Command Palette
Search for a command to run...
KaLM-Reranker-V1: Fast but Not Late Interaction for Compressed Document Reranking
KaLM-Reranker-V1: Fast but Not Late Interaction for Compressed Document Reranking
Xinping Zhao Jiaxin Xu Ziqi Dai Xin Zhang Shouzheng Huang Danyu Tang Xinshuo Hu Meishan Zhang Baotian Hu Min Zhang
Abstract
As retrieval systems scale, high-quality reranking becomes increasingly important. However, most existing rerankers, whether encoder-based or decoder-based, jointly encode the query and passage, tightly coupling their computation and limiting deployment efficiency as well as flexibility. We present KaLM-Reranker-V1, a fast but not late-interaction (FBNL) reranker that decouples query and passage computation while retaining expressive relevance modeling. Built on an encoder-decoder architecture, KaLM-Reranker-V1 uses the encoder to pre-encode passages with Matryoshka embedding pooling, while the decoder models the system instruction, user instruction, and query intent; cross-attention then captures relevance between the query context and passage representations. This design makes KaLM-Reranker-V1 efficient through decoupled passage encoding, yet not late interaction, by preserving rich relevance modeling through cross-attention. We instantiate KaLM-Reranker-V1 in three sizes, Nano, Small, and Large, with 0.27B, 1B, and 4B activated parameters, respectively. Extensive experiments on BEIR, MIRACL, and LMEB demonstrate that KaLM-Reranker-V1 achieves strong reranking performance with superior efficiency. On BEIR, KaLM-Reranker-V1 achieves state-of-the-art performance, on par with strong industrial models such as the Qwen3-Reranker series; on MIRACL, despite not being extensively trained on multilingual data, KaLM-Reranker-V1 still shows excellent reranking performance. Moreover, on LMEB, reranking models demonstrate a clear advantage, with even the 0.27B Nano model remaining competitive with 7-12B embedding models.
One-sentence Summary
KaLM-Reranker-V1 is an encoder-decoder reranker that decouples passage and query computation through Matryoshka embedding pooling and cross-attention to retain expressive relevance modeling, with evaluations on BEIR, MIRACL, and LMEB demonstrating its strong reranking performance and superior efficiency.
Key Contributions
- KaLM-Reranker-V1 is introduced as a fast but not late-interaction reranker that decouples query and passage computation to overcome the efficiency bottlenecks of jointly encoded architectures. The encoder-decoder design pre-encodes passages via Matryoshka embedding pooling while a decoder processes system and user instructions alongside query intent, with cross-attention layers preserving expressive relevance modeling.
- The model is instantiated in three scalable variants, Nano, Small, and Large, containing 0.27B, 1B, and 4B activated parameters respectively.
- Extensive evaluations on the BEIR, MIRACL, and LMEB benchmarks demonstrate that the decoupled architecture achieves strong reranking performance alongside superior computational efficiency.
Introduction
Document reranking is essential for modern search and retrieval-augmented generation systems, as accurately ordering candidate passages directly determines downstream relevance and user experience. However, existing late interaction models compute fine-grained token alignments that create severe computational bottlenecks, particularly when processing compressed or lengthy documents. The authors leverage a streamlined architecture that eliminates late interaction mechanisms to drastically reduce inference latency. By integrating optimized context compression with a lightweight scoring framework, KaLM-Reranker-V1 delivers rapid document reordering while preserving strong relevance signals, enabling scalable deployment in production retrieval pipelines.
Dataset

- Dataset Composition and Sources: The authors compile a multilingual and multi-domain retrieval dataset designed to improve cross-domain robustness. The data covers web search, question answering, duplicate-question retrieval, and fact verification, and is drawn from two public repositories: the retrieval subset of the KaLM embedding fine-tuning data and a curated selection from the BGE-M3 training corpus.
- Subset Details and Size: While the paper does not provide exact breakdowns per source, the combined preprocessed dataset contains approximately 3.7 million training samples. Detailed statistics and source-specific metrics are documented in the supplementary tables.
- Model Usage and Training Configuration: The authors use the final dataset exclusively for supervised fine-tuning to develop the reranking capabilities of KaLM-Reranker-V1. The data is prepared as a unified training corpus without explicitly mentioned validation or test splits in this section.
- Processing and Sampling Strategy: To address the common limitation of query-positive pair formats, the team constructs full reranking instances through a structured hard negative mining pipeline. For each query, they use KaLM-Embedding-V2.5 to retrieve the top 100 candidate passages from the corresponding corpus. They then sample exactly 16 hard negatives strictly from ranks 10 through 50. This specific range encourages the model to learn fine-grained distinctions, avoids trivially easy low-ranked results, and minimizes the risk of accidentally selecting true positives from the highest-ranked candidates.
Method
The authors introduce KaLM-Reranker-V1, a reranking model built on a fast but not late-interaction (FBNL) paradigm. The architecture decouples query and passage computation to enhance efficiency while preserving expressive relevance modeling. As shown in the framework diagram below:

The model consists of an encoder dedicated to processing candidate documents and a decoder responsible for modeling the query and instruction context. The encoder maps a candidate document p into a reusable hidden representation Hd=Enc(p)∈Rn×d, where n is the sequence length and d is the hidden dimension. This allows the passage representation to be precomputed and cached offline. The decoder takes the task instruction I and user query q as input, forming the decoder input X∈Rm×d. To capture fine-grained relevance, the decoder computes cross-attention by forming queries from X and keys and values from the concatenation of X and the encoded passage Hd. The attention mechanism is defined as:
Q=XWQ,K=[X;Hd]WK,V=[X;Hd]WV O=softmax(dhQK⊤+M)VWOwhere M is a causal mask. The language model head then projects the representation at the first prediction position into vocabulary logits. The relevance score is derived by comparing the likelihood of generating the tokens "yes" versus "no":
score(q,p)=exp(zyes)+exp(zno)exp(zyes)To mitigate the storage overhead of caching full passage representations, the authors incorporate Matryoshka Embedding Pooling (MEP). This technique compresses the passage representations along the sequence dimension by grouping consecutive tokens and applying mean pooling. For a compression ratio r, the compressed representation becomes Hp(r)∈R⌈n/r⌉×d. The model is trained across a set of compression ratios R, optimizing a combined supervised fine-tuning loss to ensure the representations remain effective under varying degrees of compression.
The training follows a progressive multi-stage pipeline designed to gradually adapt the base model to reranking tasks. As illustrated in the training pipeline below:

The process begins with general reranking ability learning, where the model is trained without explicit task instructions to establish a domain-agnostic relevance foundation. The second stage introduces task-specific instructions and continues supervised fine-tuning on high-quality data, allowing the model to adapt its scoring behavior to specific search intents. The final stage employs fine-grained relevance distillation, where a stronger teacher reranker provides soft labels. The student model optimizes a binary cross-entropy loss against these soft targets:
Lkd=−ylogy^−(1−y)log(1−y^)This distillation step refines the model's discriminative ability, particularly for hard negatives and borderline relevance cases, resulting in the final KaLM-Reranker-V1 variants.
Experiment
The evaluation employs a standardized two-stage retrieval pipeline across BEIR, MIRACL, and LMEB benchmarks to assess cross-domain generalization, multilingual robustness, and long-horizon memory retrieval capabilities. Time complexity analysis validates that offline passage encoding and Matryoshka compression drastically reduce online serving overhead while preserving strong relevance modeling, particularly for longer contexts. Compression and scaling experiments further demonstrate that moderate compression ratios offer the optimal efficiency-accuracy trade-off, with larger models exhibiting greater resilience to information loss. Ultimately, the results confirm that the proposed encoder-decoder paradigm delivers highly competitive reranking performance and significantly enhances complex and memory-based retrieval tasks compared to scaling standalone embedding models.
The authors evaluate embedding models on dialogue memory retrieval benchmarks to compare their effectiveness against a retrieve-then-rerank pipeline. The results demonstrate that a pipeline utilizing smaller models achieves better average performance than the largest embedding models, indicating that simply scaling up embedding models is less effective. Among the embedding models compared, the second-largest model achieves the highest average score, while the largest model performs lower. A retrieve-then-rerank pipeline with smaller models outperforms the largest embedding models in average performance. Scaling up the size of embedding models does not consistently lead to improved results on memory benchmarks. The second-largest embedding model achieves the best average performance among the compared embedding models.

The authors evaluate the KaLM-Reranker-V1 series against competitive baselines on the MIRACL benchmark across 18 languages. The results demonstrate that the proposed models achieve superior or comparable reranking performance while significantly reducing online computational costs. This indicates that the KaLM-Reranker-V1 architecture offers a highly efficient solution for multilingual retrieval tasks without sacrificing accuracy. KaLM-Reranker-V1-Large achieves the best average performance in its size category, surpassing baselines like bge-reranker-v2-gemma while maintaining lower computational costs. Compact models like KaLM-Reranker-V1-Nano provide highly efficient reranking with significantly lower overhead than larger baselines, yet achieve competitive accuracy. KaLM-Reranker-V1-Large secures top scores across numerous individual languages, demonstrating strong multilingual capabilities despite limited training data.
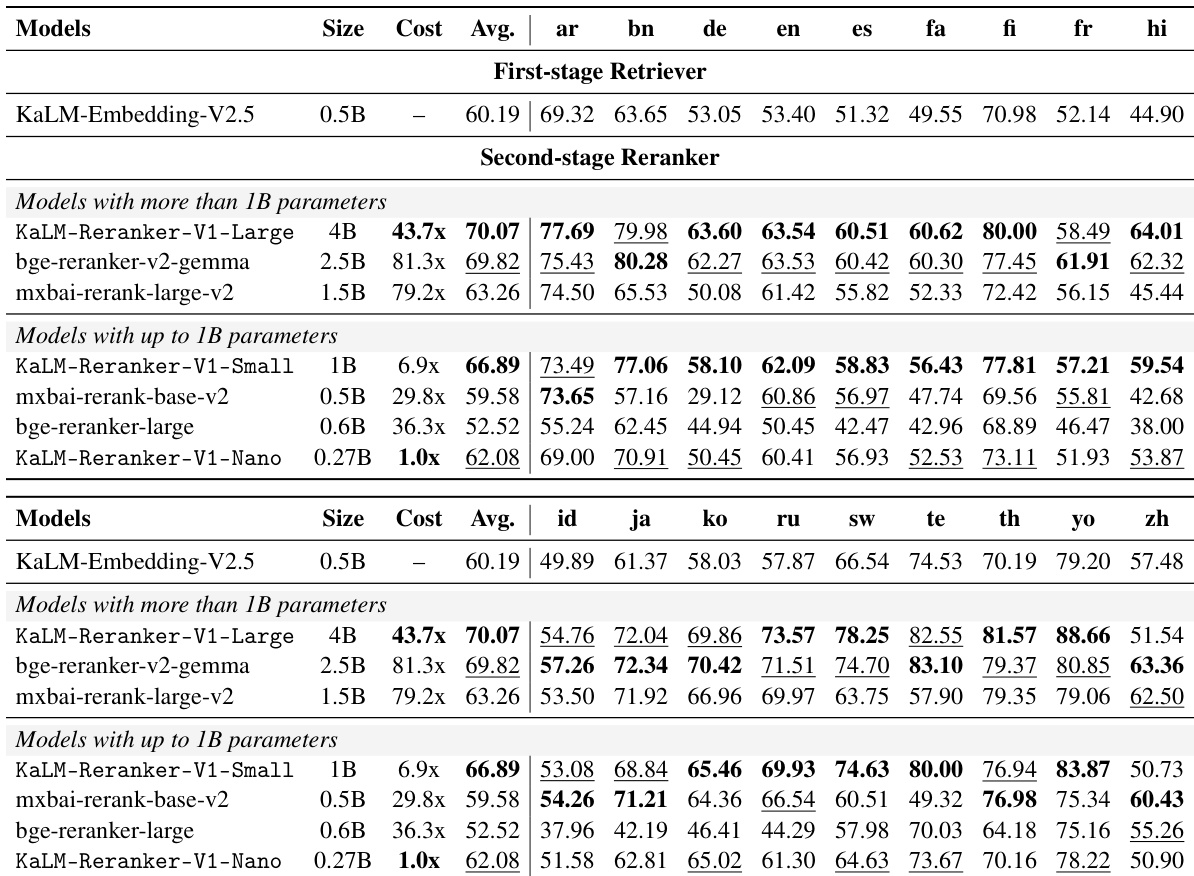
The authors evaluate the KaLM-Reranker-V1 series against various open-source rerankers across multiple retrieval benchmarks, including memory retrieval tasks. The results demonstrate that the proposed models achieve competitive performance relative to larger baselines while significantly reducing online computation costs. The study highlights the efficiency of the proposed architecture and the benefits of a retrieve-then-rerank pipeline over simply scaling embedding models. KaLM-Reranker-V1 models achieve performance comparable to larger industrial rerankers like Qwen3 and bge, often with substantially lower online computation costs. The retrieve-then-rerank pipeline using the Nano model outperforms scaling up the embedding model alone, demonstrating the value of specialized reranking. The models demonstrate strong capabilities in memory retrieval tasks, with the reranker significantly boosting the performance of the initial retriever.
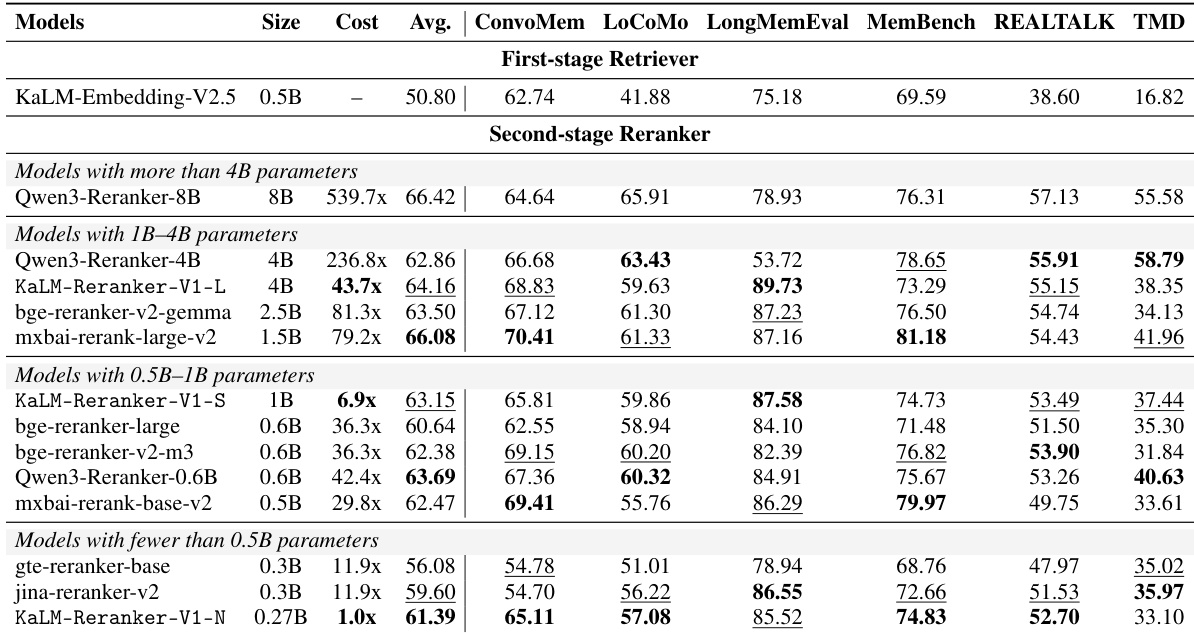
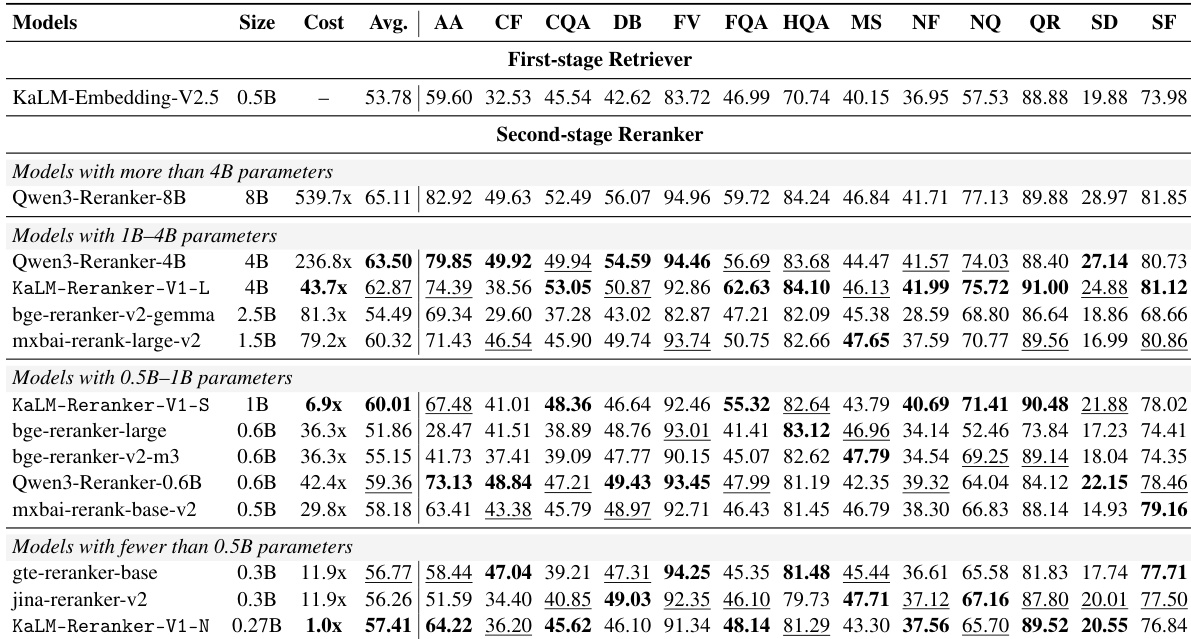
The the the table compares the reranking performance of the KaLM-Reranker-V1 series against various open-source models on the BEIR benchmark. The results indicate that KaLM-Reranker-V1 achieves competitive accuracy across diverse tasks while significantly reducing online computation costs compared to larger baselines. Smaller variants of the model maintain high efficiency, often outperforming larger models with much lower resource requirements. KaLM-Reranker-V1-Large achieves top-tier performance on the majority of tasks, matching the effectiveness of significantly larger models. The Small variant delivers strong average results with a substantially lower relative cost than comparable competitors like Qwen3-Reranker-0.6B. The Nano model provides a highly efficient solution, maintaining competitive accuracy while requiring the least online computation resources.
The authors present the architectural details for three variants of the KaLM-Reranker-V1 model, which scale in size from a compact version to a large-scale configuration. These models are designed to handle long sequence lengths and support flexible compression through Matryoshka Embedding Pooling. The parameter distribution reveals that non-embedding components constitute the majority of the model size, with the largest variant having the highest dimensionality and layer count. Model size scales up significantly, accompanied by an increase in the number of layers and hidden dimensions. All variants support instruction awareness and flexible compression ratios for passage representations. Non-embedding parameters dominate the total parameter count, especially in the larger model configurations.

The experiments evaluate embedding models and the KaLM-Reranker-V1 series across dialogue memory, multilingual, and general retrieval benchmarks to validate the impact of model scaling versus pipeline architecture on retrieval performance. The findings demonstrate that scaling embedding models alone yields inconsistent improvements, whereas a retrieve-then-rerank approach with smaller models consistently delivers superior results. Additionally, the KaLM-Reranker-V1 variants confirm that targeted architectural optimizations enable smaller models to match larger baselines in accuracy while significantly reducing computational overhead, highlighting the practical advantages of efficient reranking pipelines.