Command Palette
Search for a command to run...
BrainG3N: A Dual-Purpose Tokenizer for Controllable 3D Brain MRI Generation
BrainG3N: A Dual-Purpose Tokenizer for Controllable 3D Brain MRI Generation
Max Van Puyvelde Ibrahim Gulluk Wim Van Criekinge Olivier Gevaert
Abstract
Three-dimensional (3D) brain MRI is central to clinical neurology and neuro-oncology, where generative models could augment under-represented cohorts, simulate disease trajectories, and support privacy-preserving data sharing. Latent diffusion has been the go-to solution for modeling imaging data, but it places two competing demands on the tokenizer: encoder embeddings must retain the clinical information that downstream tasks act on, and the decoder must reconstruct anatomically faithful volumes. Existing reconstruction-driven tokenizers achieve the second at the expense of the first. To address this, we introduce a fully volumetric masked-autoencoder (MAE) based tokenizer for 3D brain MRI latent diffusion, decoupling encoder and decoder: a frozen 3D MAE encoder produces clinically informative embeddings, while a dedicated CNN decoder reconstructs voxels from a linear projection of those embeddings. We pretrain the encoder on 35,309 volumes from 18 public cohorts spanning four modalities, ten disease categories, and 200+ acquisition sites, and demonstrate its dual utility in two settings. First, on a 23-task linear-probing benchmark, the encoder outperforms or matches SOTA models (i.e., BrainIAC, BrainSegFounder, and MedicalNet) on 21 of 23 tasks. Second, a conditional diffusion transformer (DiT) trained on these clinically informative embeddings supports both conditional generation across six variables and patient-specific longitudinal forecasting. Together these results establish a single 3D brain-MRI embedding space capable of both downstream clinical tasks and controllable generation.
One-sentence Summary
BrainG3N, a dual-purpose tokenizer for controllable 3D brain MRI generation, decouples a frozen 3D masked-autoencoder encoder that yields clinically informative embeddings from a dedicated CNN decoder that reconstructs anatomically faithful volumes, and after pretraining the encoder on 35,309 volumes from 18 public cohorts spanning four modalities, ten disease categories, and over 200 acquisition sites, it outperforms or matches state-of-the-art models on 21 of 23 linear-probing tasks.
Key Contributions
- A fully volumetric MAE-CNN tokenizer for 3D brain MRI decouples a frozen 3D MAE encoder from a dedicated CNN decoder, producing clinically informative embeddings while reconstructing voxels from a linear projection of those embeddings.
- Pretrained on 35,309 volumes spanning four modalities and ten disease categories, the frozen MAE encoder outperforms or matches published 3D brain‑MRI foundation models on 21 of 23 linear‑probing tasks, including IDH1 mutation, APOE genotype, and cognitive scores.
- A conditional flow‑matching diffusion transformer trained on the frozen embeddings enables controllable 3D brain‑MRI generation, with real‑data linear probes recovering requested conditions under classifier‑free guidance and longitudinal age progression captured at a Pearson correlation of 0.72.
Introduction
Three-dimensional brain MRI underpins clinical decisions in neurology and neuro-oncology, yet direct generation of full-resolution volumes for tasks like data augmentation, patient-specific digital twins, or privacy-preserving sharing is computationally infeasible. Existing latent diffusion models compress imaging with an autoencoder trained purely on reconstruction, which biases the latent space toward voxel-level fidelity and discards clinically meaningful semantics needed for conditional synthesis or downstream analysis. The authors address this with a dual-purpose tokenizer: a frozen masked-autoencoder (MAE) pretrained on 35,309 brain MRI volumes from 18 cohorts produces embeddings that are both strongly predictive of clinical phenotypes and serve as the feature space for a conditional diffusion transformer. Paired with a dedicated convolutional decoder for faithful voxel reconstruction, the frozen encoder matches or outperforms three published 3D brain-MRI foundation models on 21 of 23 linear-probing benchmarks, and the diffusion model achieves controllable generation across six clinical variables and patient-specific longitudinal forecasting, bridging the gap between diagnostic content and generative fidelity in large-scale 3D medical imaging.
Dataset
The authors construct the dataset by aggregating 35,309 preprocessed brain MRI volumes from 17,399 unique subjects across 18 public cohorts and over 200 acquisition sites worldwide. It spans four modalities (T1, T2, FLAIR, T1c) and an age range of 5 to 98 years, with longitudinal imaging available for 6,576 subjects.
Key details per component:
- Diagnosis subsets and sizes: Healthy control (HC) 15,274, mild cognitive impairment (MCI) 5,808, glioblastoma (GBM) 4,028, Parkinson’s disease (PD) 3,381, paediatric-mixed 2,130, Alzheimer’s disease (AD) 1,458, autism spectrum disorder (ASD) 1,061, non-GBM glioma 396, schizophrenia (SCZ) 328, ADHD 247. Healthy subjects dominate at 43% by design, offering a large null distribution for probing and generative modeling.
- Clinical metadata: age-at-scan (90% coverage), sex (90%), diagnosis (96%), CDR (34%, concentrated in AD/MCI), MMSE (41%, AD/MCI), MoCA (18%), APOE genotype (41%), tumor grade (8% of tumor cohorts), IDH1 (7%), MGMT (6%), and acquisition site (78%).
Preprocessing and cropping strategy:
- Harmonized pipeline applied to all volumes: N4 bias-field correction, HD-BET skull stripping, affine registration to the SRI24 atlas (240×240×155 voxels, 1 mm isotropic, LPS orientation). In multi-modality settings, T2, FLAIR, and T1c are co-registered through the T1 transform to prevent cross-modal alignment drift.
- Negative voxels from interpolation are clipped to zero. No intensity normalization is performed at this stage.
- For model input, volumes are center-cropped or padded to 160×192×160. Per-volume z-scoring happens on the fly in the training data loader.
How the paper uses the data:
- The full corpus serves as training material for the generative model and for probing benchmarks. The heavy healthy-control presence (43%) supports probing tasks that disentangle disease signal from normal variability and ensures the generative model learns a thorough null distribution. The dataset card does not describe an explicit train/validation/test split; all volumes are used in self-supervised pretraining and downstream evaluation.
Method
Theauthors introduce a fully volumetric masked-autoencoder (MAE) based tokenizer for 3D brain MRI latent diffusion. The core design decouples the encoder and decoder to satisfy two competing demands: retaining clinical information in encoder embeddings and achieving anatomically faithful volume reconstruction. This is achieved through a two-stage training process for the tokenizer, followed by the training of a conditional diffusion model.
As shown in the figure below:
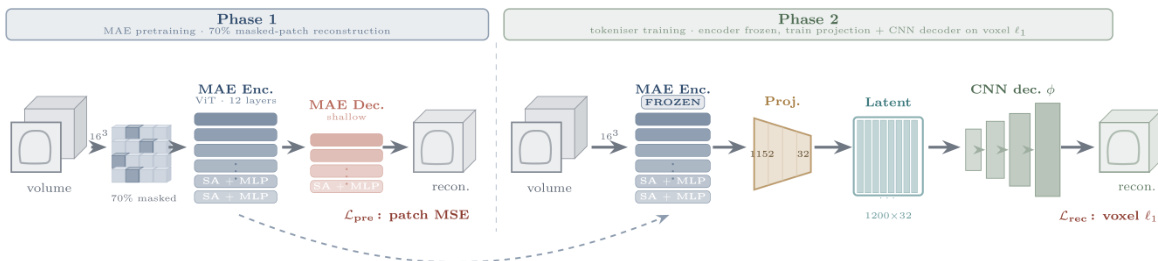
In Phase 1, the authors perform MAE pretraining on a large dataset of volumes. The architecture utilizes a Vision Transformer (ViT) with 12 layers as the MAE encoder and a shallow decoder. The input volume is divided into 163 patches, with 70% of the patches masked. The model is trained to reconstruct the masked patches using a patch Mean Squared Error (MSE) loss, denoted as Lpre.
In Phase 2, the tokenizer training proceeds with the MAE encoder frozen. A linear projection layer maps the encoder embeddings to a latent space of dimension 1200×32. A dedicated Convolutional Neural Network (CNN) decoder, denoted as ϕ, is then trained to reconstruct the voxels from this latent representation. The reconstruction is optimized using a voxel ℓ1 loss, Lrec.
To support conditional generation across multiple variables and patient-specific longitudinal forecasting, the authors train a conditional Diffusion Transformer (DiT) on the clinically informative embeddings produced by the frozen encoder.
Refer to the framework diagram:
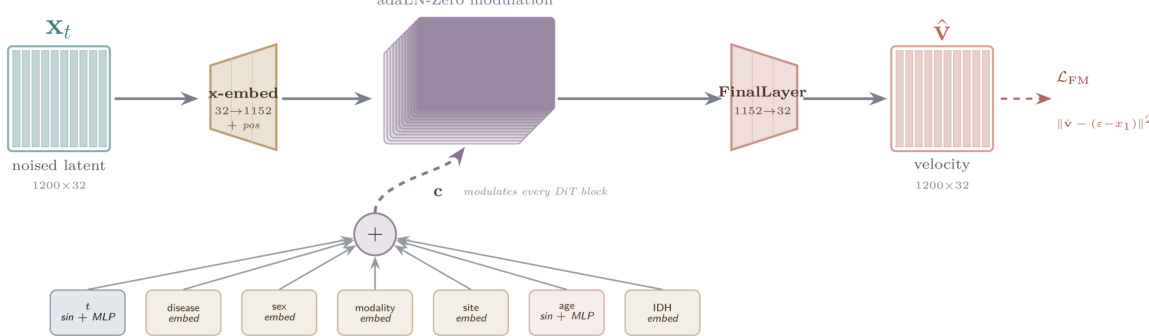
The DiT architecture takes a noised latent representation of size 1200×32 as input. This input is processed through an embedding layer that maps 32 dimensions to 1152 dimensions, adding positional encodings. The core of the DiT consists of blocks modulated by adaLN-Zero. The conditioning signal c is derived from a combination of multiple variables: time step t (processed via sin+MLP), disease embedding, sex embedding, modality embedding, site embedding, age (processed via sin+MLP), and IDH embedding. These embeddings are summed to form the conditioning vector that modulates every DiT block. Finally, a FinalLayer maps the 1152 dimensions back to 32 to predict the velocity v^. The model is trained using a flow matching loss defined as LFM=∥v−(ϵ−x1)∥2.
Experiment
The evaluation first validates on a tumor cohort that a low-dimensional projection preserves clinical information and that the frozen MAE-CNN tokenizer surpasses a CNN-VAE baseline in clinical probing while supporting scalability. Frozen linear probes on the large-scale encoder then outperform published brain-MRI foundation models across the majority of clinical and demographic tasks. Using the same embeddings, a conditional diffusion model demonstrates controllable generation along disease, sex, age, modality, and tumor mutation axes with good fidelity and no memorization, while a longitudinal variant forecasts patient-specific anatomical changes that localize to ventricles and sulci.
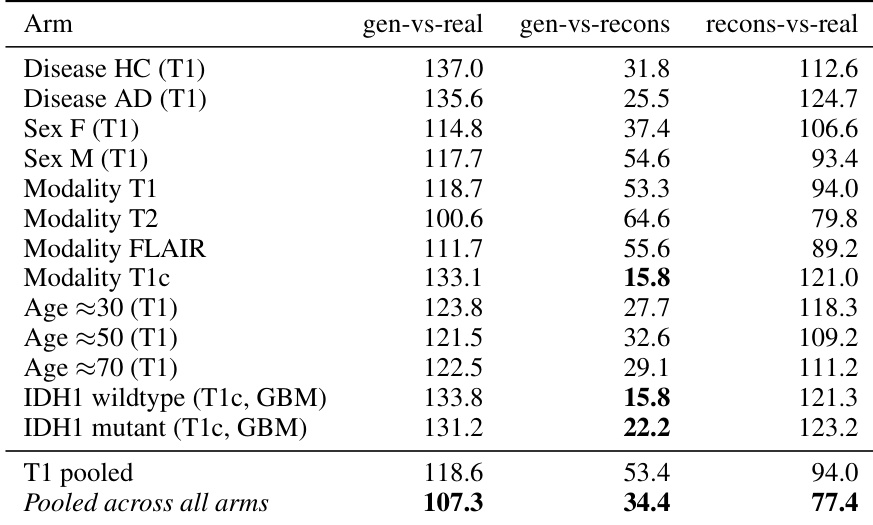
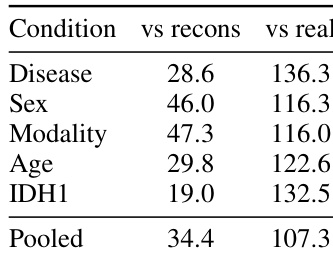
The authors evaluate generation fidelity using 3D-FID across various conditional arms, decomposing the error into generator-to-real, generator-to-reconstruction, and reconstruction-to-real components. Results show that the generator closely matches the tokenizer's latent distribution, with the pooled generator-to-reconstruction FID being substantially lower than the tokenizer's own reconstruction floor against real volumes. This indicates that the primary gap between generated samples and real volumes stems from the tokenizer's compression of high-frequency details rather than limitations in the generator itself. The generator closely matches the tokenizer's latent distribution, achieving a significantly lower FID against reconstructions than the tokenizer's own reconstruction floor against real volumes. Generation fidelity remains consistent across different conditioning arms, including disease states, sex, modality, age, and mutation status. Specific conditional arms, such as certain modalities and mutation statuses, show particularly low generator-to-reconstruction FIDs, indicating strong alignment with the tokenizer's latent space.
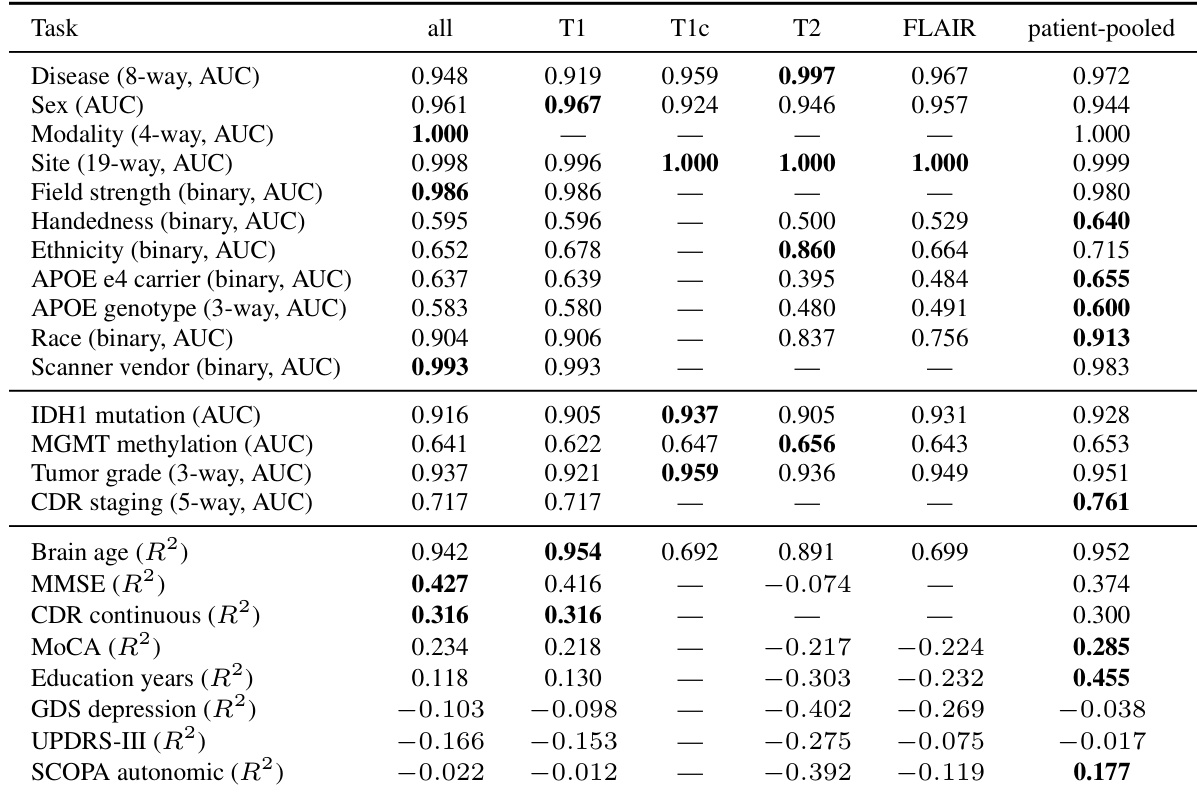
The authors evaluate the clinical content of their frozen encoder embeddings using linear probes across a comprehensive panel of classification and regression tasks on a large brain MRI corpus. Results indicate that the encoder captures strong signals for demographic, acquisition, and major disease-related variables, with performance varying by MRI modality. While classification tasks generally achieve high predictive accuracy, regression tasks show more variable performance, with some clinical scales proving difficult to predict across all modalities. Classification tasks including disease diagnosis, sex, and scanner vendor achieve high predictive performance, with the optimal MRI modality varying by task. Regression tasks demonstrate mixed results, with brain age prediction performing strongly while other clinical scales yield negative or near-zero scores across most modalities. Patient-pooled evaluations frequently yield the best performance for tasks where individual modality subsets lack sufficient samples or exhibit weaker predictive power.
The authors evaluate the generation fidelity of their conditional diffusion transformer by computing FID scores across various conditioning arms. Results show that the gap between generated samples and real volumes is primarily driven by the tokenizer's compression of high-frequency details rather than the generator's quality, as the generator matches the tokenizer's reconstructions more closely than the raw real volumes. The pooled FID score between generated samples and tokenizer reconstructions is substantially lower than the score against raw real volumes, indicating strong alignment with the latent space. Generation fidelity varies across conditions, with some conditions like IDH1 and Disease showing lower FID scores against reconstructions compared to others like Sex and Modality. The tokenizer's reconstruction floor against real volumes accounts for most of the discrepancy between generated samples and raw real data.
The authors evaluate the sensitivity of the conditional generation to the classifier-free guidance scale. Results show that lower guidance scales maintain strong recovery of disease, sex, and age attributes, whereas a higher scale degrades the continuous age prediction. The model struggles to steer toward the rare IDH1 mutant class across all tested guidance scales. Disease and sex attributes are reliably recovered across all tested guidance scales. Increasing the guidance scale too high causes the continuous age prediction to degrade due to over-extrapolation. IDH1 mutation status remains near chance agreement regardless of the guidance scale used.

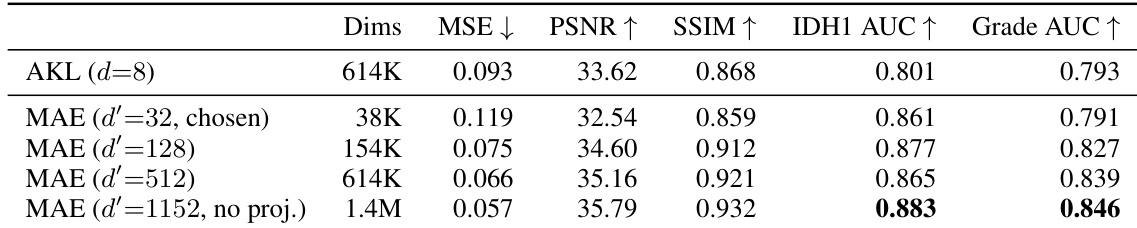
The authors compare a frozen MAE-CNN tokenizer against an AutoencoderKL baseline on a tumor cohort, evaluating reconstruction quality and clinical probing performance across different bottleneck dimensions. Results show that the MAE tokenizer consistently outperforms the baseline on clinical probing tasks, even when using a significantly smaller bottleneck dimension, leading the authors to select a small projection to balance dimensionality reduction with clinical content preservation. At matched dimensionality, the MAE tokenizer achieves higher clinical probing performance for both IDH1 and tumor grade compared to the AutoencoderKL baseline. The MAE tokenizer with a small bottleneck outperforms the much larger baseline on IDH1 classification and matches it on tumor grade. Reconstruction quality for the MAE tokenizer improves monotonically as the projection dimension increases, though clinical content remains well-preserved even at the smallest bottleneck.
The authors conduct a comprehensive evaluation spanning generation fidelity, representation quality, conditioning robustness, and tokenizer design. Decomposed 3D-FID scores demonstrate that the generator closely aligns with the tokenizer's latent space, and the primary gap between generated samples and real volumes arises from the tokenizer's compression of high-frequency details rather than generator limitations. Linear probing of frozen encoder embeddings confirms strong clinical signal capture for disease, demographics, and acquisition attributes in classification tasks, though regression performance is more variable. Guidance sensitivity analysis shows that sex and disease attributes are stably recovered across scales, while continuous age prediction degrades at high scales and rare IDH1 mutations remain near chance; a comparison of tokenizers establishes that the frozen MAE variant better preserves clinical information than an AutoencoderKL baseline even at a much smaller bottleneck dimension.