 but no convergence on Task 2. This suggests that structured reasoning improves evaluation efficiency, but specialized roles may not always be effective. Chain-of-thought judges converge faster than baseline holistic judges Decomposed specialist judges converge on Task 1 but fail to converge on Task 2 Structured reasoning improves convergence speed, but specialized roles may not be universally effective

The experiments compare various autoreason variants against single-pass, critique-and-revise, and conservative baseline methods across constrained, open-ended, and varying difficulty tasks. The results demonstrate that autoreason variants provide superior overall performance and consistency, particularly on difficult problems where simpler iterative approaches often degrade. While structured reasoning through chain-of-thought judges improves evaluation convergence speed, the effectiveness of specialized roles varies depending on the specific task requirements.