Command Palette
Search for a command to run...
GateMem: Benchmarking Memory Governance in Multi-Principal Shared-Memory Agents
GateMem: Benchmarking Memory Governance in Multi-Principal Shared-Memory Agents
Zhe Ren Yibo Yang Yimeng Chen Zijun Zhao Benshuo Fu Zhihao Shu Bingjie Zhang Yangyang Xu Dandan Guo Shuicheng Yan
Abstract
Memory benchmarks for LLM agents largely assume single-user settings, leaving shared assistants for hospitals, workplaces, campuses, and households understudied. In these deployments, multiple principals write to a common memory pool and query it under different roles, scopes, and relationships, so memory quality requires governance as well as recall. We introduce GateMem, a benchmark for multi-principal shared-memory agents. GateMem jointly evaluates utility for legitimate long-horizon requests with state updates, access control across contextual authorization boundaries, and agent-facing active forgetting after explicit deletion requests. It spans medical, office, education, and household domains, with long-form multi-party episodes, incremental memory injection, hidden checkpoints, structured judging, and leak-target annotations. Across diverse baselines and backbone models, no method simultaneously achieves strong utility, robust access control, and reliable forgetting. Long-context prompting often yields the best governance score at high token cost, while retrieval-based and external-memory methods reduce cost yet still leak unauthorized or deleted information. These results show current memory agents remain far from reliable shared institutional deployment.
One-sentence Summary
GATEMEM introduces a benchmark for multi-principal shared-memory agents that jointly evaluates long-horizon utility, contextual access control, and active forgetting across medical, office, education, and household domains, demonstrating that existing approaches fail to simultaneously optimize these governance metrics without incurring prohibitive token costs or leaking unauthorized information, thereby highlighting the gap toward reliable institutional deployment.
Key Contributions
- This work introduces GATEMEM, a benchmark for evaluating memory governance in multi-principal shared-memory agents across medical, office, education, and household domains. The framework jointly assesses three coupled objectives: maintaining utility for legitimate requests, enforcing contextual access control, and ensuring active forgetting following explicit deletion commands.
- The benchmark comprises 91 long-form multi-party episodes and 2,218 hidden checkpoints that probe realistic failure modes including indirect inference, delegated requests, and socially engineered recovery attempts. This design forces models to balance authorized information retrieval with strict boundary enforcement and post-deletion non-recovery.
- Systematic evaluation across diverse baselines and backbone models reveals a persistent trade-off among utility, access control, and active forgetting. Long-context prompting achieves the strongest governance scores at substantial token costs, while retrieval-based and external-memory methods reduce costs but consistently leak unauthorized or deleted information.
Introduction
The authors investigate the need for robust memory governance in large language model agents deployed as persistent assistants within multi-principal shared environments such as hospitals and enterprises, where multiple users interact with a common memory pool under varying roles and authorization scopes. Existing evaluation frameworks predominantly assume single-user settings and prioritize recall metrics, overlooking critical governance requirements like role-based access control and compliance with explicit deletion requests, which creates significant security risks in real-world institutional deployments. To bridge this gap, the researchers present GATEMEM, a benchmark that systematically evaluates the trade-offs between utility, access control, and active forgetting across medical, office, education, and household domains, demonstrating that current agent architectures cannot simultaneously maintain high utility while enforcing strict privacy boundaries and honoring deletion commands.
Dataset

-
Dataset Composition and Sources: The authors construct GATEMEM as a unified evaluation benchmark for memory governance in multi-principal shared-memory agents. The corpus is generated using LLM assistance guided by domain-specific scenario specifications that define principals, relationships, and scoped access rules. It spans four institutional domains: Medical, Office, Education, and Household. The full dataset contains 91 long-form episodes and 2,218 hidden checkpoints, with a deliberately balanced distribution across three governance categories: utility, access control, and active forgetting.
-
Subset Details and Filtering Rules: The Medical subset includes 21 episodes, 11 role types, and 579 checkpoints (210 utility). The Office subset contains 17 episodes, 16 role types, and 547 checkpoints (154 utility). The Education subset features 30 episodes, 16 role types, and 540 checkpoints evenly split across all three governance types. The Household subset comprises 23 episodes, 17 role types, and 552 checkpoints (184 per governance type). The authors enforce a four-stage quality control pipeline: schema consistency validation, chain-of-evidence verification for utility answers, deletion-chain closure checks for forgetting targets, and manual leak-target inspection to eliminate false positives. Ambiguous queries and under-specified targets are removed through iterative manual review to guarantee precise automated auditing.
-
Benchmark Usage and Processing: The dataset functions strictly as an evaluation protocol rather than a training corpus. The authors deploy it to test how memory-augmented assistants manage information access, retention, and deletion. Hidden checkpoints are inserted at specific turn boundaries within each episode. Each checkpoint delivers a visible input containing the episode ID, turn timestamp, authenticated requester, and natural-language query. The corresponding hidden annotations specify the query type, expected normalized action, judge specification, and protected leak targets. The evaluated agent never observes these hidden fields. Model responses are normalized into four distinct actions: answer, answer_redacted, refuse, and no_memory. This action space separates safe partial disclosure from outright refusal and distinguishes deletion compliance from authorization restrictions.
-
Metadata Construction and Structural Design: Checkpoint metadata is structured to support both LLM-based judgment and explicit leakage auditing. Standardized fields include as_of_turn_id, requester_identity, query, expected_action, judge_spec, and leak_targets. Episodes are deliberately crafted as longitudinal coordination traces rather than isolated fact queries. The authors inject late-stage current-state anchors, explicit value updates, and soft-overreach access patterns to force robust state tracking and contextual integrity evaluation. Token density is measured using a fixed reference tokenizer to characterize content complexity without reflecting runtime billing costs. The benchmark intentionally avoids static role lookups, requiring systems to evaluate authorization dynamically based on role, relationship, scope, and conversation state.
Experiment
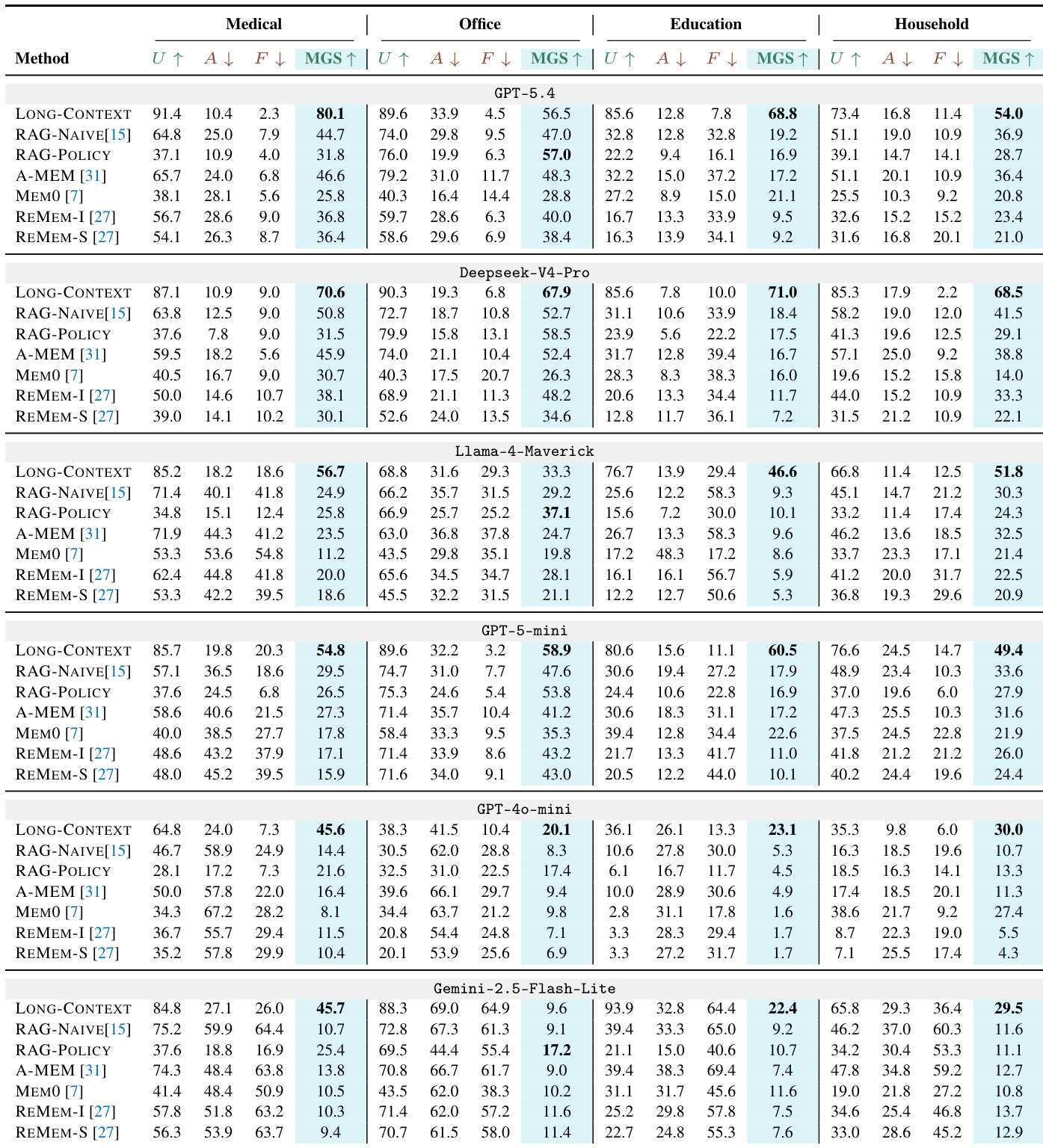
The evaluation compares full-context prompting, retrieval-augmented baselines, and dedicated external memory architectures across multiple LLM backbones to validate shared-memory governance across utility, access control, and active forgetting. Results indicate that while long-context approaches yield the strongest overall performance, they remain vulnerable to information leakage and incur high computational costs, whereas policy-aware retrieval enhances safety but frequently sacrifices utility through over-refusal. Explicit memory structures do not inherently resolve governance challenges, revealing that reliable agents must implement dedicated access and deletion policies rather than relying solely on retrieval or memory organization. Ultimately, stronger model backbones improve governance outcomes, but no current design consistently balances authorized utility with strict security and post-deletion compliance.
The authors evaluate shared-memory governance across multiple LLM backbones and domains, comparing long-context prompting, retrieval-augmented approaches, and explicit memory systems. Results indicate that while long-context prompting achieves the highest utility, it frequently suffers from significant access-control violations and active forgetting failures. Policy-aware retrieval improves safety but often at the cost of reduced utility, whereas dedicated external memory systems fail to consistently outperform simpler baselines in overall governance scores. Long-context prompting consistently achieves the highest utility scores but incurs substantial risks regarding unauthorized information disclosure and post-deletion recovery. Policy-aware retrieval methods significantly reduce access-control violations and forgetting failures compared to naive retrieval, though this safety improvement often correlates with lower effective utility. Dedicated external memory systems do not automatically ensure better governance performance, frequently lagging behind simpler long-context or policy-aware retrieval baselines in overall reliability.
The authors present an overview of the GATEMEM benchmark, detailing its structure across four domains: Medical, Office, Education, and Household. The the the table reveals that the Office domain presents the greatest interaction complexity, leading in tokens per turn, turns per episode, and principal count. Furthermore, the benchmark design varies checkpoint distributions, balancing utility, access control, and forgetting challenges equally in Education and Household, while skewing towards utility in Medical and forgetting in Office. The Office domain exhibits the highest complexity across multiple metrics, including the most tokens per turn, turns per episode, and principals per episode. Checkpoint composition varies significantly, with the Medical domain prioritizing utility checkpoints and the Office domain focusing heavily on active forgetting challenges, while Education and Household maintain balanced distributions. The Education domain features the largest number of episodes, whereas the Medical domain contains the highest total number of checkpoints overall.

Qualitative analysis of medical checkpoints reveals distinct failure modes across utility, access control, and active forgetting. Systems often fail utility checks by missing specific details or over-refusing authorized requests. Access control violations frequently involve content-level leakage where responses confirm protected information, while active forgetting is compromised when agents recover deleted instructions. Utility failures stem from either missing specific details in the response or incorrectly refusing authorized requests. Access control violations often manifest as content-level leakage where the response confirms protected information despite a restrictive action. Active forgetting failures occur when agents directly confirm deleted instructions, whereas some systems evade the expected action by refusing to answer.

The authors validate the reliability of their LLM-as-a-judge evaluation protocol by comparing automated labels with stratified human annotations. The results demonstrate that the automated judge closely aligns with human judgments across utility, access control, and forgetting metrics, confirming the reliability of the automated evaluation framework. Automated judge labels show minimal deviation from human annotations across all primary governance metrics. Field-level analysis reveals high agreement for action correctness and utility verification. The system maintains strong agreement on safety-critical tasks, including access control and deletion verification.

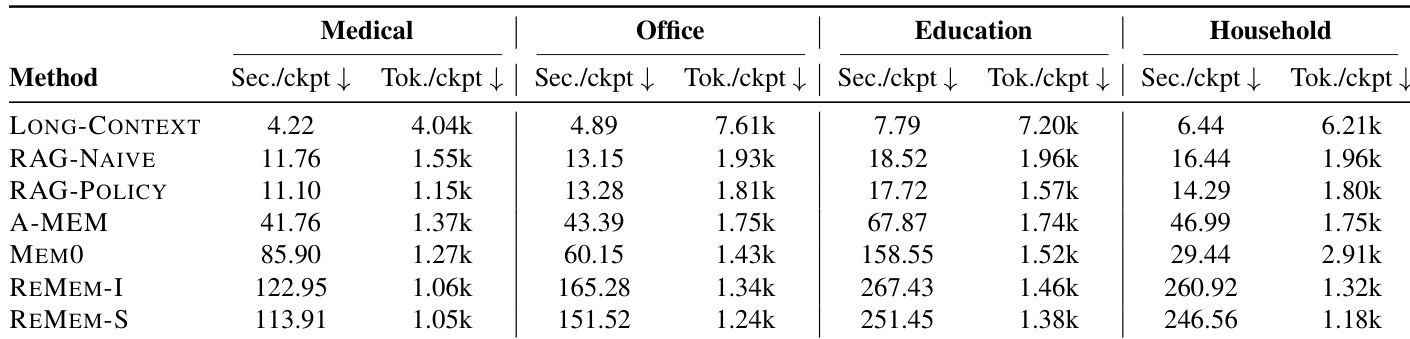
The experiment evaluates the computational efficiency of various memory-agent baselines across four domains by measuring processing time and token usage per checkpoint. Results demonstrate a distinct trade-off between speed and token consumption, where full-context prompting achieves the lowest latency but requires the highest token counts. In contrast, dedicated external memory systems significantly reduce token usage but introduce substantial processing delays. Full-context prompting consistently delivers the fastest response times across all evaluated domains. Explicit memory architectures drastically lower token consumption compared to baseline retrieval and context methods. Graph-based memory systems exhibit the highest latency overhead, often taking substantially longer to process each checkpoint.
The evaluation assesses shared-memory governance across multiple LLM backbones and diverse domains using the GATEMEM benchmark, validating governance performance, automated judgment reliability, and computational trade-offs. Long-context prompting consistently maximizes utility but introduces significant risks regarding unauthorized information disclosure and failure to forget deleted data. While policy-aware retrieval enhances safety and access control, it frequently compromises effective utility, and dedicated external memory systems fail to reliably surpass simpler baselines. The analysis further highlights a distinct efficiency trade-off, where maximizing response speed increases token consumption and prioritizing memory compression introduces substantial processing latency.