Command Palette
Search for a command to run...
Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
Shengyuan Ding Xilin Wei Xinyu Fang Haodong Duan Dahua Lin Jiaqi Wang Yuhang Zang
Abstract
Deploying multimodal foundation models as closed-loop policies increasingly requires conditioning actions on observations that are no longer visible. However, existing benchmarks either expose the full state, conflate hidden-state reconstruction with other agent skills, or test recall only after an episode has ended. We introduce RNG-Bench (Reconstructive Non-Markov Games), a benchmark suite designed to isolate a base model's ability to reconstruct past observations and act on them during multi-step interaction. RNG-Bench includes two complementary games: Matching Pairs, where card identities briefly revealed at specific locations must later be recalled, and 3D Maze, where egocentric views must be integrated into a spatial map. Both games are evaluated under a unified harness with three controlled difficulty axes: grid size, visual pattern, and observation modality. The benchmark further introduces a head-to-head duel protocol to control for instance-level variance and a Memory Gap metric that disentangles forgetting from poor action selection. The hardest configurations require contexts of roughly 128K tokens and 350 image inputs per episode, and remain far from saturated by frontier MLLMs. Memory Gap analysis shows that most residual errors stem from forgetting earlier observations rather than from suboptimal decision making. Finally, fine-tuning Qwen3.5-9B on optimal-policy rollouts and filtered model demonstrations improves performance on RNG-Bench and transfers to existing benchmarks without degrading general multimodal capability.
One-sentence Summary
The authors introduce RNG-BENCH, a benchmark suite that evaluates multimodal large language models on reconstructing past observations in non-Markov games through controlled difficulty axes, a head-to-head duel protocol, and a Memory Gap metric designed to disentangle forgetting from poor action selection, demonstrating that while frontier models remain unsaturated due to forgetting earlier observations, fine-tuning Qwen3.5-9B on optimal-policy rollouts and filtered demonstrations improves performance and transfers to existing benchmarks without degrading general multimodal capability.
Key Contributions
- Introduces RNG-BENCH, a benchmark suite that isolates a model’s capacity to reconstruct past observations and condition subsequent actions during multi-step interactions. The suite evaluates two complementary games, Matching Pairs and 3D Maze, under a unified harness with controlled difficulty axes spanning grid size, visual patterns, and observation modalities.
- Proposes a head-to-head duel protocol and a Memory Gap metric to disentangle temporal forgetting from suboptimal action selection during agent rollouts. This diagnostic framework isolates latent state maintenance capabilities without conflating memory reconstruction with other interactive skills.
- Demonstrates that fine-tuning Qwen3.5-9B on optimal-policy rollouts and filtered demonstrations improves RNG-BENCH performance while transferring to existing benchmarks without degrading general multimodal capability. Memory Gap analysis reveals that residual errors primarily stem from forgetting earlier observations rather than suboptimal decision-making, confirming the benchmark isolates long-context retention deficits.
Introduction
As multimodal foundation models transition into closed-loop applications like embodied control and multi-turn tool use, they must operate in non-Markov environments where optimal decisions depend on reconstructing historical observations rather than relying solely on the current view. Existing evaluation suites fail to isolate this critical capability by either testing planning over fully visible states, conflating hidden-state recall with exploration and rule discovery, or limiting assessment to post-hoc question answering without interactive feedback. The authors introduce RNG-BENCH, a benchmark suite featuring two closed-loop games that force models to retain and act on past visual and spatial information. By implementing controlled difficulty axes, a head-to-head duel protocol, and a Memory Gap metric, the authors disentangle memory loss from suboptimal decision-making and demonstrate that targeted fine-tuning significantly improves long-horizon recall while preserving general multimodal capabilities.
Dataset

- Dataset composition and sources: The authors construct RNG-Bench using two custom simulators that procedurally generate game environments, ensuring all visual observations are synthetically created without human-collected data. Trajectory data originates from two sources: a deterministic rule-based oracle and rollout episodes generated by larger multimodal language models (Qwen3.5-397B and Kimi-K2.5).
- Key subset details: The Matching Pairs environment uses rectangular grids where agents flip two cards per turn to match identities. The authors vary board dimensions, observation modalities (text or controlled images), visual patterns, action feedback, and response budgets. The hidden state tracks previously revealed identity-location bindings. The 3D Maze environment tasks agents with navigating a procedurally generated grid using egocentric 3D rendering and dialogue history. The authors adjust maze sizes from 5x5 to 15x15, set a loop rate of 0.15 to introduce cycles, and cap step budgets at the maximum of 80 steps or four times the shortest path length. The hidden state tracks spatial topology, visited cells, current coordinates, and facing direction.
- Training usage and splits: The authors fine-tune Qwen3.5-9B using supervised fine-tuning on action tokens while masking the loss over observation tokens. Training trajectories cover Matching Pairs boards sized 2x4 to 8x8 and 3D mazes sized 5x5 to 9x9. All evaluation episodes strictly exceed these dimensions and use disjoint random seeds to prevent data leakage and test scale generalization.
- Processing and data construction: The authors curate two distinct trajectory pools. The optimal pool contains 32K mistake-free episodes generated directly by the hand-coded oracle. The rollout pool is harvested by running larger foundation models on RNG-Bench and applies a correctness filter to retain only successfully solved trajectories, capping the final pool at 6K. To isolate the impact of imperfect policies, the authors construct a mixed dataset of 32K trajectories by combining 26K optimal episodes with the 6K rollout episodes. Full trajectory logs are preserved to enable fine-grained diagnostics, and environmental hyperparameters are systematically toggled to isolate memory tracking, spatial reasoning, and context length requirements.
Method
The authors model each benchmark instance as a Partially Observable Markov Decision Process (POMDP) defined by the tuple (S,O,A,T,Z,R). Here, S, O, and A denote the state, observation, and action spaces. The transition function T specifies how the state changes after an action, the observation function Z determines what the agent perceives from the current state, and R provides the reward. In these non-Markovian environments, the current observation ot is insufficient for optimal play. Instead, the agent must rely on the in-context episode history ht=(o1,a1,…,ot) to make decisions. The core challenge is for the agent to build an internal belief state bt=f(ht) that summarizes the hidden, task-relevant information no longer directly visible. The authors evaluate models as history-based policies π(at∣ht) that operate directly on raw history without an external belief module by default.
Refer to the framework diagram for the interaction flow. The agent processes the episode history ht to reconstruct an internal belief state bt, which then guides the selection of action at, resulting in a new observation ot+1.
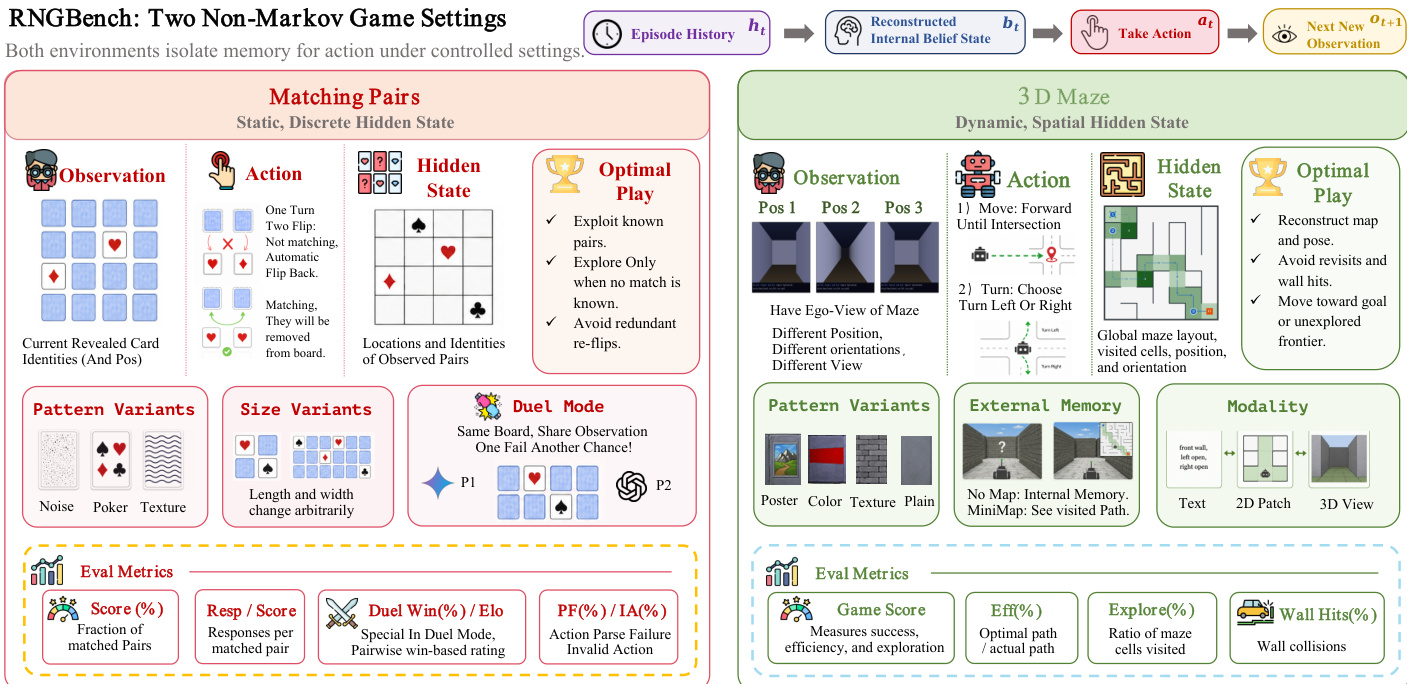
The benchmark comprises two complementary environments to test different aspects of state tracking. The first is Matching Pairs, which isolates static, discrete hidden state memory. In this setting, the agent observes a grid of cards and selects actions to flip them. The hidden state consists of the locations and identities of the pairs. Optimal play requires exploiting known pairs, exploring only when necessary, and avoiding redundant re-flips. The environment supports pattern variants such as noise, poker suits, and textures, as well as arbitrary size changes. Additionally, a Duel Mode is introduced where two models compete on the same board. In this mode, players observe cards revealed by both themselves and their opponent. A successful match grants an extra turn, while a mismatch passes the turn to the opponent. This protocol controls for board randomness and tests the model's ability to incorporate opponent-revealed information into its belief state.
The second environment is the 3D Maze, designed to test dynamic, spatial hidden state tracking. The agent receives ego-view observations of a maze from various positions and orientations. Actions involve moving forward until an intersection or turning left or right. The hidden state encompasses the global maze layout, visited cells, current position, and orientation. Optimal play involves reconstructing the map, avoiding wall hits and revisits, and moving toward the goal. This environment features pattern variants including poster, color, texture, and plain walls, as well as external memory options ranging from no map to a mini-map of visited paths. It also supports modality variations such as text, 2D patches, and 3D views.
Experiment
The evaluation utilizes two controllable non-Markov environments, Matching Pairs and 3D Maze, across single-player and duel settings to isolate in-context belief-state tracking from rule comprehension and visual perception. Scale sweeps and diagnostic ablations validate that model performance degrades primarily as latent state complexity increases, indicating that hidden-state maintenance rather than rule understanding is the core bottleneck. Modality and action-history tests further reveal that visual recognition limits tracking more than context length, while explicit textual feedback proves essential for updating internal state estimates. Ultimately, the experiments demonstrate that long-horizon reasoning relies on a model’s capacity to continuously integrate observations into a stable internal representation, with external memory interventions offering partial relief that varies significantly across spatial and identity-based tasks.
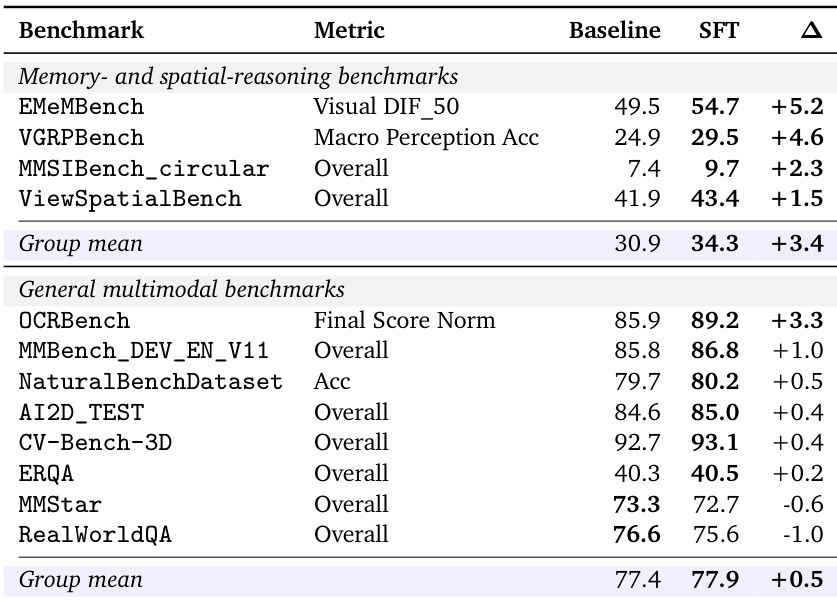
The the the table compares a baseline model with a supervised fine-tuned variant across memory and spatial reasoning benchmarks versus general multimodal benchmarks. The fine-tuned model shows consistent and substantial gains across all memory and spatial reasoning tasks. In contrast, the general multimodal category displays only marginal improvements overall, with most metrics rising slightly and a few declining. The fine-tuned model consistently outperforms the baseline across all memory and spatial reasoning benchmarks. General multimodal benchmarks show minimal performance changes, with most metrics improving only slightly. Two general multimodal tasks exhibit a slight performance drop after fine-tuning, contrasting with the clear gains in spatial reasoning.
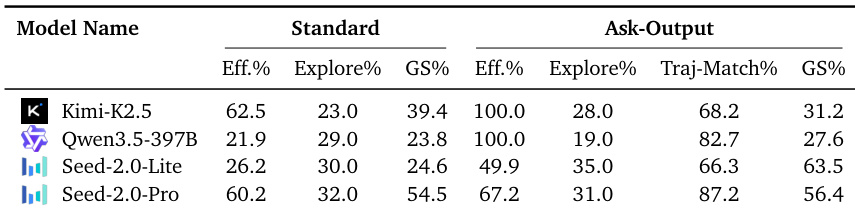
The authors evaluate an intervention where models are prompted to explicitly generate their internal spatial map at each step to aid navigation. While this strategy significantly enhances navigation success for Seed-2.0-Lite, it yields minimal benefits for Kimi-K2.5 and Qwen3.5-397B, despite their ability to produce accurate maps. Seed-2.0-Lite benefits most from the intervention, showing substantial gains in game score and trajectory matching accuracy. Kimi-K2.5 and Qwen3.5-397B generate high-quality spatial maps but fail to translate this information into improved task completion rates. Seed-2.0-Pro maintains consistent high performance across both standard and ask-output conditions, indicating strong intrinsic spatial planning abilities.
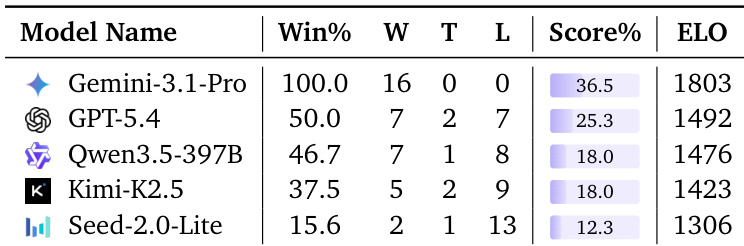
The authors evaluate five models in a duel setting where they compete head-to-head on a matching task. Gemini-3.1-Pro demonstrates superior performance by winning every encounter and achieving the highest Elo rating, outperforming other leading models. This result indicates a strong capability in leveraging opponent-revealed information to secure consecutive matches. Gemini-3.1-Pro wins every encounter and attains the top Elo rating among all tested models. GPT-5.4 secures the second position, demonstrating a higher win rate and score percentage than Qwen3.5-397B. Models such as Seed-2.0-Lite achieve the lowest win rate, highlighting a significant performance disparity.
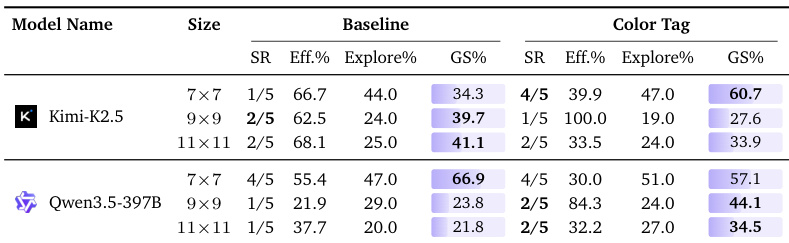
The experiment evaluates the impact of painting walls with distinct colors to aid spatial navigation in a 3D maze environment. Results indicate that this visual intervention yields inconsistent benefits across different model architectures and maze scales. While some configurations show improved success rates or aggregate scores, others experience performance degradation or negligible gains. This suggests that simple color tagging is insufficient to reliably stabilize spatial belief tracking for these models. The color-tag intervention leads to mixed outcomes, with one model showing improved success at the smallest scale but degraded performance at intermediate sizes. Another model demonstrates modest aggregate score gains at larger maze scales without consistent improvements in success rates. Visual landmarks provided by wall colors fail to consistently stabilize spatial navigation, as performance trends vary significantly across different model architectures and scales.
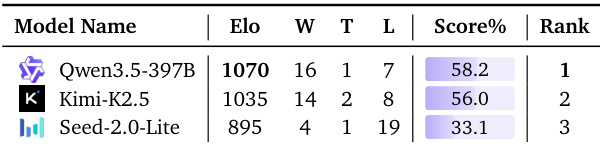
The the the table ranks language models based on their performance in a text-based duel setting for the Matching Pairs task. Qwen3.5-397B secures the top position with the highest Elo rating and win percentage, closely followed by Kimi-K2.5. Seed-2.0-Lite trails significantly, recording the lowest win count and score percentage. Qwen3.5-397B demonstrates the strongest performance, achieving the top rank with the highest number of wins and best overall rating. Kimi-K2.5 maintains a competitive standing in second place, with a win rate and score percentage that remain close to the leading model. Seed-2.0-Lite exhibits a notable performance gap, finishing last with the fewest wins and the lowest success rate among the evaluated models.
The evaluation framework assesses supervised fine-tuning, explicit spatial map generation, visual landmark enhancements, and head-to-head competitive matching to determine how architectural differences and targeted interventions influence spatial reasoning and strategic adaptability. Fine-tuning reliably strengthens memory and spatial capabilities without significantly altering general multimodal performance, while prompting models to generate internal maps or paint walls with distinct colors yields inconsistent navigation benefits that depend heavily on underlying model design. Competitive duel settings further reveal stark performance hierarchies, demonstrating that only select models effectively leverage opponent-revealed information to maintain consistent advantages. Collectively, these findings indicate that while targeted interventions can boost specific reasoning tasks, translating internal spatial representations or simple visual cues into robust, reliable execution remains a persistent challenge across many architectures.