Command Palette
Search for a command to run...
Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Jingyuan Huang Zuming Huang Yucheng Shi Tianze Yang Xiaoming Zhai Wei Chu Ninghao Liu
Abstract
Graphical user interface (GUI) grounding requires vision-language models (VLMs) to identify small target elements in high-resolution screenshots and predict precise screen coordinates. On-policy self-distillation (OPSD) is a promising post-training approach for this coordinate-sensitive task, since it provides dense token-level teacher signals beyond hard coordinate labels. However, naive OPSD is not well suited to GUI grounding: OPSD evaluates the teacher on student-generated prefixes, the quality of coordinate-token teacher signals can degrade when the prefix has already deviated from the target coordinate, leading to unreliable teacher signal. To mitigate this, We propose quality-aware self-distillation for VLM-based GUI grounding, which improves coordinate-token teacher-signal quality through soft correctness-aware gating and teacher-probability scaling. The soft correctness-aware gate checks whether the teacher's current coordinate-token prediction can still be completed into the ground-truth box under the student-generated prefix. If not, the corresponding teacher signal is down-weighted. Teacher-probability scaling then uses the teacher's confidence as a lightweight factor to further calibrate the strength of the gated supervision. A key empirical finding is that neither component alone improves overall performance, whereas combining them consistently improves performance. This suggests that the two mechanisms play complementary roles: correctness-aware gating suppresses unreliable coordinate-token supervision, while teacher-probability scaling calibrates the strength of the remaining signals. Experiments across six GUI grounding benchmarks show that our method consistently improves the base model and outperforms strong baselines.
One-sentence Summary
The authors propose a quality-aware self-distillation method for vision-language model-based GUI grounding that replaces naive on-policy self-distillation with soft correctness-aware gating and teacher-probability scaling to dynamically down-weight unreliable coordinate-token teacher signals, thereby improving precise element localization in high-resolution screenshots.
Key Contributions
- This work introduces a quality-aware self-distillation framework for vision-language models in graphical user interface (GUI) grounding to stabilize coordinate-sensitive training when on-policy prefixes diverge from target regions.
- A soft correctness-aware gating mechanism evaluates spatial verifiability by checking whether teacher coordinate predictions can still complete into the ground-truth bounding box under student-generated prefixes, automatically down-weighting unreliable signals.
- Teacher-probability scaling operates as a lightweight calibration factor that dynamically adjusts gated supervision strength, establishing a direct training-time reliability criterion that leverages spatial verification instead of relying on indirect proxies such as entropy or perplexity.
Dataset

- Dataset composition and sources: The authors construct a dual-prompt dataset for GUI instruction tasks, pairing original user queries with corresponding interface screenshots.
- Subset details: Student prompts contain the raw GUI image alongside the original instruction or query. Teacher prompts mirror this structure but append a privileged hint to direct model attention.
- Data usage and processing: The paper uses these templates to structure model inputs. The authors deploy student prompts for baseline task execution and teacher prompts to deliver guided assistance during training or inference.
- Cropping and metadata strategy: The teacher hints explicitly note that the correct answer is located within a green rectangle. This indicates a region-based processing approach where the authors isolate or crop the relevant interface area using spatial metadata before feeding it to the model.
Experiment
Evaluated across six GUI grounding benchmarks using a Qwen3.5-9B backbone, the experimental pipeline validates a quality-aware self-distillation framework by systematically testing its core calibration mechanisms against established training paradigms. Main comparative trials demonstrate that the proposed method consistently surpasses supervised fine-tuning, reinforcement learning, and prior self-distillation approaches, while component analyses confirm that soft correctness-aware gating and teacher-probability scaling function as complementary filters that suppress inconsistent supervision and preserve valuable corrective feedback. Further sensitivity analyses reveal that carefully balancing coarse reliability gating with fine-grained probability weighting and coordinate-token strength optimizes cross-benchmark generalization. Ultimately, the results establish spatial verifiability and dynamic signal calibration as robust strategies for mitigating exposure bias and enhancing autoregressive coordinate prediction.
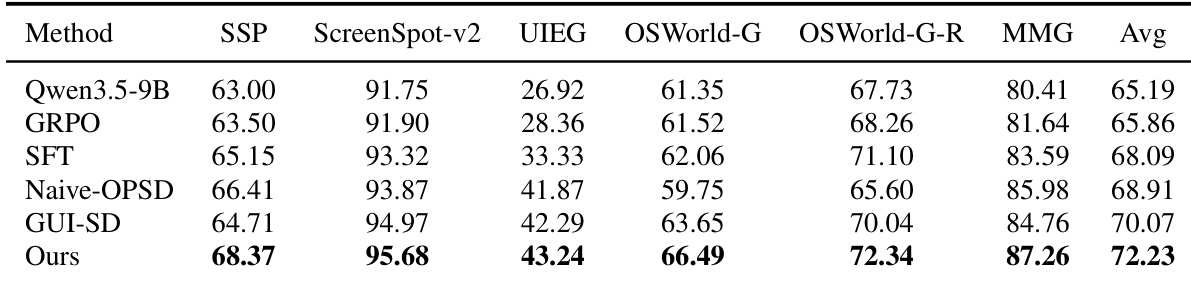
The proposed method, integrating soft correctness-aware gating and teacher-probability scaling, achieves the best macro-average accuracy across all evaluated GUI grounding benchmarks. While applying either component individually fails to provide consistent improvements over the baseline, their combination effectively calibrates teacher signals to enhance overall performance. The combined method achieves the highest average accuracy across all benchmarks. Individual components (gating or scaling alone) do not improve performance over the baseline. The proposed method outperforms the baseline on every single benchmark listed.

The authors evaluate their proposed quality-aware self-distillation method against several baselines, including GUI-SD and SFT, across six GUI grounding benchmarks. The results indicate that their method consistently achieves the highest performance on all individual datasets and the overall average macro-accuracy. This demonstrates that calibrating teacher signal reliability through soft gating and probability scaling effectively improves upon existing training strategies. The proposed method achieves the best performance across all six evaluated benchmarks, surpassing the strongest baseline, GUI-SD. The approach outperforms standard supervised fine-tuning and reinforcement learning baselines, highlighting the benefits of dense token-level supervision. Combining soft correctness-aware gating with teacher-probability scaling yields superior results compared to using either component in isolation.
The authors investigate the effect of gating strength on teacher-signal calibration for GUI grounding. The soft correctness-aware gating method achieves the highest macro-average accuracy, outperforming both the scaling-only baseline and the hard gating variant. This suggests that soft gating provides a more effective compromise by down-weighting unreliable signals rather than discarding them completely. Soft correctness-aware gating achieves the best overall performance compared to hard gating and scaling-only baselines. The method consistently outperforms the teacher-probability scaling approach across the evaluated benchmarks. Soft gating proves more effective than hard gating by preserving corrective information while filtering unreliable signals.

The authors investigate the impact of the scaling coefficient on model performance across multiple benchmarks. The results indicate that increasing the coefficient initially boosts the macro-average accuracy, with the proposed setting achieving the highest overall score. However, further increasing the coefficient leads to a decrease in the average performance, suggesting that an overly strong coefficient can harm general grounding capabilities. The proposed configuration achieves the highest macro-average accuracy compared to other tested coefficient values. While a higher coefficient improves performance on specific datasets, it reduces the overall average score across all benchmarks. The selected coefficient value offers the best trade-off, balancing effective supervision with robust general performance.

The authors investigate the effect of teacher-probability scaling within their self-distillation framework, which already employs soft correctness-aware gating and a fixed scaling coefficient. Experimental results show that introducing probability scaling yields consistent improvements across all six GUI grounding benchmarks relative to the fixed scaling configuration. The proposed method with probability scaling outperforms the fixed scaling baseline on every individual benchmark. It achieves the best macro-average accuracy, indicating strong overall performance. Teacher-probability scaling allows for finer calibration of teacher signals, enhancing the quality of supervision.

Evaluated across six GUI grounding benchmarks against standard supervised fine-tuning and reinforcement learning baselines, the proposed quality-aware self-distillation method consistently achieves superior performance when soft correctness-aware gating and teacher-probability scaling are combined. Individual ablation studies reveal that neither component alone improves upon the baseline, while soft gating outperforms hard alternatives by down-weighting unreliable signals rather than discarding them. Further tuning demonstrates that the selected scaling coefficient optimally balances supervision intensity with generalization, and dynamic probability scaling consistently outperforms fixed configurations. Collectively, these results confirm that carefully calibrating teacher signal reliability significantly enhances dense token-level supervision for robust GUI grounding.